 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent and Style Aware Generation of Text-line Images for Handwriting Recognition
Apr 12, 2022

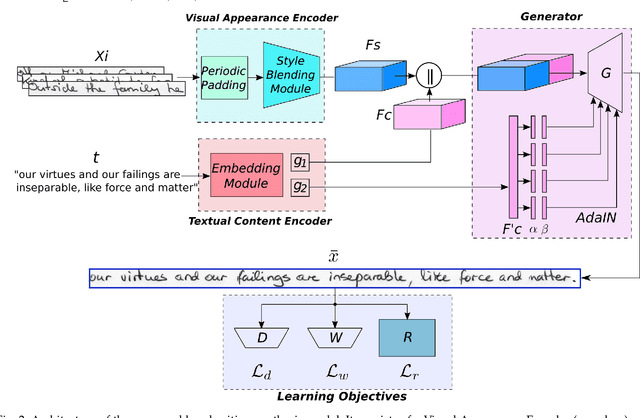
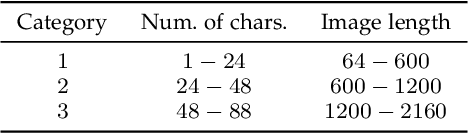
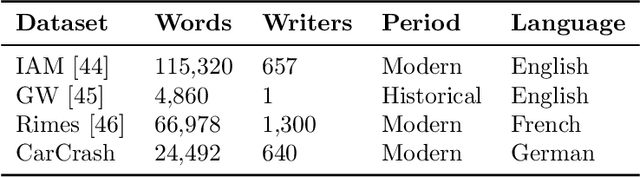
Handwritten Text Recognition has achieved an impressive performance in public benchmarks. However, due to the high inter- and intra-class variability between handwriting styles, such recognizers need to be trained using huge volumes of manually labeled training data. To alleviate this labor-consuming problem, synthetic data produced with TrueType fonts has been often used in the training loop to gain volume and augment the handwriting style variability. However, there is a significant style bias between synthetic and real data which hinders the improvement of recognition performance. To deal with such limitations, we propose a generative method for handwritten text-line images, which is conditioned on both visual appearance and textual content. Our method is able to produce long text-line samples with diverse handwriting styles. Once properly trained, our method can also be adapted to new target data by only accessing unlabeled text-line images to mimic handwritten styles and produce images with any textual content. Extensive experiments have been done on making use of the generated samples to boost Handwritten Text Recognition performance. Both qualitative and quantitative results demonstrate that the proposed approach outperforms the current state of the art.
Localizing Infinity-shaped fishes: Sketch-guided object localization in the wild
Sep 24, 2021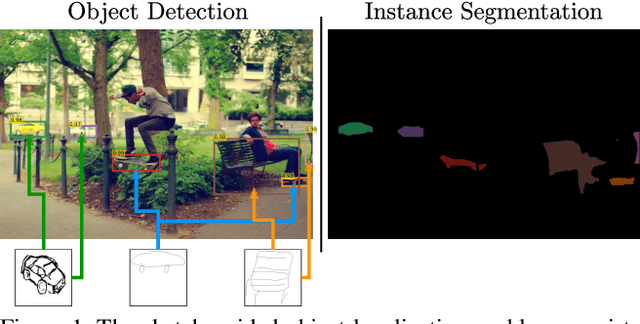

