 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for the Recognition of Historical and Handwritten Music Scores in Western Notation
May 18, 2026A large amount of musical heritage has been digitised by memory institutions: libraries, museums, and archives. Nevertheless, the field of Optical Music Recognition (OMR) has struggled with making this music machine-readable, despite advances in deep learning, mostly because no datasets for training systems in realistic conditions were available. The MusiCorpus dataset aims to remedy this situation by providing 1,309 pages of historical sheet music, primarily handwritten, with MusicXML transcriptions and symbol annotations. It is the largest dataset of handwritten music to date and the first dataset containing a realistic and representative sample of musical document collections from memory institutions, suitable for training and evaluating both end-to-end and object detection-based OMR systems and comparing their performance.
Learning to Decipher from Pixels -- A Case Study of Copiale
Apr 26, 2026Historical encrypted manuscripts require both paleographic interpretation of cipher symbols and cryptanalytic recovery of plaintext. Most existing computational workflows rely on a transcription-first paradigm, in which handwritten symbols are transcribed prior to decipherment. This intermediate step is labor-intensive, error-prone, and not always aligned with the goal of direct plaintext recovery. We propose an end-to-end, transcription-free approach that directly maps handwritten cipher images to plaintext. Using the Copiale cipher as a case study, we introduce the first text-line-level dataset pairing cipher images with German plaintext. We show that pretraining on generic handwriting data followed by cipher-specific fine-tuning substantially improves decipherment accuracy. Our results demonstrate that transcription-free image-to-plaintext decipherment is both feasible and effective for historical substitution ciphers, offering a simplified and scalable alternative to traditional pipelines. https://github.com/leitro/Decipher-from-Pixels-Copiale
Preserving Privacy Without Compromising Accuracy: Machine Unlearning for Handwritten Text Recognition
Apr 11, 2025



Handwritten Text Recognition (HTR) is essential for document analysis and digitization. However, handwritten data often contains user-identifiable information, such as unique handwriting styles and personal lexicon choices, which can compromise privacy and erode trust in AI services. Legislation like the ``right to be forgotten'' underscores the necessity for methods that can expunge sensitive information from trained models. Machine unlearning addresses this by selectively removing specific data from models without necessitating complete retraining. Yet, it frequently encounters a privacy-accuracy tradeoff, where safeguarding privacy leads to diminished model performance. In this paper, we introduce a novel two-stage unlearning strategy for a multi-head transformer-based HTR model, integrating pruning and random labeling. Our proposed method utilizes a writer classification head both as an indicator and a trigger for unlearning, while maintaining the efficacy of the recognition head. To our knowledge, this represents the first comprehensive exploration of machine unlearning within HTR tasks. We further employ Membership Inference Attacks (MIA) to evaluate the effectiveness of unlearning user-identifiable information. Extensive experiments demonstrate that our approach effectively preserves privacy while maintaining model accuracy, paving the way for new research directions in the document analysis community. Our code will be publicly available upon acceptance.
Structured Analysis and Comparison of Alphabets in Historical Handwritten Ciphers
Oct 29, 2024

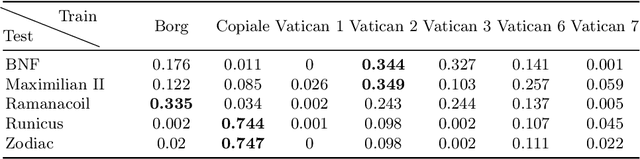

Historical ciphered manuscripts are documents that were typically used in sensitive communications within military and diplomatic contexts or among members of secret societies. These secret messages were concealed by inventing a method of writing employing symbols from diverse sources such as digits, alchemy signs and Latin or Greek characters. When studying a new, unseen cipher, the automatic search and grouping of ciphers with a similar alphabet can aid the scholar in its transcription and cryptanalysis because it indicates a probability that the underlying cipher is similar. In this study, we address this need by proposing the CSI metric, a novel way of comparing pairs of ciphered documents. We assess their effectiveness in an unsupervised clustering scenario utilising visual features, including SIFT, pre-trained learnt embeddings, and OCR descriptors.
GRIF-DM: Generation of Rich Impression Fonts using Diffusion Models
Aug 14, 2024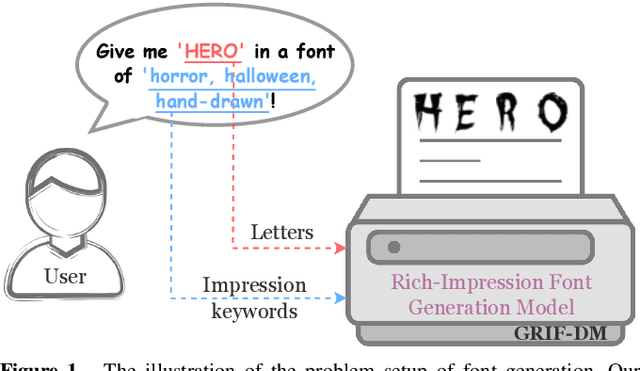
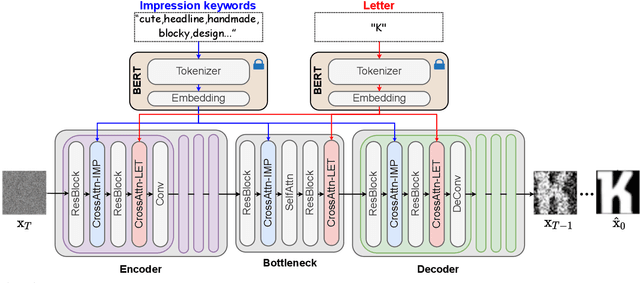


