 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent and Style Aware Generation of Text-line Images for Handwriting Recognition
Apr 12, 2022

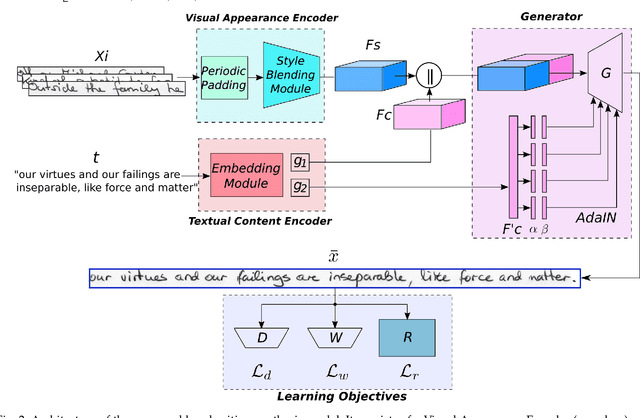
Handwritten Text Recognition has achieved an impressive performance in public benchmarks. However, due to the high inter- and intra-class variability between handwriting styles, such recognizers need to be trained using huge volumes of manually labeled training data. To alleviate this labor-consuming problem, synthetic data produced with TrueType fonts has been often used in the training loop to gain volume and augment the handwriting style variability. However, there is a significant style bias between synthetic and real data which hinders the improvement of recognition performance. To deal with such limitations, we propose a generative method for handwritten text-line images, which is conditioned on both visual appearance and textual content. Our method is able to produce long text-line samples with diverse handwriting styles. Once properly trained, our method can also be adapted to new target data by only accessing unlabeled text-line images to mimic handwritten styles and produce images with any textual content. Extensive experiments have been done on making use of the generated samples to boost Handwritten Text Recognition performance. Both qualitative and quantitative results demonstrate that the proposed approach outperforms the current state of the art.
Pay Attention to What You Read: Non-recurrent Handwritten Text-Line Recognition
May 26, 2020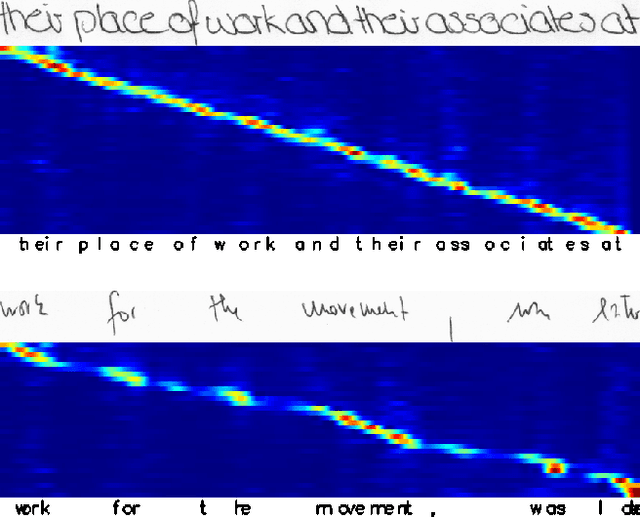
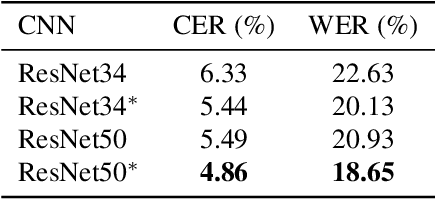
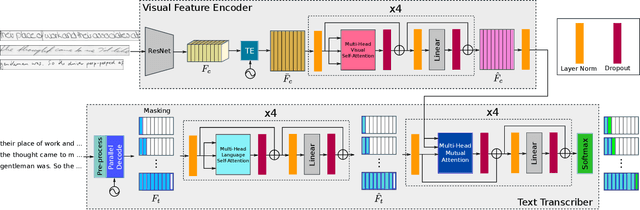

The advent of recurrent neural networks for handwriting recognition marked an important milestone reaching impressive recognition accuracies despite the great variability that we observe across different writing styles. Sequential architectures are a perfect fit to model text lines, not only because of the inherent temporal aspect of text, but also to learn probability distributions over sequences of characters and words. However, using such recurrent paradigms comes at a cost at training stage, since their sequential pipelines prevent parallelization. In this work, we introduce a non-recurrent approach to recognize handwritten text by the use of transformer models. We propose a novel method that bypasses any recurrence. By using multi-head self-attention layers both at the visual and textual stages, we are able to tackle character recognition as well as to learn language-related dependencies of the character sequences to be decoded. Our model is unconstrained to any predefined vocabulary, being able to recognize out-of-vocabulary words, i.e. words that do not appear in the training vocabulary. We significantly advance over prior art and demonstrate that satisfactory recognition accuracies are yielded even in few-shot learning scenarios.
GANwriting: Content-Conditioned Generation of Styled Handwritten Word Images
Mar 05, 2020