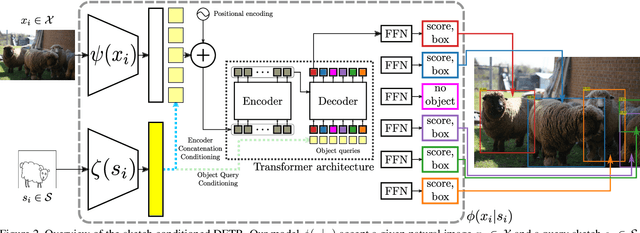
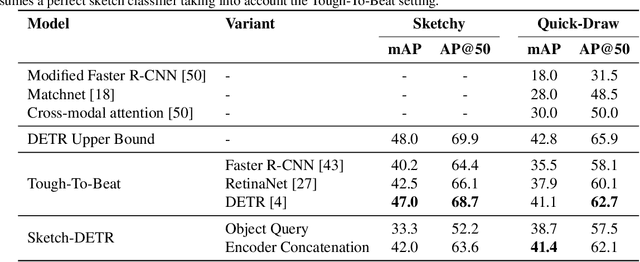
This work investigates the problem of sketch-guided object localization (SGOL), where human sketches are used as queries to conduct the object localization in natural images. In this cross-modal setting, we first contribute with a tough-to-beat baseline that without any specific SGOL training is able to outperform the previous works on a fixed set of classes. The baseline is useful to analyze the performance of SGOL approaches based on available simple yet powerful methods. We advance prior arts by proposing a sketch-conditioned DETR (DEtection TRansformer) architecture which avoids a hard classification and alleviates the domain gap between sketches and images to localize object instances. Although the main goal of SGOL is focused on object detection, we explored its natural extension to sketch-guided instance segmentation. This novel task allows to move towards identifying the objects at pixel level, which is of key importance in several applications. We experimentally demonstrate that our model and its variants significantly advance over previous state-of-the-art results. All training and testing code of our model will be released to facilitate future research{{https://github.com/priba/sgol_wild}}.
Graph-based Deep Generative Modelling for Document Layout Generation
Jul 09, 2021

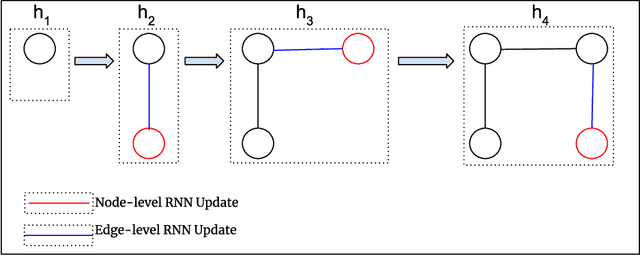
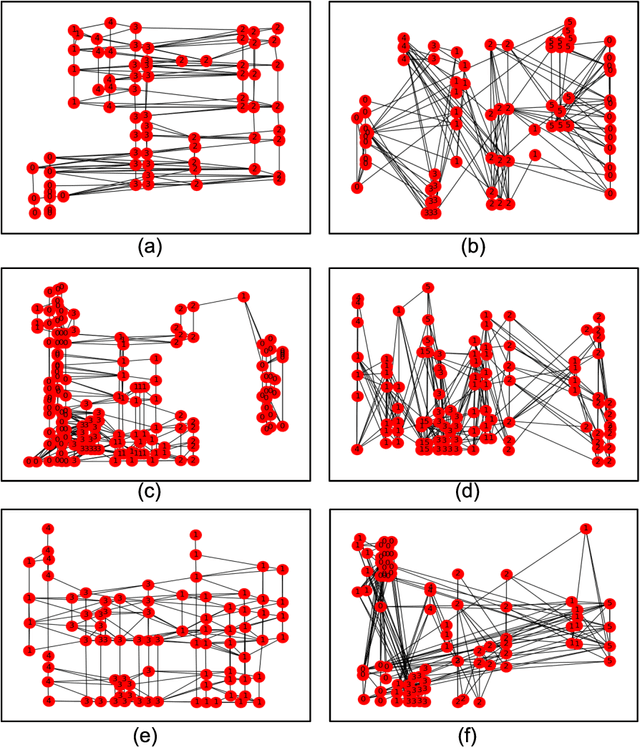
One of the major prerequisites for any deep learning approach is the availability of large-scale training data. When dealing with scanned document images in real world scenarios, the principal information of its content is stored in the layout itself. In this work, we have proposed an automated deep generative model using Graph Neural Networks (GNNs) to generate synthetic data with highly variable and plausible document layouts that can be used to train document interpretation systems, in this case, specially in digital mailroom applications. It is also the first graph-based approach for document layout generation task experimented on administrative document images, in this case, invoices.
DocSynth: A Layout Guided Approach for Controllable Document Image Synthesis
Jul 06, 2021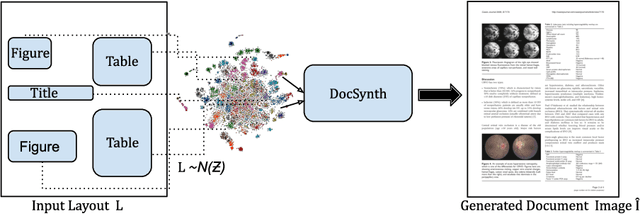