Fonts are integral to creative endeavors, design processes, and artistic productions. The appropriate selection of a font can significantly enhance artwork and endow advertisements with a higher level of expressivity. Despite the availability of numerous diverse font designs online, traditional retrieval-based methods for font selection are increasingly being supplanted by generation-based approaches. These newer methods offer enhanced flexibility, catering to specific user preferences and capturing unique stylistic impressions. However, current impression font techniques based on Generative Adversarial Networks (GANs) necessitate the utilization of multiple auxiliary losses to provide guidance during generation. Furthermore, these methods commonly employ weighted summation for the fusion of impression-related keywords. This leads to generic vectors with the addition of more impression keywords, ultimately lacking in detail generation capacity. In this paper, we introduce a diffusion-based method, termed \ourmethod, to generate fonts that vividly embody specific impressions, utilizing an input consisting of a single letter and a set of descriptive impression keywords. The core innovation of \ourmethod lies in the development of dual cross-attention modules, which process the characteristics of the letters and impression keywords independently but synergistically, ensuring effective integration of both types of information. Our experimental results, conducted on the MyFonts dataset, affirm that this method is capable of producing realistic, vibrant, and high-fidelity fonts that are closely aligned with user specifications. This confirms the potential of our approach to revolutionize font generation by accommodating a broad spectrum of user-driven design requirements. Our code is publicly available at \url{https://github.com/leitro/GRIF-DM}.
The Common Optical Music Recognition Evaluation Framework
Dec 20, 2023The quality of Optical Music Recognition (OMR) systems is a rather difficult magnitude to measure. There is no lingua franca shared among OMR datasets that allows to compare systems' performance on equal grounds, since most of them are specialised on certain approaches. As a result, most state-of-the-art works currently report metrics that cannot be compared directly. In this paper we identify the need of a common music representation language and propose the Music Tree Notation (MTN) format, thanks to which the definition of standard metrics is possible. This format represents music as a set of primitives that group together into higher-abstraction nodes, a compromise between the expression of fully graph-based and sequential notation formats. We have also developed a specific set of OMR metrics and a typeset score dataset as a proof of concept of this idea.
I Can't Believe It's Not Better: In-air Movement For Alzheimer Handwriting Synthetic Generation
Dec 08, 2023During recent years, there here has been a boom in terms of deep learning use for handwriting analysis and recognition. One main application for handwriting analysis is early detection and diagnosis in the health field. Unfortunately, most real case problems still suffer a scarcity of data, which makes difficult the use of deep learning-based models. To alleviate this problem, some works resort to synthetic data generation. Lately, more works are directed towards guided data synthetic generation, a generation that uses the domain and data knowledge to generate realistic data that can be useful to train deep learning models. In this work, we combine the domain knowledge about the Alzheimer's disease for handwriting and use it for a more guided data generation. Concretely, we have explored the use of in-air movements for synthetic data generation.
CSSL-MHTR: Continual Self-Supervised Learning for Scalable Multi-script Handwritten Text Recognition
Mar 16, 2023Self-supervised learning has recently emerged as a strong alternative in document analysis. These approaches are now capable of learning high-quality image representations and overcoming the limitations of supervised methods, which require a large amount of labeled data. However, these methods are unable to capture new knowledge in an incremental fashion, where data is presented to the model sequentially, which is closer to the realistic scenario. In this paper, we explore the potential of continual self-supervised learning to alleviate the catastrophic forgetting problem in handwritten text recognition, as an example of sequence recognition. Our method consists in adding intermediate layers called adapters for each task, and efficiently distilling knowledge from the previous model while learning the current task. Our proposed framework is efficient in both computation and memory complexity. To demonstrate its effectiveness, we evaluate our method by transferring the learned model to diverse text recognition downstream tasks, including Latin and non-Latin scripts. As far as we know, this is the first application of continual self-supervised learning for handwritten text recognition. We attain state-of-the-art performance on English, Italian and Russian scripts, whilst adding only a few parameters per task. The code and trained models will be publicly available.
Towards Stroke Patients' Upper-limb Automatic Motor Assessment Using Smartwatches
Dec 09, 2022Assessing the physical condition in rehabilitation scenarios is a challenging problem, since it involves Human Activity Recognition (HAR) and kinematic analysis methods. In addition, the difficulties increase in unconstrained rehabilitation scenarios, which are much closer to the real use cases. In particular, our aim is to design an upper-limb assessment pipeline for stroke patients using smartwatches. We focus on the HAR task, as it is the first part of the assessing pipeline. Our main target is to automatically detect and recognize four key movements inspired by the Fugl-Meyer assessment scale, which are performed in both constrained and unconstrained scenarios. In addition to the application protocol and dataset, we propose two detection and classification baseline methods. We believe that the proposed framework, dataset and baseline results will serve to foster this research field.
The RPM3D project: 3D Kinematics for Remote Patient Monitoring
Dec 09, 2022This project explores the feasibility of remote patient monitoring based on the analysis of 3D movements captured with smartwatches. We base our analysis on the Kinematic Theory of Rapid Human Movement. We have validated our research in a real case scenario for stroke rehabilitation at the Guttmann Institute5 (neurorehabilitation hospital), showing promising results. Our work could have a great impact in remote healthcare applications, improving the medical efficiency and reducing the healthcare costs. Future steps include more clinical validation, developing multi-modal analysis architectures (analysing data from sensors, images, audio, etc.), and exploring the application of our technology to monitor other neurodegenerative diseases.