 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRetHTR: Linear-Time Decoder-Only Retentive Network for Handwritten Text Recognition
Feb 19, 2026State-of-the-art handwritten text recognition (HTR) systems commonly use Transformers, whose growing key-value (KV) cache makes decoding slow and memory-intensive. We introduce DRetHTR, a decoder-only model built on Retentive Networks (RetNet). Compared to an equally sized decoder-only Transformer baseline, DRetHTR delivers 1.6-1.9x faster inference with 38-42% less memory usage, without loss of accuracy. By replacing softmax attention with softmax-free retention and injecting multi-scale sequential priors, DRetHTR avoids a growing KV cache: decoding is linear in output length in both time and memory. To recover the local-to-global inductive bias of attention, we propose layer-wise gamma scaling, which progressively enlarges the effective retention horizon in deeper layers. This encourages early layers to model short-range dependencies and later layers to capture broader context, mitigating the flexibility gap introduced by removing softmax. Consequently, DRetHTR achieves best reported test character error rates of 2.26% (IAM-A, en), 1.81% (RIMES, fr), and 3.46% (Bentham, en), and is competitive on READ-2016 (de) with 4.21%. This demonstrates that decoder-only RetNet enables Transformer-level HTR accuracy with substantially improved decoding speed and memory efficiency.
Zero-Shot Paragraph-level Handwriting Imitation with Latent Diffusion Models
Sep 01, 2024



The imitation of cursive handwriting is mainly limited to generating handwritten words or lines. Multiple synthetic outputs must be stitched together to create paragraphs or whole pages, whereby consistency and layout information are lost. To close this gap, we propose a method for imitating handwriting at the paragraph level that also works for unseen writing styles. Therefore, we introduce a modified latent diffusion model that enriches the encoder-decoder mechanism with specialized loss functions that explicitly preserve the style and content. We enhance the attention mechanism of the diffusion model with adaptive 2D positional encoding and the conditioning mechanism to work with two modalities simultaneously: a style image and the target text. This significantly improves the realism of the generated handwriting. Our approach sets a new benchmark in our comprehensive evaluation. It outperforms all existing imitation methods at both line and paragraph levels, considering combined style and content preservation.
A Fair Evaluation of Various Deep Learning-Based Document Image Binarization Approaches
Jan 22, 2024Binarization of document images is an important pre-processing step in the field of document analysis. Traditional image binarization techniques usually rely on histograms or local statistics to identify a valid threshold to differentiate between different aspects of the image. Deep learning techniques are able to generate binarized versions of the images by learning context-dependent features that are less error-prone to degradation typically occurring in document images. In recent years, many deep learning-based methods have been developed for document binarization. But which one to choose? There have been no studies that compare these methods rigorously. Therefore, this work focuses on the evaluation of different deep learning-based methods under the same evaluation protocol. We evaluate them on different Document Image Binarization Contest (DIBCO) datasets and obtain very heterogeneous results. We show that the DE-GAN model was able to perform better compared to other models when evaluated on the DIBCO2013 dataset while DP-LinkNet performed best on the DIBCO2017 dataset. The 2-StageGAN performed best on the DIBCO2018 dataset while SauvolaNet outperformed the others on the DIBCO2019 challenge. Finally, we make the code, all models and evaluation publicly available (https://github.com/RichSu95/Document_Binarization_Collection) to ensure reproducibility and simplify future binarization evaluations.
* DAS 2022
Combining OCR Models for Reading Early Modern Printed Books
May 11, 2023In this paper, we investigate the usage of fine-grained font recognition on OCR for books printed from the 15th to the 18th century. We used a newly created dataset for OCR of early printed books for which fonts are labeled with bounding boxes. We know not only the font group used for each character, but the locations of font changes as well. In books of this period, we frequently find font group changes mid-line or even mid-word that indicate changes in language. We consider 8 different font groups present in our corpus and investigate 13 different subsets: the whole dataset and text lines with a single font, multiple fonts, Roman fonts, Gothic fonts, and each of the considered fonts, respectively. We show that OCR performance is strongly impacted by font style and that selecting fine-tuned models with font group recognition has a very positive impact on the results. Moreover, we developed a system using local font group recognition in order to combine the output of multiple font recognition models, and show that while slower, this approach performs better not only on text lines composed of multiple fonts but on the ones containing a single font only as well.
