 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Model Checking: Graph-Based Inference of Visual Routines for Image Retrieval
Feb 19, 2026Information retrieval lies at the foundation of the modern digital industry. While natural language search has seen dramatic progress in recent years largely driven by embedding-based models and large-scale pretraining, the field still faces significant challenges. Specifically, queries that involve complex relationships, object compositions, or precise constraints such as identities, counts and proportions often remain unresolved or unreliable within current frameworks. In this paper, we propose a novel framework that integrates formal verification into deep learning-based image retrieval through a synergistic combination of graph-based verification methods and neural code generation. Our approach aims to support open-vocabulary natural language queries while producing results that are both trustworthy and verifiable. By grounding retrieval results in a system of formal reasoning, we move beyond the ambiguity and approximation that often characterize vector representations. Instead of accepting uncertainty as a given, our framework explicitly verifies each atomic truth in the user query against the retrieved content. This allows us to not only return matching results, but also to identify and mark which specific constraints are satisfied and which remain unmet, thereby offering a more transparent and accountable retrieval process while boosting the results of the most popular embedding-based approaches.
Structured Analysis and Comparison of Alphabets in Historical Handwritten Ciphers
Oct 29, 2024

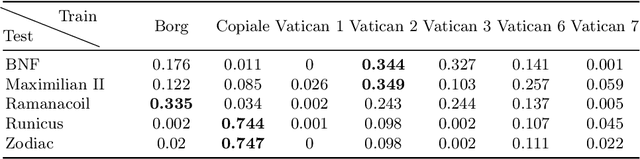

Historical ciphered manuscripts are documents that were typically used in sensitive communications within military and diplomatic contexts or among members of secret societies. These secret messages were concealed by inventing a method of writing employing symbols from diverse sources such as digits, alchemy signs and Latin or Greek characters. When studying a new, unseen cipher, the automatic search and grouping of ciphers with a similar alphabet can aid the scholar in its transcription and cryptanalysis because it indicates a probability that the underlying cipher is similar. In this study, we address this need by proposing the CSI metric, a novel way of comparing pairs of ciphered documents. We assess their effectiveness in an unsupervised clustering scenario utilising visual features, including SIFT, pre-trained learnt embeddings, and OCR descriptors.
The Role of Generative Systems in Historical Photography Management: A Case Study on Catalan Archives
Sep 05, 2024The use of image analysis in automated photography management is an increasing trend in heritage institutions. Such tools alleviate the human cost associated with the manual and expensive annotation of new data sources while facilitating fast access to the citizenship through online indexes and search engines. However, available tagging and description tools are usually designed around modern photographs in English, neglecting historical corpora in minoritized languages, each of which exhibits intrinsic particularities. The primary objective of this research is to study the quantitative contribution of generative systems in the description of historical sources. This is done by contextualizing the task of captioning historical photographs from the Catalan archives as a case study. Our findings provide practitioners with tools and directions on transfer learning for captioning models based on visual adaptation and linguistic proximity.
Fetch-A-Set: A Large-Scale OCR-Free Benchmark for Historical Document Retrieval
Jun 11, 2024



This paper introduces Fetch-A-Set (FAS), a comprehensive benchmark tailored for legislative historical document analysis systems, addressing the challenges of large-scale document retrieval in historical contexts. The benchmark comprises a vast repository of documents dating back to the XVII century, serving both as a training resource and an evaluation benchmark for retrieval systems. It fills a critical gap in the literature by focusing on complex extractive tasks within the domain of cultural heritage. The proposed benchmark tackles the multifaceted problem of historical document analysis, including text-to-image retrieval for queries and image-to-text topic extraction from document fragments, all while accommodating varying levels of document legibility. This benchmark aims to spur advancements in the field by providing baselines and data for the development and evaluation of robust historical document retrieval systems, particularly in scenarios characterized by wide historical spectrum.
A Generic Image Retrieval Method for Date Estimation of Historical Document Collections
Apr 08, 2022



