 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroPapyri: A Deep Attention Embedding Network for Handwritten Papyri Retrieval
Aug 14, 2024The intersection of computer vision and machine learning has emerged as a promising avenue for advancing historical research, facilitating a more profound exploration of our past. However, the application of machine learning approaches in historical palaeography is often met with criticism due to their perceived ``black box'' nature. In response to this challenge, we introduce NeuroPapyri, an innovative deep learning-based model specifically designed for the analysis of images containing ancient Greek papyri. To address concerns related to transparency and interpretability, the model incorporates an attention mechanism. This attention mechanism not only enhances the model's performance but also provides a visual representation of the image regions that significantly contribute to the decision-making process. Specifically calibrated for processing images of papyrus documents with lines of handwritten text, the model utilizes individual attention maps to inform the presence or absence of specific characters in the input image. This paper presents the NeuroPapyri model, including its architecture and training methodology. Results from the evaluation demonstrate NeuroPapyri's efficacy in document retrieval, showcasing its potential to advance the analysis of historical manuscripts.
KaiRacters: Character-level-based Writer Retrieval for Greek Papyri
Jul 10, 2024



This paper presents a character-based approach for enhancing writer retrieval performance in the context of Greek papyri. Our contribution lies in introducing character-level annotations for frequently used characters, in our case the trigram kai and four additional letters (epsilon, kappa, mu, omega), in Greek texts. We use a state-of-the-art writer retrieval approach based on NetVLAD and compare a character-level-based feature aggregation method against the current default baseline of using small patches located at SIFT keypoint locations for building the page descriptors. We demonstrate that by using only about 15 characters per page, we are able to boost the performance up to 4% mAP (a relative improvement of 11%) on the GRK-120 dataset. Additionally, our qualitative analysis offers insights into the similarity scores of SIFT patches and specific characters. We publish the dataset with character-level annotations, including a quality label and our binarized images for further research.
Writer Retrieval and Writer Identification in Greek Papyri
Dec 15, 2022The analysis of digitized historical manuscripts is typically addressed by paleographic experts. Writer identification refers to the classification of known writers while writer retrieval seeks to find the writer by means of image similarity in a dataset of images. While automatic writer identification/retrieval methods already provide promising results for many historical document types, papyri data is very challenging due to the fiber structures and severe artifacts. Thus, an important step for an improved writer identification is the preprocessing and feature sampling process. We investigate several methods and show that a good binarization is key to an improved writer identification in papyri writings. We focus mainly on writer retrieval using unsupervised feature methods based on traditional or self-supervised-based methods. It is, however, also comparable to the state of the art supervised deep learning-based method in the case of writer classification/re-identification.
Legibility Enhancement of Papyri Using Color Processing and Visual Illusions: A Case Study in Critical Vision
Mar 11, 2021
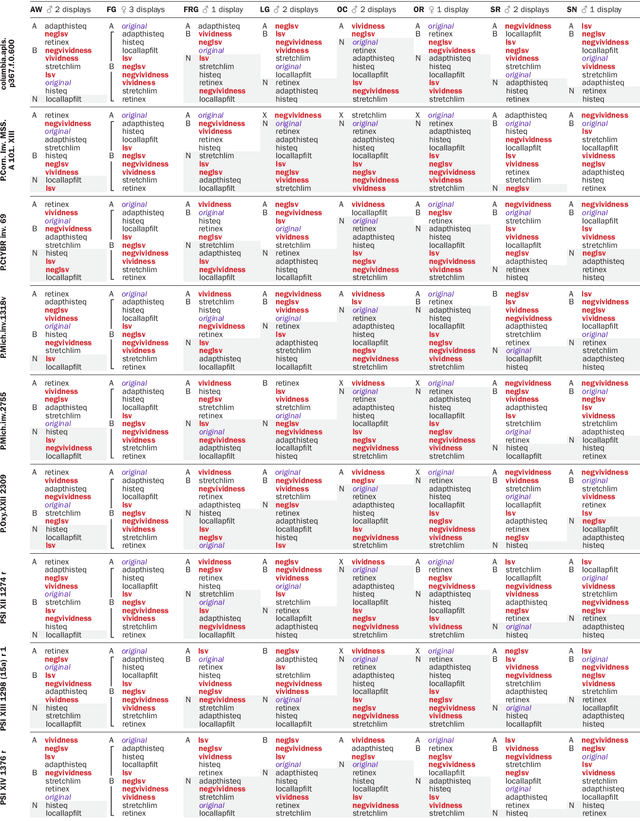

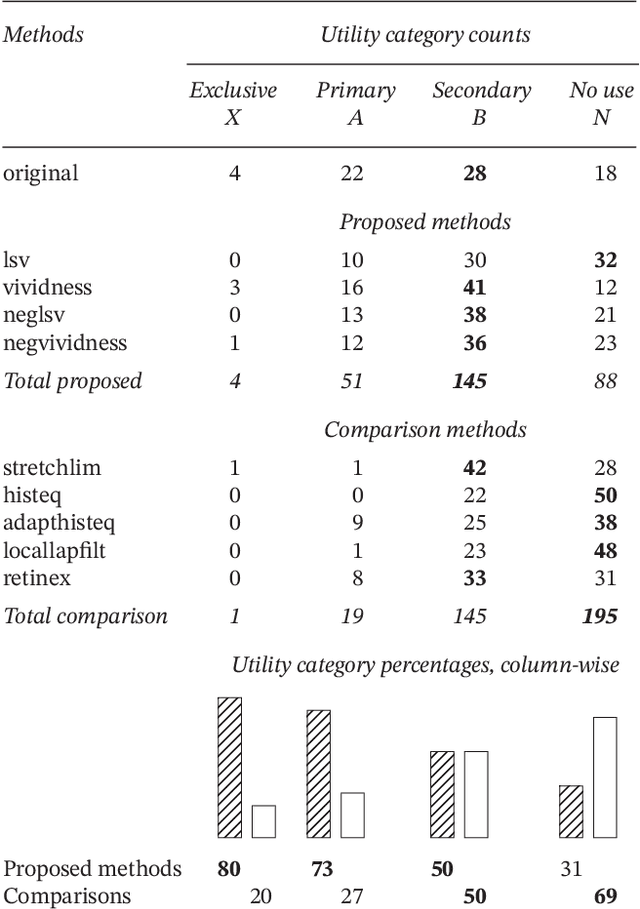
Purpose: This article develops theoretical, algorithmic, perceptual, and interaction aspects of script legibility enhancement in the visible light spectrum for the purpose of scholarly editing of papyri texts. - Methods: Novel legibility enhancement algorithms based on color processing and visual illusions are proposed and compared to classic methods. A user experience experiment was carried out to evaluate the solutions and better understand the problem on an empirical basis. - Results: (1) The proposed methods outperformed the comparison methods. (2) The methods that most successfully enhanced script legibility were those that leverage human perception. (3) Users exhibited a broad behavioral spectrum of text-deciphering strategies, under the influence of factors such as personality and social conditioning, tasks and application domains, expertise level and image quality, and affordances of software, hardware, and interfaces. No single method satisfied all factor configurations. Therefore, using synergetically a range of enhancement methods and interaction modalities is suggested for optimal results and user satisfaction. (4) A paradigm of legibility enhancement for critical applications is outlined, comprising the following criteria: interpreting images skeptically; approaching enhancement as a system problem; considering all image structures as potential information; deriving interpretations from connections across distinct spatial locations; and making uncertainty and alternative interpretations explicit, both visually and numerically.