 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUEST: Quality-aware Semi-supervised Table Extraction for Business Documents
Jun 17, 2025Automating table extraction (TE) from business documents is critical for industrial workflows but remains challenging due to sparse annotations and error-prone multi-stage pipelines. While semi-supervised learning (SSL) can leverage unlabeled data, existing methods rely on confidence scores that poorly reflect extraction quality. We propose QUEST, a Quality-aware Semi-supervised Table extraction framework designed for business documents. QUEST introduces a novel quality assessment model that evaluates structural and contextual features of extracted tables, trained to predict F1 scores instead of relying on confidence metrics. This quality-aware approach guides pseudo-label selection during iterative SSL training, while diversity measures (DPP, Vendi score, IntDiv) mitigate confirmation bias. Experiments on a proprietary business dataset (1000 annotated + 10000 unannotated documents) show QUEST improves F1 from 64% to 74% and reduces empty predictions by 45% (from 12% to 6.5%). On the DocILE benchmark (600 annotated + 20000 unannotated documents), QUEST achieves a 50% F1 score (up from 42%) and reduces empty predictions by 19% (from 27% to 22%). The framework's interpretable quality assessments and robustness to annotation scarcity make it particularly suited for business documents, where structural consistency and data completeness are paramount.
RAPTOR: Refined Approach for Product Table Object Recognition
Feb 24, 2025Extracting tables from documents is a critical task across various industries, especially on business documents like invoices and reports. Existing systems based on DEtection TRansformer (DETR) such as TAble TRansformer (TATR), offer solutions for Table Detection (TD) and Table Structure Recognition (TSR) but face challenges with diverse table formats and common errors like incorrect area detection and overlapping columns. This research introduces RAPTOR, a modular post-processing system designed to enhance state-of-the-art models for improved table extraction, particularly for product tables. RAPTOR addresses recurrent TD and TSR issues, improving both precision and structural predictions. For TD, we use DETR (trained on ICDAR 2019) and TATR (trained on PubTables-1M and FinTabNet), while TSR only relies on TATR. A Genetic Algorithm is incorporated to optimize RAPTOR's module parameters, using a private dataset of product tables to align with industrial needs. We evaluate our method on two private datasets of product tables, the public DOCILE dataset (which contains tables similar to our target product tables), and the ICDAR 2013 and ICDAR 2019 datasets. The results demonstrate that while our approach excels at product tables, it also maintains reasonable performance across diverse table formats. An ablation study further validates the contribution of each module in our system.
TransferDoc: A Self-Supervised Transferable Document Representation Learning Model Unifying Vision and Language
Sep 11, 2023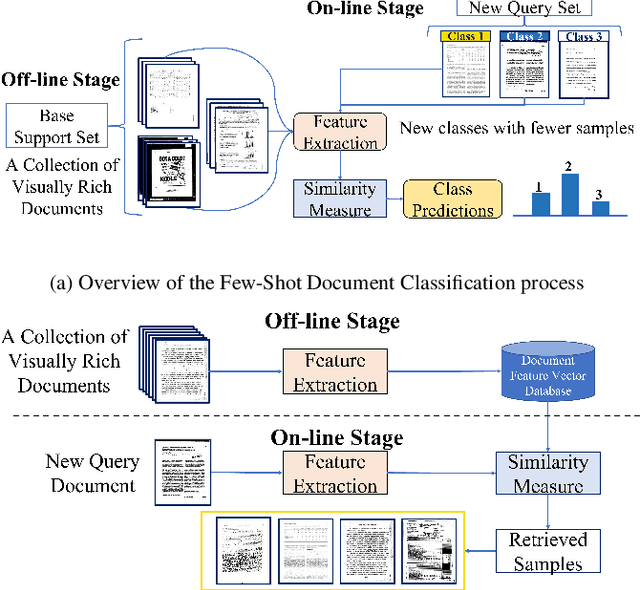
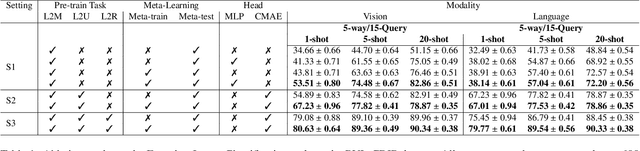
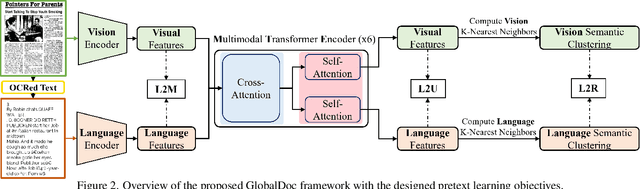

The field of visual document understanding has witnessed a rapid growth in emerging challenges and powerful multi-modal strategies. However, they rely on an extensive amount of document data to learn their pretext objectives in a ``pre-train-then-fine-tune'' paradigm and thus, suffer a significant performance drop in real-world online industrial settings. One major reason is the over-reliance on OCR engines to extract local positional information within a document page. Therefore, this hinders the model's generalizability, flexibility and robustness due to the lack of capturing global information within a document image. We introduce TransferDoc, a cross-modal transformer-based architecture pre-trained in a self-supervised fashion using three novel pretext objectives. TransferDoc learns richer semantic concepts by unifying language and visual representations, which enables the production of more transferable models. Besides, two novel downstream tasks have been introduced for a ``closer-to-real'' industrial evaluation scenario where TransferDoc outperforms other state-of-the-art approaches.