Date estimation of historical document images is a challenging problem, with several contributions in the literature that lack of the ability to generalize from one dataset to others. This paper presents a robust date estimation system based in a retrieval approach that generalizes well in front of heterogeneous collections. we use a ranking loss function named smooth-nDCG to train a Convolutional Neural Network that learns an ordination of documents for each problem. One of the main usages of the presented approach is as a tool for historical contextual retrieval. It means that scholars could perform comparative analysis of historical images from big datasets in terms of the period where they were produced. We provide experimental evaluation on different types of documents from real datasets of manuscript and newspaper images.
Date Estimation in the Wild of Scanned Historical Photos: An Image Retrieval Approach
Jun 10, 2021
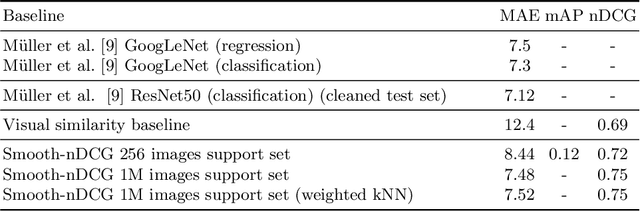

This paper presents a novel method for date estimation of historical photographs from archival sources. The main contribution is to formulate the date estimation as a retrieval task, where given a query, the retrieved images are ranked in terms of the estimated date similarity. The closer are their embedded representations the closer are their dates. Contrary to the traditional models that design a neural network that learns a classifier or a regressor, we propose a learning objective based on the nDCG ranking metric. We have experimentally evaluated the performance of the method in two different tasks: date estimation and date-sensitive image retrieval, using the DEW public database, overcoming the baseline methods.
Learning to Rank Words: Optimizing Ranking Metrics for Word Spotting
Jun 09, 2021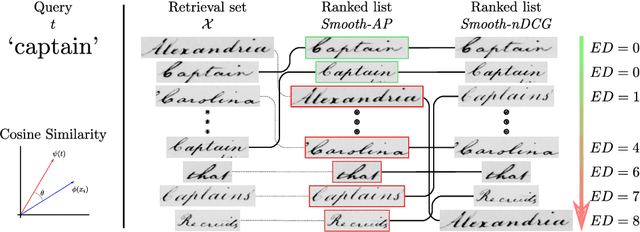
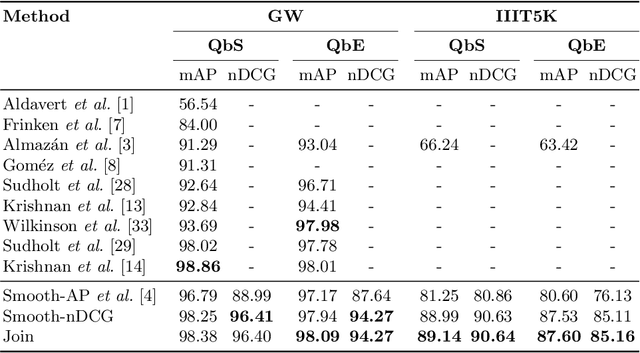
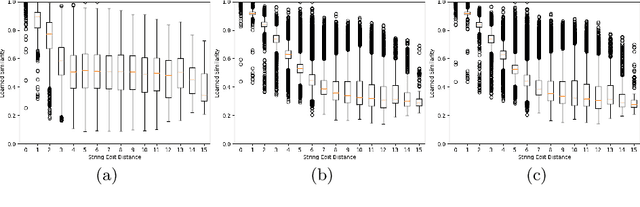
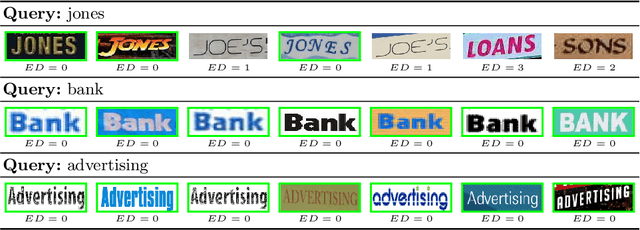
In this paper, we explore and evaluate the use of ranking-based objective functions for learning simultaneously a word string and a word image encoder. We consider retrieval frameworks in which the user expects a retrieval list ranked according to a defined relevance score. In the context of a word spotting problem, the relevance score has been set according to the string edit distance from the query string. We experimentally demonstrate the competitive performance of the proposed model on query-by-string word spotting for both, handwritten and real scene word images. We also provide the results for query-by-example word spotting, although it is not the main focus of this work.