WordStylist: Styled Verbatim Handwritten Text Generation with Latent Diffusion Models
Mar 29, 2023
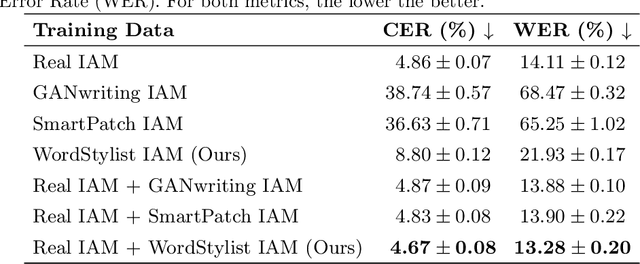
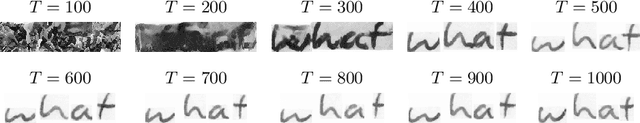

Text-to-Image synthesis is the task of generating an image according to a specific text description. Generative Adversarial Networks have been considered the standard method for image synthesis virtually since their introduction; today, Denoising Diffusion Probabilistic Models are recently setting a new baseline, with remarkable results in Text-to-Image synthesis, among other fields. Aside its usefulness per se, it can also be particularly relevant as a tool for data augmentation to aid training models for other document image processing tasks. In this work, we present a latent diffusion-based method for styled text-to-text-content-image generation on word-level. Our proposed method manages to generate realistic word image samples from different writer styles, by using class index styles and text content prompts without the need of adversarial training, writer recognition, or text recognition. We gauge system performance with Frechet Inception Distance, writer recognition accuracy, and writer retrieval. We show that the proposed model produces samples that are aesthetically pleasing, help boosting text recognition performance, and gets similar writer retrieval score as real data.
Writer Retrieval and Writer Identification in Greek Papyri
Dec 15, 2022The analysis of digitized historical manuscripts is typically addressed by paleographic experts. Writer identification refers to the classification of known writers while writer retrieval seeks to find the writer by means of image similarity in a dataset of images. While automatic writer identification/retrieval methods already provide promising results for many historical document types, papyri data is very challenging due to the fiber structures and severe artifacts. Thus, an important step for an improved writer identification is the preprocessing and feature sampling process. We investigate several methods and show that a good binarization is key to an improved writer identification in papyri writings. We focus mainly on writer retrieval using unsupervised feature methods based on traditional or self-supervised-based methods. It is, however, also comparable to the state of the art supervised deep learning-based method in the case of writer classification/re-identification.