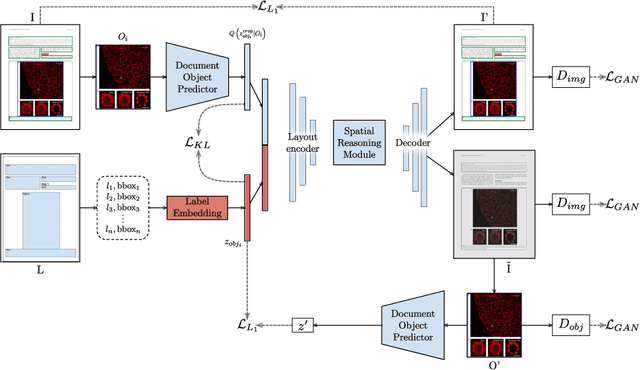

Despite significant progress on current state-of-the-art image generation models, synthesis of document images containing multiple and complex object layouts is a challenging task. This paper presents a novel approach, called DocSynth, to automatically synthesize document images based on a given layout. In this work, given a spatial layout (bounding boxes with object categories) as a reference by the user, our proposed DocSynth model learns to generate a set of realistic document images consistent with the defined layout. Also, this framework has been adapted to this work as a superior baseline model for creating synthetic document image datasets for augmenting real data during training for document layout analysis tasks. Different sets of learning objectives have been also used to improve the model performance. Quantitatively, we also compare the generated results of our model with real data using standard evaluation metrics. The results highlight that our model can successfully generate realistic and diverse document images with multiple objects. We also present a comprehensive qualitative analysis summary of the different scopes of synthetic image generation tasks. Lastly, to our knowledge this is the first work of its kind.
Date Estimation in the Wild of Scanned Historical Photos: An Image Retrieval Approach
Jun 10, 2021
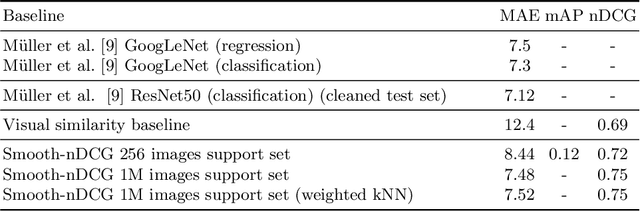

