 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroPapyri: A Deep Attention Embedding Network for Handwritten Papyri Retrieval
Aug 14, 2024The intersection of computer vision and machine learning has emerged as a promising avenue for advancing historical research, facilitating a more profound exploration of our past. However, the application of machine learning approaches in historical palaeography is often met with criticism due to their perceived ``black box'' nature. In response to this challenge, we introduce NeuroPapyri, an innovative deep learning-based model specifically designed for the analysis of images containing ancient Greek papyri. To address concerns related to transparency and interpretability, the model incorporates an attention mechanism. This attention mechanism not only enhances the model's performance but also provides a visual representation of the image regions that significantly contribute to the decision-making process. Specifically calibrated for processing images of papyrus documents with lines of handwritten text, the model utilizes individual attention maps to inform the presence or absence of specific characters in the input image. This paper presents the NeuroPapyri model, including its architecture and training methodology. Results from the evaluation demonstrate NeuroPapyri's efficacy in document retrieval, showcasing its potential to advance the analysis of historical manuscripts.
I Can't Believe It's Not Better: In-air Movement For Alzheimer Handwriting Synthetic Generation
Dec 08, 2023During recent years, there here has been a boom in terms of deep learning use for handwriting analysis and recognition. One main application for handwriting analysis is early detection and diagnosis in the health field. Unfortunately, most real case problems still suffer a scarcity of data, which makes difficult the use of deep learning-based models. To alleviate this problem, some works resort to synthetic data generation. Lately, more works are directed towards guided data synthetic generation, a generation that uses the domain and data knowledge to generate realistic data that can be useful to train deep learning models. In this work, we combine the domain knowledge about the Alzheimer's disease for handwriting and use it for a more guided data generation. Concretely, we have explored the use of in-air movements for synthetic data generation.
A Few Shot Multi-Representation Approach for N-gram Spotting in Historical Manuscripts
Sep 21, 2022
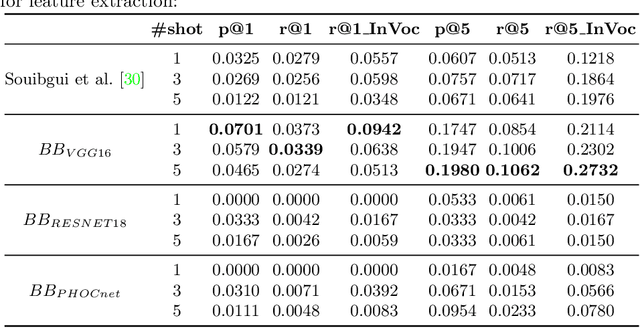

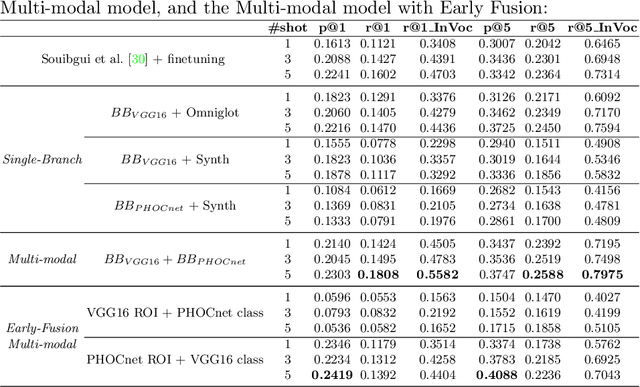
Despite recent advances in automatic text recognition, the performance remains moderate when it comes to historical manuscripts. This is mainly because of the scarcity of available labelled data to train the data-hungry Handwritten Text Recognition (HTR) models. The Keyword Spotting System (KWS) provides a valid alternative to HTR due to the reduction in error rate, but it is usually limited to a closed reference vocabulary. In this paper, we propose a few-shot learning paradigm for spotting sequences of a few characters (N-gram) that requires a small amount of labelled training data. We exhibit that recognition of important n-grams could reduce the system's dependency on vocabulary. In this case, an out-of-vocabulary (OOV) word in an input handwritten line image could be a sequence of n-grams that belong to the lexicon. An extensive experimental evaluation of our proposed multi-representation approach was carried out on a subset of Bentham's historical manuscript collections to obtain some really promising results in this direction.