TorMentor: Deterministic dynamic-path, data augmentations with fractals
Apr 07, 2022
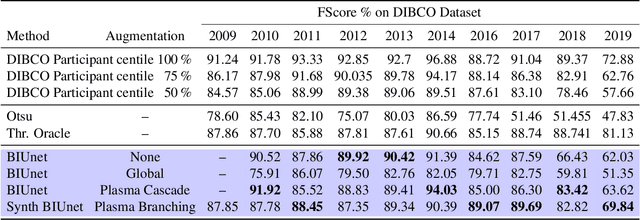

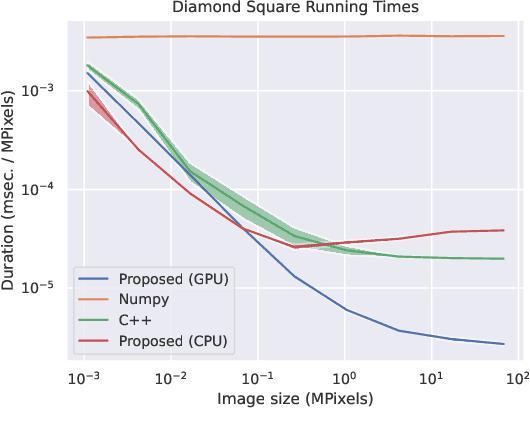
We propose the use of fractals as a means of efficient data augmentation. Specifically, we employ plasma fractals for adapting global image augmentation transformations into continuous local transforms. We formulate the diamond square algorithm as a cascade of simple convolution operations allowing efficient computation of plasma fractals on the GPU. We present the TorMentor image augmentation framework that is totally modular and deterministic across images and point-clouds. All image augmentation operations can be combined through pipelining and random branching to form flow networks of arbitrary width and depth. We demonstrate the efficiency of the proposed approach with experiments on document image segmentation (binarization) with the DIBCO datasets. The proposed approach demonstrates superior performance to traditional image augmentation techniques. Finally, we use extended synthetic binary text images in a self-supervision regiment and outperform the same model when trained with limited data and simple extensions.
A Survey of Historical Document Image Datasets
Mar 16, 2022
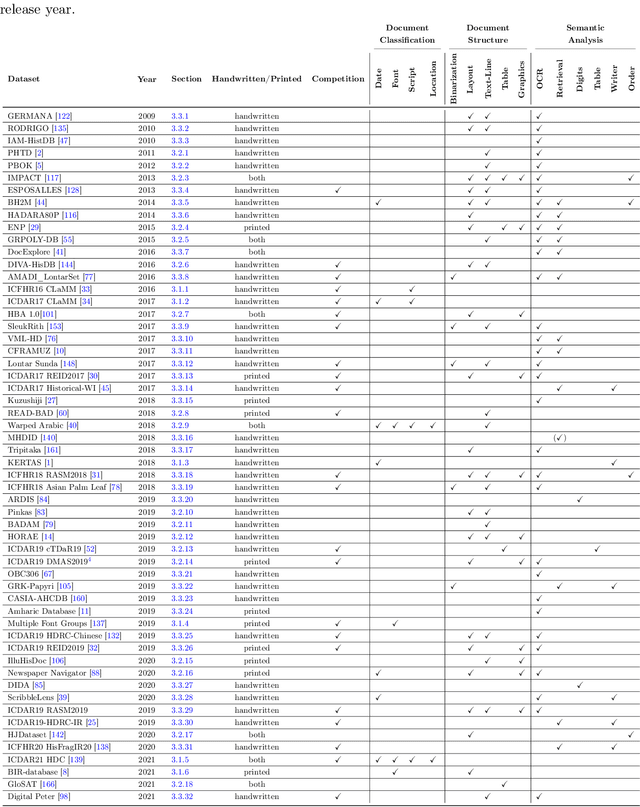
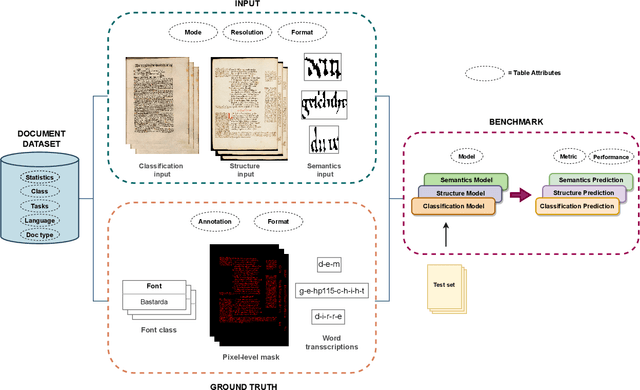
This paper presents a systematic literature review of image datasets for document image analysis, focusing on historical documents, such as handwritten manuscripts and early prints. Finding appropriate datasets for historical document analysis is a crucial prerequisite to facilitate research using different machine learning algorithms. However, because of the very large variety of the actual data (e.g., scripts, tasks, dates, support systems, and amount of deterioration), the different formats for data and label representation, and the different evaluation processes and benchmarks, finding appropriate datasets is a difficult task. This work fills this gap, presenting a meta-study on existing datasets. After a systematic selection process (according to PRISMA guidelines), we select 56 studies that are chosen based on different factors, such as the year of publication, number of methods implemented in the article, reliability of the chosen algorithms, dataset size, and journal outlet. We summarize each study by assigning it to one of three pre-defined tasks: document classification, layout structure, or semantic analysis. We present the statistics, document type, language, tasks, input visual aspects, and ground truth information for every dataset. In addition, we provide the benchmark tasks and results from these papers or recent competitions. We further discuss gaps and challenges in this domain. We advocate for providing conversion tools to common formats (e.g., COCO format for computer vision tasks) and always providing a set of evaluation metrics, instead of just one, to make results comparable across studies.