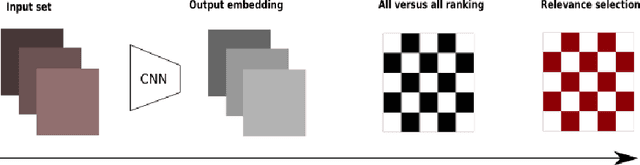
This paper presents a novel method for date estimation of historical photographs from archival sources. The main contribution is to formulate the date estimation as a retrieval task, where given a query, the retrieved images are ranked in terms of the estimated date similarity. The closer are their embedded representations the closer are their dates. Contrary to the traditional models that design a neural network that learns a classifier or a regressor, we propose a learning objective based on the nDCG ranking metric. We have experimentally evaluated the performance of the method in two different tasks: date estimation and date-sensitive image retrieval, using the DEW public database, overcoming the baseline methods.
Learning to Rank Words: Optimizing Ranking Metrics for Word Spotting
Jun 09, 2021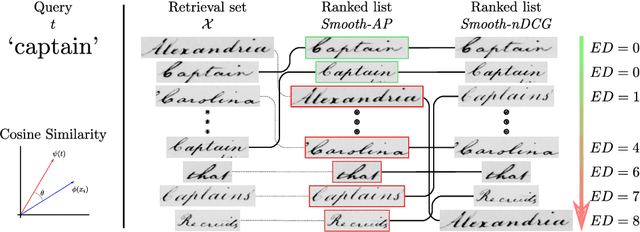
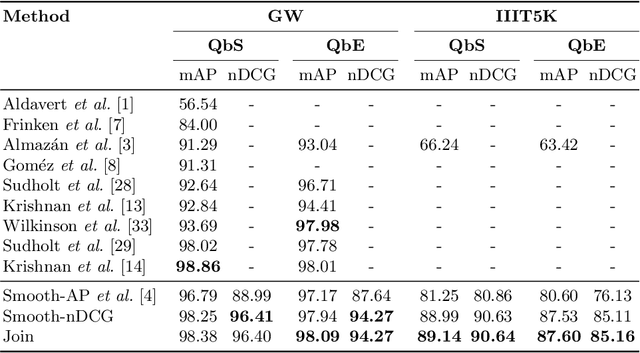
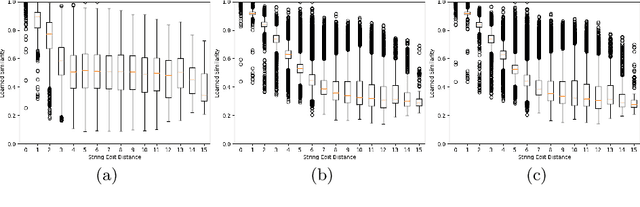
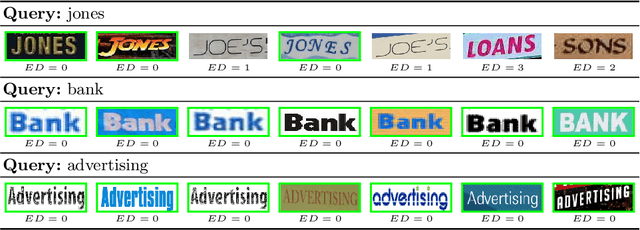
In this paper, we explore and evaluate the use of ranking-based objective functions for learning simultaneously a word string and a word image encoder. We consider retrieval frameworks in which the user expects a retrieval list ranked according to a defined relevance score. In the context of a word spotting problem, the relevance score has been set according to the string edit distance from the query string. We experimentally demonstrate the competitive performance of the proposed model on query-by-string word spotting for both, handwritten and real scene word images. We also provide the results for query-by-example word spotting, although it is not the main focus of this work.
Learning Graph Edit Distance by Graph Neural Networks
Aug 17, 2020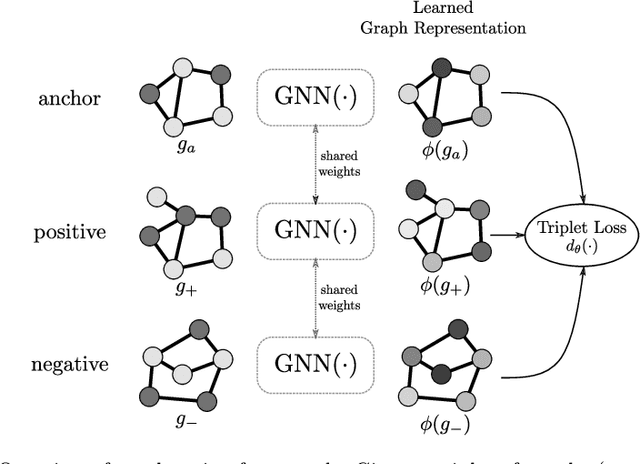
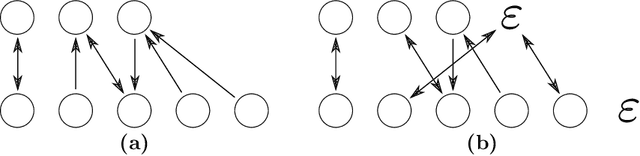