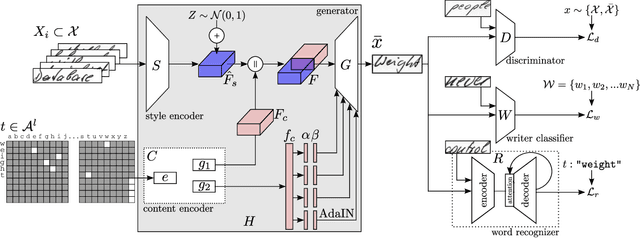

Although current image generation methods have reached impressive quality levels, they are still unable to produce plausible yet diverse images of handwritten words. On the contrary, when writing by hand, a great variability is observed across different writers, and even when analyzing words scribbled by the same individual, involuntary variations are conspicuous. In this work, we take a step closer to producing realistic and varied artificially rendered handwritten words. We propose a novel method that is able to produce credible handwritten word images by conditioning the generative process with both calligraphic style features and textual content. Our generator is guided by three complementary learning objectives: to produce realistic images, to imitate a certain handwriting style and to convey a specific textual content. Our model is unconstrained to any predefined vocabulary, being able to render whatever input word. Given a sample writer, it is also able to mimic its calligraphic features in a few-shot setup. We significantly advance over prior art and demonstrate with qualitative, quantitative and human-based evaluations the realistic aspect of our synthetically produced images.
Candidate Fusion: Integrating Language Modelling into a Sequence-to-Sequence Handwritten Word Recognition Architecture
Dec 21, 2019
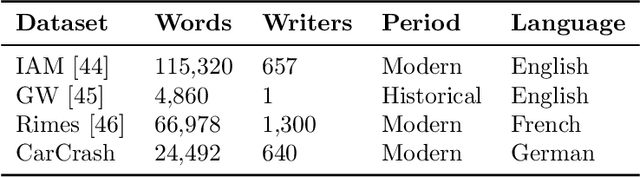