EAML: Ensemble Self-Attention-based Mutual Learning Network for Document Image Classification
May 11, 2023In the recent past, complex deep neural networks have received huge interest in various document understanding tasks such as document image classification and document retrieval. As many document types have a distinct visual style, learning only visual features with deep CNNs to classify document images have encountered the problem of low inter-class discrimination, and high intra-class structural variations between its categories. In parallel, text-level understanding jointly learned with the corresponding visual properties within a given document image has considerably improved the classification performance in terms of accuracy. In this paper, we design a self-attention-based fusion module that serves as a block in our ensemble trainable network. It allows to simultaneously learn the discriminant features of image and text modalities throughout the training stage. Besides, we encourage mutual learning by transferring the positive knowledge between image and text modalities during the training stage. This constraint is realized by adding a truncated-Kullback-Leibler divergence loss Tr-KLD-Reg as a new regularization term, to the conventional supervised setting. To the best of our knowledge, this is the first time to leverage a mutual learning approach along with a self-attention-based fusion module to perform document image classification. The experimental results illustrate the effectiveness of our approach in terms of accuracy for the single-modal and multi-modal modalities. Thus, the proposed ensemble self-attention-based mutual learning model outperforms the state-of-the-art classification results based on the benchmark RVL-CDIP and Tobacco-3482 datasets.
CHIC: Corporate Document for Visual question Answering
May 01, 2023The massive use of digital documents due to the substantial trend of paperless initiatives confronted some companies to find ways to process thousands of documents per day automatically. To achieve this, they use automatic information retrieval (IR) allowing them to extract useful information from large datasets quickly. In order to have effective IR methods, it is first necessary to have an adequate dataset. Although companies have enough data to take into account their needs, there is also a need for a public database to compare contributions between state-of-the-art methods. Public data on the document exists as DocVQA[2] and XFUND [10], but these do not fully satisfy the needs of companies. XFUND contains only form documents while the company uses several types of documents (i.e. structured documents like forms but also semi-structured as invoices, and unstructured as emails). Compared to XFUND, DocVQA has several types of documents but only 4.5% of them are corporate documents (i.e. invoice, purchase order, etc). All of this 4.5% of documents do not meet the diversity of documents required by the company. We propose CHIC a visual question-answering public dataset. This dataset contains different types of corporate documents and the information extracted from these documents meet the right expectations of companies.
VLCDoC: Vision-Language Contrastive Pre-Training Model for Cross-Modal Document Classification
May 24, 2022
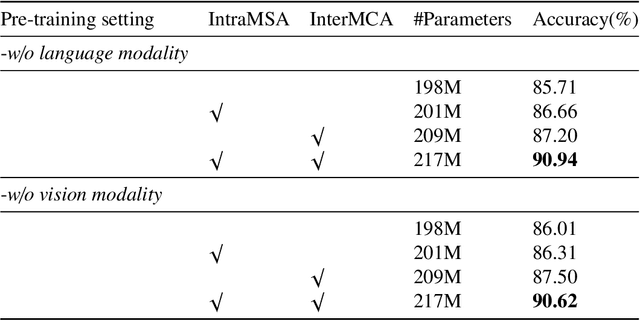
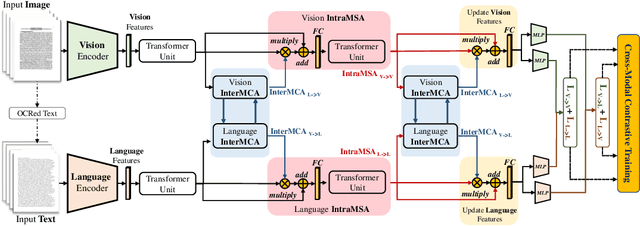
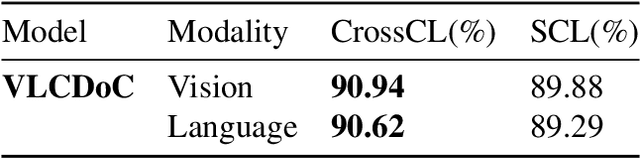
Multimodal learning from document data has achieved great success lately as it allows to pre-train semantically meaningful features as a prior into a learnable downstream approach. In this paper, we approach the document classification problem by learning cross-modal representations through language and vision cues, considering intra- and inter-modality relationships. Instead of merging features from different modalities into a common representation space, the proposed method exploits high-level interactions and learns relevant semantic information from effective attention flows within and across modalities. The proposed learning objective is devised between intra- and inter-modality alignment tasks, where the similarity distribution per task is computed by contracting positive sample pairs while simultaneously contrasting negative ones in the common feature representation space}. Extensive experiments on public document classification datasets demonstrate the effectiveness and the generalization capacity of our model on both low-scale and large-scale datasets.
