 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Medical Document Analysis: Enhancing Trustworthy Pathology and Differential Diagnosis
Jun 24, 2025Medical document analysis plays a crucial role in extracting essential clinical insights from unstructured healthcare records, supporting critical tasks such as differential diagnosis. Determining the most probable condition among overlapping symptoms requires precise evaluation and deep medical expertise. While recent advancements in large language models (LLMs) have significantly enhanced performance in medical document analysis, privacy concerns related to sensitive patient data limit the use of online LLMs services in clinical settings. To address these challenges, we propose a trustworthy medical document analysis platform that fine-tunes a LLaMA-v3 using low-rank adaptation, specifically optimized for differential diagnosis tasks. Our approach utilizes DDXPlus, the largest benchmark dataset for differential diagnosis, and demonstrates superior performance in pathology prediction and variable-length differential diagnosis compared to existing methods. The developed web-based platform allows users to submit their own unstructured medical documents and receive accurate, explainable diagnostic results. By incorporating advanced explainability techniques, the system ensures transparent and reliable predictions, fostering user trust and confidence. Extensive evaluations confirm that the proposed method surpasses current state-of-the-art models in predictive accuracy while offering practical utility in clinical settings. This work addresses the urgent need for reliable, explainable, and privacy-preserving artificial intelligence solutions, representing a significant advancement in intelligent medical document analysis for real-world healthcare applications. The code can be found at \href{https://github.com/leitro/Differential-Diagnosis-LoRA}{https://github.com/leitro/Differential-Diagnosis-LoRA}.
The OCR Quest for Generalization: Learning to recognize low-resource alphabets with model editing
Jun 07, 2025Achieving robustness in recognition systems across diverse domains is crucial for their practical utility. While ample data availability is usually assumed, low-resource languages, such as ancient manuscripts and non-western languages, tend to be kept out of the equations of massive pretraining and foundational techniques due to an under representation. In this work, we aim for building models which can generalize to new distributions of data, such as alphabets, faster than centralized fine-tune strategies. For doing so, we take advantage of the recent advancements in model editing to enhance the incorporation of unseen scripts (low-resource learning). In contrast to state-of-the-art meta-learning, we showcase the effectiveness of domain merging in sparse distributions of data, with agnosticity of its relation to the overall distribution or any other prototyping necessity. Even when using the same exact training data, our experiments showcase significant performance boosts in \textbf{transfer learning} to new alphabets and \textbf{out-of-domain evaluation} in challenging domain shifts, including historical ciphered texts and non-Latin scripts. This research contributes a novel approach into building models that can easily adopt under-represented alphabets and, therefore, enable document recognition to a wider set of contexts and cultures.
The Role of Generative Systems in Historical Photography Management: A Case Study on Catalan Archives
Sep 05, 2024The use of image analysis in automated photography management is an increasing trend in heritage institutions. Such tools alleviate the human cost associated with the manual and expensive annotation of new data sources while facilitating fast access to the citizenship through online indexes and search engines. However, available tagging and description tools are usually designed around modern photographs in English, neglecting historical corpora in minoritized languages, each of which exhibits intrinsic particularities. The primary objective of this research is to study the quantitative contribution of generative systems in the description of historical sources. This is done by contextualizing the task of captioning historical photographs from the Catalan archives as a case study. Our findings provide practitioners with tools and directions on transfer learning for captioning models based on visual adaptation and linguistic proximity.
Fetch-A-Set: A Large-Scale OCR-Free Benchmark for Historical Document Retrieval
Jun 11, 2024



This paper introduces Fetch-A-Set (FAS), a comprehensive benchmark tailored for legislative historical document analysis systems, addressing the challenges of large-scale document retrieval in historical contexts. The benchmark comprises a vast repository of documents dating back to the XVII century, serving both as a training resource and an evaluation benchmark for retrieval systems. It fills a critical gap in the literature by focusing on complex extractive tasks within the domain of cultural heritage. The proposed benchmark tackles the multifaceted problem of historical document analysis, including text-to-image retrieval for queries and image-to-text topic extraction from document fragments, all while accommodating varying levels of document legibility. This benchmark aims to spur advancements in the field by providing baselines and data for the development and evaluation of robust historical document retrieval systems, particularly in scenarios characterized by wide historical spectrum.
Synthetic dataset of ID and Travel Document
Jan 03, 2024