The emergence of geometric deep learning as a novel framework to deal with graph-based representations has faded away traditional approaches in favor of completely new methodologies. In this paper, we propose a new framework able to combine the advances on deep metric learning with traditional approximations of the graph edit distance. Hence, we propose an efficient graph distance based on the novel field of geometric deep learning. Our method employs a message passing neural network to capture the graph structure, and thus, leveraging this information for its use on a distance computation. The performance of the proposed graph distance is validated on two different scenarios. On the one hand, in a graph retrieval of handwritten words~\ie~keyword spotting, showing its superior performance when compared with (approximate) graph edit distance benchmarks. On the other hand, demonstrating competitive results for graph similarity learning when compared with the current state-of-the-art on a recent benchmark dataset.
Pay Attention to What You Read: Non-recurrent Handwritten Text-Line Recognition
May 26, 2020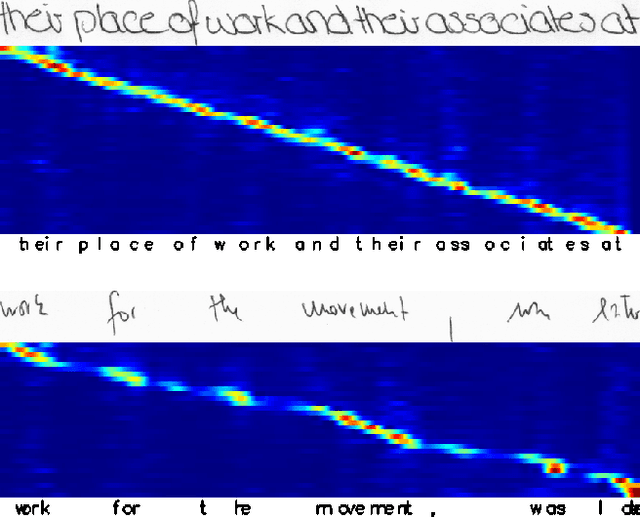
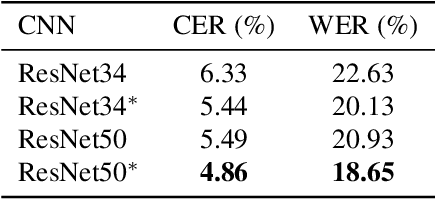
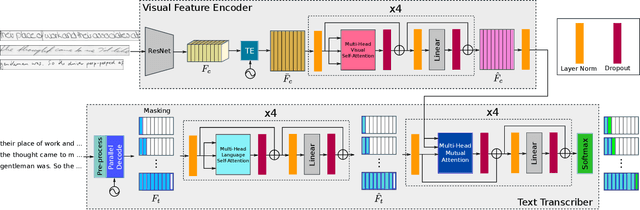

The advent of recurrent neural networks for handwriting recognition marked an important milestone reaching impressive recognition accuracies despite the great variability that we observe across different writing styles. Sequential architectures are a perfect fit to model text lines, not only because of the inherent temporal aspect of text, but also to learn probability distributions over sequences of characters and words. However, using such recurrent paradigms comes at a cost at training stage, since their sequential pipelines prevent parallelization. In this work, we introduce a non-recurrent approach to recognize handwritten text by the use of transformer models. We propose a novel method that bypasses any recurrence. By using multi-head self-attention layers both at the visual and textual stages, we are able to tackle character recognition as well as to learn language-related dependencies of the character sequences to be decoded. Our model is unconstrained to any predefined vocabulary, being able to recognize out-of-vocabulary words, i.e. words that do not appear in the training vocabulary. We significantly advance over prior art and demonstrate that satisfactory recognition accuracies are yielded even in few-shot learning scenarios.
GANwriting: Content-Conditioned Generation of Styled Handwritten Word Images
Mar 05, 2020