SmartPatch: Improving Handwritten Word Imitation with Patch Discriminators
May 21, 2021
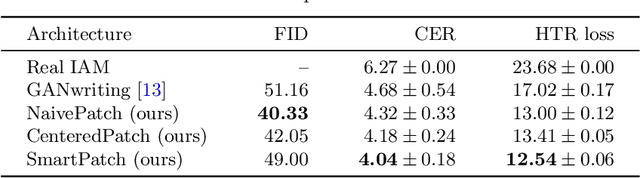
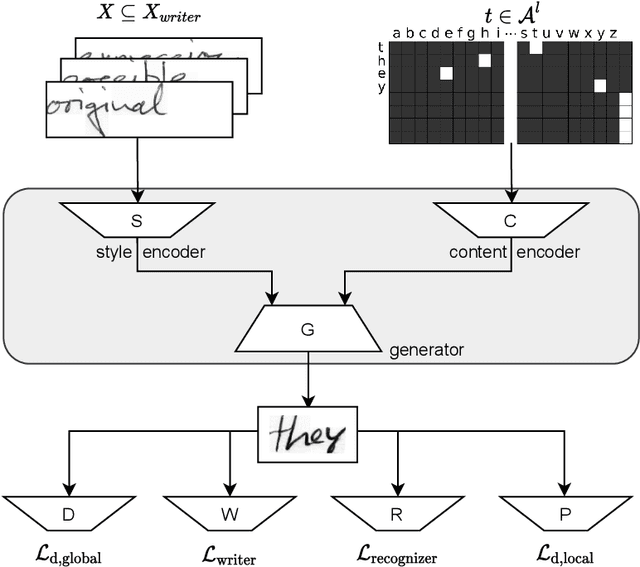

As of recent generative adversarial networks have allowed for big leaps in the realism of generated images in diverse domains, not the least of which being handwritten text generation. The generation of realistic-looking hand-written text is important because it can be used for data augmentation in handwritten text recognition (HTR) systems or human-computer interaction. We propose SmartPatch, a new technique increasing the performance of current state-of-the-art methods by augmenting the training feedback with a tailored solution to mitigate pen-level artifacts. We combine the well-known patch loss with information gathered from the parallel trained handwritten text recognition system and the separate characters of the word. This leads to a more enhanced local discriminator and results in more realistic and higher-quality generated handwritten words.
ICFHR 2020 Competition on Image Retrieval for Historical Handwritten Fragments
Oct 20, 2020



This competition succeeds upon a line of competitions for writer and style analysis of historical document images. In particular, we investigate the performance of large-scale retrieval of historical document fragments in terms of style and writer identification. The analysis of historic fragments is a difficult challenge commonly solved by trained humanists. In comparison to previous competitions, we make the results more meaningful by addressing the issue of sample granularity and moving from writer to page fragment retrieval. The two approaches, style and author identification, provide information on what kind of information each method makes better use of and indirectly contribute to the interpretability of the participating method. Therefore, we created a large dataset consisting of more than 120 000 fragments. Although the most teams submitted methods based on convolutional neural networks, the winning entry achieves an mAP below 40%.