This paper presents a new synthetic dataset of ID and travel documents, called SIDTD. The SIDTD dataset is created to help training and evaluating forged ID documents detection systems. Such a dataset has become a necessity as ID documents contain personal information and a public dataset of real documents can not be released. Moreover, forged documents are scarce, compared to legit ones, and the way they are generated varies from one fraudster to another resulting in a class of high intra-variability. In this paper we trained state-of-the-art models on this dataset and we compare them to the performance achieved in larger, but private, datasets. The creation of this dataset will help to document image analysis community to progress in the task of ID document verification.
TransferDoc: A Self-Supervised Transferable Document Representation Learning Model Unifying Vision and Language
Sep 11, 2023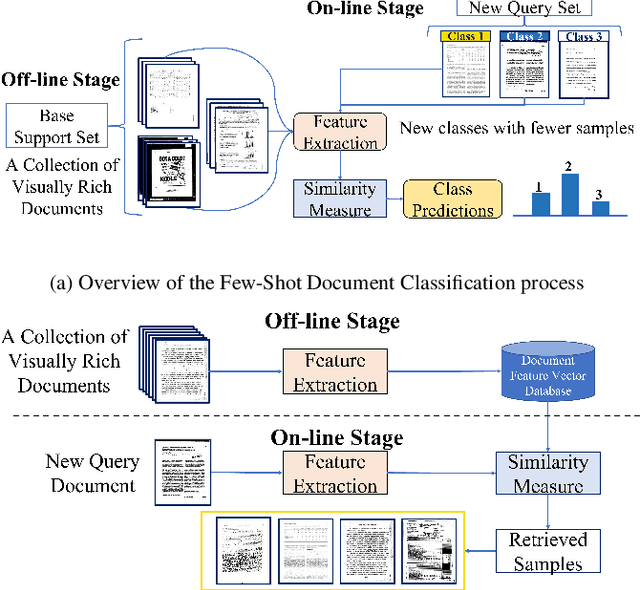
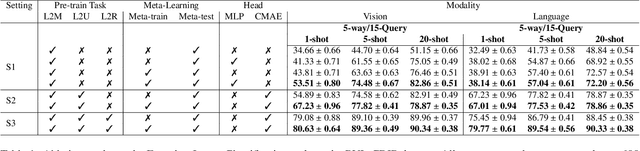
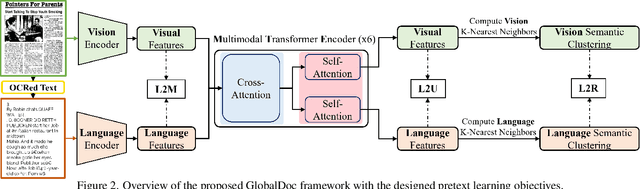

The field of visual document understanding has witnessed a rapid growth in emerging challenges and powerful multi-modal strategies. However, they rely on an extensive amount of document data to learn their pretext objectives in a ``pre-train-then-fine-tune'' paradigm and thus, suffer a significant performance drop in real-world online industrial settings. One major reason is the over-reliance on OCR engines to extract local positional information within a document page. Therefore, this hinders the model's generalizability, flexibility and robustness due to the lack of capturing global information within a document image. We introduce TransferDoc, a cross-modal transformer-based architecture pre-trained in a self-supervised fashion using three novel pretext objectives. TransferDoc learns richer semantic concepts by unifying language and visual representations, which enables the production of more transferable models. Besides, two novel downstream tasks have been introduced for a ``closer-to-real'' industrial evaluation scenario where TransferDoc outperforms other state-of-the-art approaches.
VLCDoC: Vision-Language Contrastive Pre-Training Model for Cross-Modal Document Classification
May 24, 2022
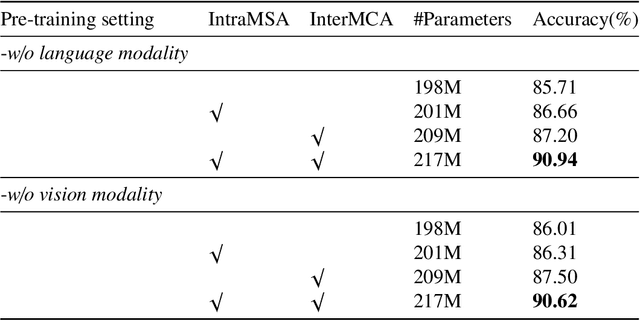
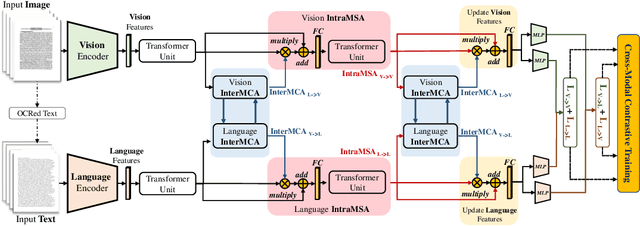
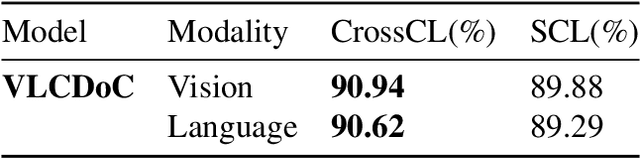
Multimodal learning from document data has achieved great success lately as it allows to pre-train semantically meaningful features as a prior into a learnable downstream approach. In this paper, we approach the document classification problem by learning cross-modal representations through language and vision cues, considering intra- and inter-modality relationships. Instead of merging features from different modalities into a common representation space, the proposed method exploits high-level interactions and learns relevant semantic information from effective attention flows within and across modalities. The proposed learning objective is devised between intra- and inter-modality alignment tasks, where the similarity distribution per task is computed by contracting positive sample pairs while simultaneously contrasting negative ones in the common feature representation space}. Extensive experiments on public document classification datasets demonstrate the effectiveness and the generalization capacity of our model on both low-scale and large-scale datasets.
A Generic Image Retrieval Method for Date Estimation of Historical Document Collections
Apr 08, 2022