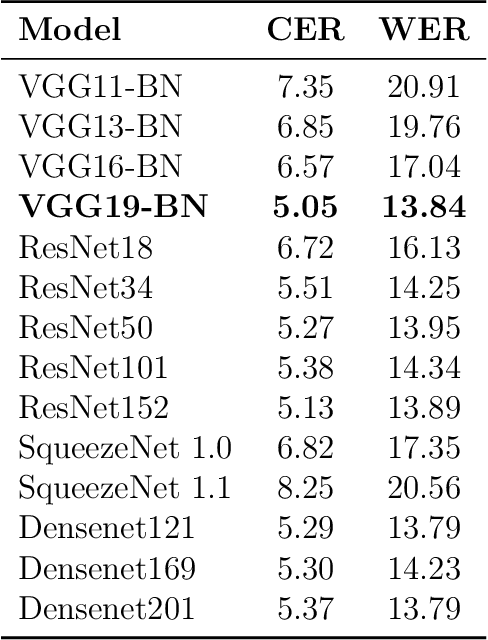
Sequence-to-sequence models have recently become very popular for tackling handwritten word recognition problems. However, how to effectively integrate an external language model into such recognizer is still a challenging problem. The main challenge faced when training a language model is to deal with the language model corpus which is usually different to the one used for training the handwritten word recognition system. Thus, the bias between both word corpora leads to incorrectness on the transcriptions, providing similar or even worse performances on the recognition task. In this work, we introduce Candidate Fusion, a novel way to integrate an external language model to a sequence-to-sequence architecture. Moreover, it provides suggestions from an external language knowledge, as a new input to the sequence-to-sequence recognizer. Hence, Candidate Fusion provides two improvements. On the one hand, the sequence-to-sequence recognizer has the flexibility not only to combine the information from itself and the language model, but also to choose the importance of the information provided by the language model. On the other hand, the external language model has the ability to adapt itself to the training corpus and even learn the most commonly errors produced from the recognizer. Finally, by conducting comprehensive experiments, the Candidate Fusion proves to outperform the state-of-the-art language models for handwritten word recognition tasks.
TreyNet: A Neural Model for Text Localization, Transcription and Named Entity Recognition in Full Pages
Dec 20, 2019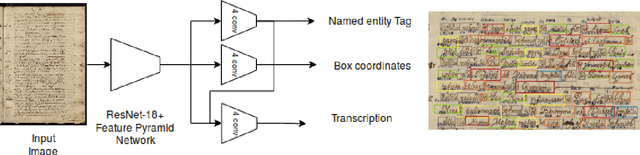
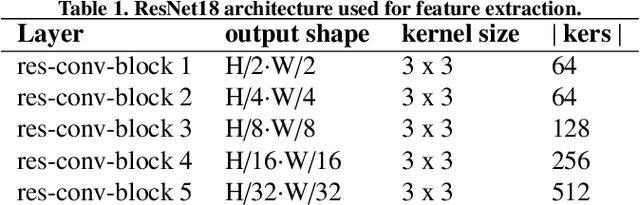
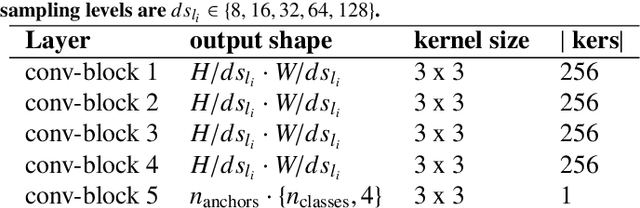
In the last years, the consolidation of deep neural network architectures for information extraction in document images has brought big improvements in the performance of each of the tasks involved in this process, consisting of text localization, transcription, and named entity recognition. However, this process is traditionally performed with separate methods for each task. In this work we propose an end-to-end model that jointly performs handwritten text detection, transcription, and named entity recognition at page level, capable of benefiting from shared features for these tasks. We exhaustively evaluate our approach on different datasets, discussing its advantages and limitations compared to sequential approaches.
Unsupervised Writer Adaptation for Synthetic-to-Real Handwritten Word Recognition
Sep 18, 2019
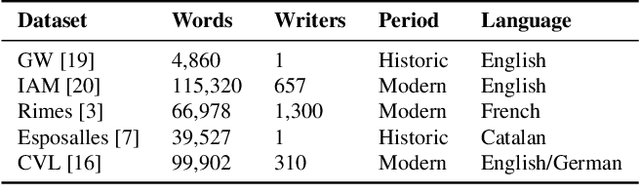
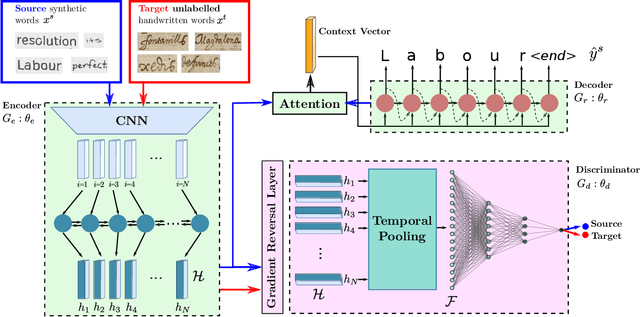
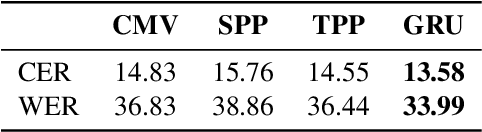
Handwritten Text Recognition (HTR) is still a challenging problem because it must deal with two important difficulties: the variability among writing styles, and the scarcity of labelled data. To alleviate such problems, synthetic data generation and data augmentation are typically used to train HTR systems. However, training with such data produces encouraging but still inaccurate transcriptions in real words. In this paper, we propose an unsupervised writer adaptation approach that is able to automatically adjust a generic handwritten word recognizer, fully trained with synthetic fonts, towards a new incoming writer. We have experimentally validated our proposal using five different datasets, covering several challenges (i) the document source: modern and historic samples, which may involve paper degradation problems; (ii) different handwriting styles: single and multiple writer collections; and (iii) language, which involves different character combinations. Across these challenging collections, we show that our system is able to maintain its performance, thus, it provides a practical and generic approach to deal with new document collections without requiring any expensive and tedious manual annotation step.
Joint Recognition of Handwritten Text and Named Entities with a Neural End-to-end Model
Mar 22, 2018



When extracting information from handwritten documents, text transcription and named entity recognition are usually faced as separate subsequent tasks. This has the disadvantage that errors in the first module affect heavily the performance of the second module. In this work we propose to do both tasks jointly, using a single neural network with a common architecture used for plain text recognition. Experimentally, the work has been tested on a collection of historical marriage records. Results of experiments are presented to show the effect on the performance for different configurations: different ways of encoding the information, doing or not transfer learning and processing at text line or multi-line region level. The results are comparable to state of the art reported in the ICDAR 2017 Information Extraction competition, even though the proposed technique does not use any dictionaries, language modeling or post processing.