Evaluation of Neural Network Classification Systems on Document Stream
Jul 15, 2020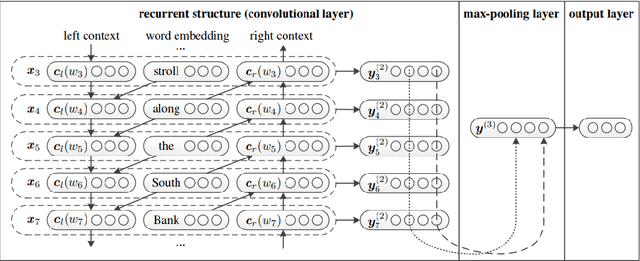
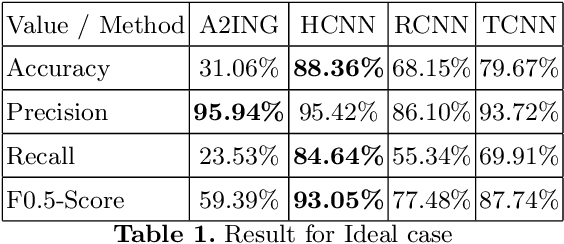
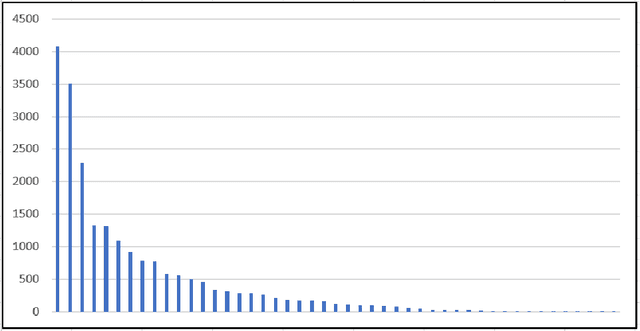
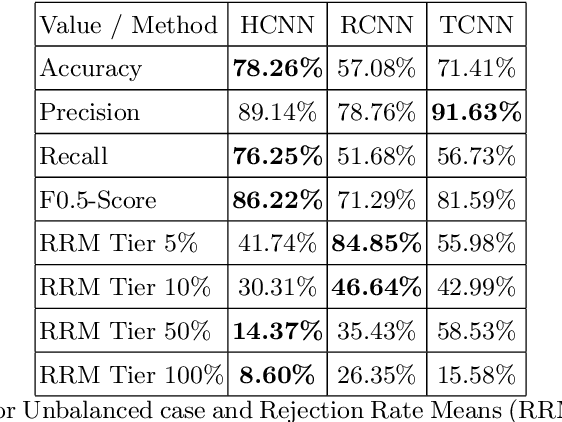
One major drawback of state of the art Neural Networks (NN)-based approaches for document classification purposes is the large number of training samples required to obtain an efficient classification. The minimum required number is around one thousand annotated documents for each class. In many cases it is very difficult, if not impossible, to gather this number of samples in real industrial processes. In this paper, we analyse the efficiency of NN-based document classification systems in a sub-optimal training case, based on the situation of a company document stream. We evaluated three different approaches, one based on image content and two on textual content. The evaluation was divided into four parts: a reference case, to assess the performance of the system in the lab; two cases that each simulate a specific difficulty linked to document stream processing; and a realistic case that combined all of these difficulties. The realistic case highlighted the fact that there is a significant drop in the efficiency of NN-Based document classification systems. Although they remain efficient for well represented classes (with an over-fitting of the system for those classes), it is impossible for them to handle appropriately less well represented classes. NN-Based document classification systems need to be adapted to resolve these two problems before they can be considered for use in a company document stream.