Date estimation of historical document images is a challenging problem, with several contributions in the literature that lack of the ability to generalize from one dataset to others. This paper presents a robust date estimation system based in a retrieval approach that generalizes well in front of heterogeneous collections. we use a ranking loss function named smooth-nDCG to train a Convolutional Neural Network that learns an ordination of documents for each problem. One of the main usages of the presented approach is as a tool for historical contextual retrieval. It means that scholars could perform comparative analysis of historical images from big datasets in terms of the period where they were produced. We provide experimental evaluation on different types of documents from real datasets of manuscript and newspaper images.
Identity Document and banknote security forensics: a survey
Oct 20, 2019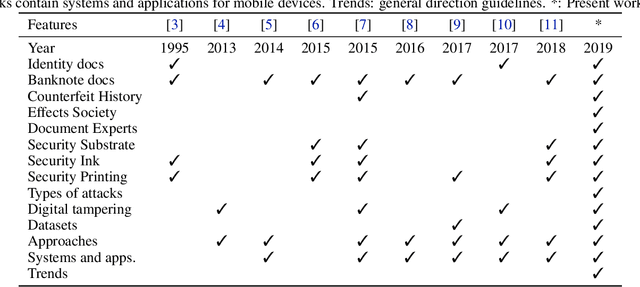
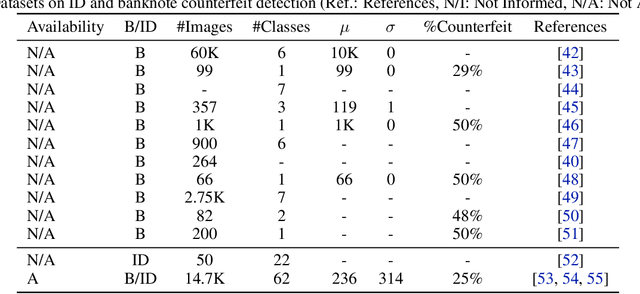


Counterfeiting and piracy are a form of theft that has been steadily growing in recent years. Banknotes and identity documents are two common objects of counterfeiting. Aiming to detect these counterfeits, the present survey covers a wide range of anti-counterfeiting security features, categorizing them into three components: security substrate, security inks and security printing. respectively. From the computer vision perspective, we present works in the literature covering these three categories. Other topics, such as history of counterfeiting, effects on society and document experts, counterfeiter types of attacks, trends among others are covered. Therefore, from non-experienced to professionals in security documents, can be introduced or deepen its knowledge in anti-counterfeiting measures.
A probabilistic framework for handwritten text line segmentation
May 15, 2018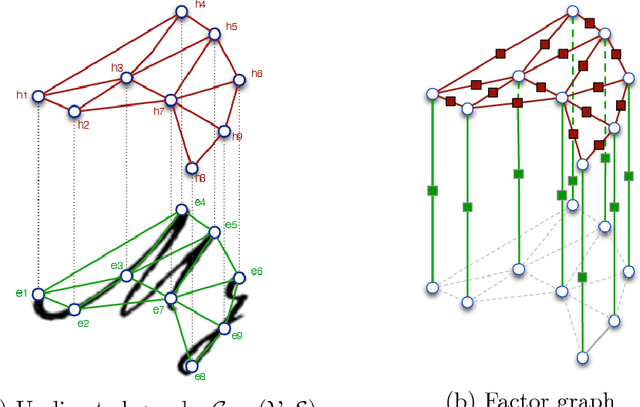
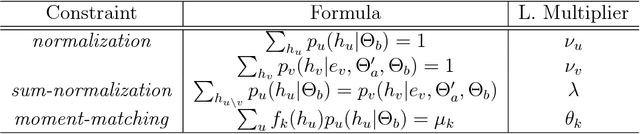
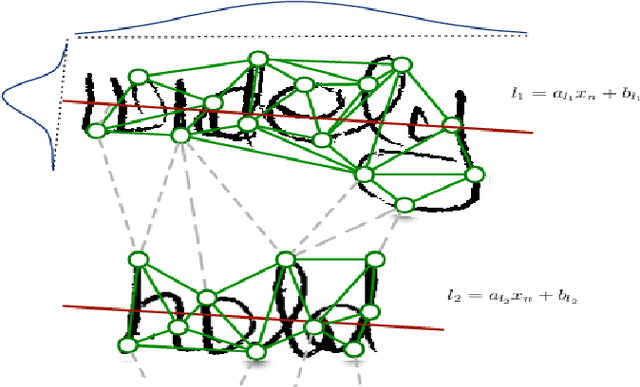

We successfully combine Expectation-Maximization algorithm and variational approaches for parameter learning and computing inference on Markov random felds. This is a general method that can be applied to many computer vision tasks. In this paper, we apply it to handwritten text line segmentation. We conduct several experiments that demonstrate that our method deal with common issues of this task, such as complex document layout or non-latin scripts. The obtained results prove that our method achieve state-of-the-art performance on different benchmark datasets without any particular fine tuning step.