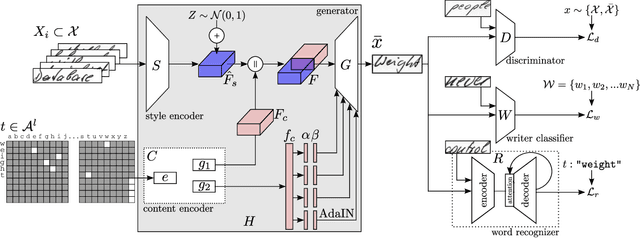

Although current image generation methods have reached impressive quality levels, they are still unable to produce plausible yet diverse images of handwritten words. On the contrary, when writing by hand, a great variability is observed across different writers, and even when analyzing words scribbled by the same individual, involuntary variations are conspicuous. In this work, we take a step closer to producing realistic and varied artificially rendered handwritten words. We propose a novel method that is able to produce credible handwritten word images by conditioning the generative process with both calligraphic style features and textual content. Our generator is guided by three complementary learning objectives: to produce realistic images, to imitate a certain handwriting style and to convey a specific textual content. Our model is unconstrained to any predefined vocabulary, being able to render whatever input word. Given a sample writer, it is also able to mimic its calligraphic features in a few-shot setup. We significantly advance over prior art and demonstrate with qualitative, quantitative and human-based evaluations the realistic aspect of our synthetically produced images.
Candidate Fusion: Integrating Language Modelling into a Sequence-to-Sequence Handwritten Word Recognition Architecture
Dec 21, 2019

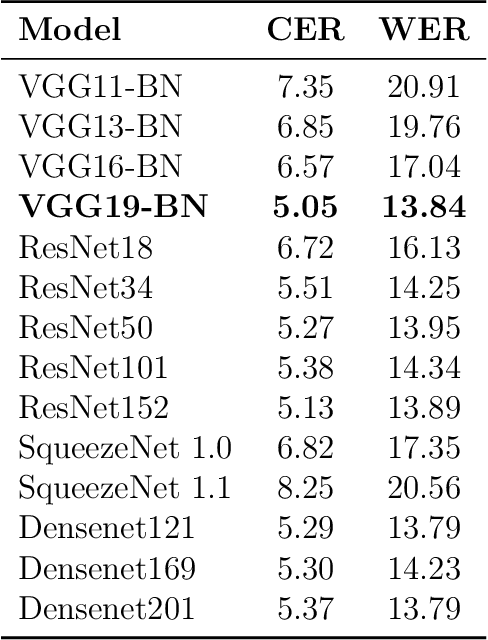
Sequence-to-sequence models have recently become very popular for tackling handwritten word recognition problems. However, how to effectively integrate an external language model into such recognizer is still a challenging problem. The main challenge faced when training a language model is to deal with the language model corpus which is usually different to the one used for training the handwritten word recognition system. Thus, the bias between both word corpora leads to incorrectness on the transcriptions, providing similar or even worse performances on the recognition task. In this work, we introduce Candidate Fusion, a novel way to integrate an external language model to a sequence-to-sequence architecture. Moreover, it provides suggestions from an external language knowledge, as a new input to the sequence-to-sequence recognizer. Hence, Candidate Fusion provides two improvements. On the one hand, the sequence-to-sequence recognizer has the flexibility not only to combine the information from itself and the language model, but also to choose the importance of the information provided by the language model. On the other hand, the external language model has the ability to adapt itself to the training corpus and even learn the most commonly errors produced from the recognizer. Finally, by conducting comprehensive experiments, the Candidate Fusion proves to outperform the state-of-the-art language models for handwritten word recognition tasks.