 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-PerceptCT: Deep Perceptual Enhancement for Low-Dose CT Images
Nov 18, 2025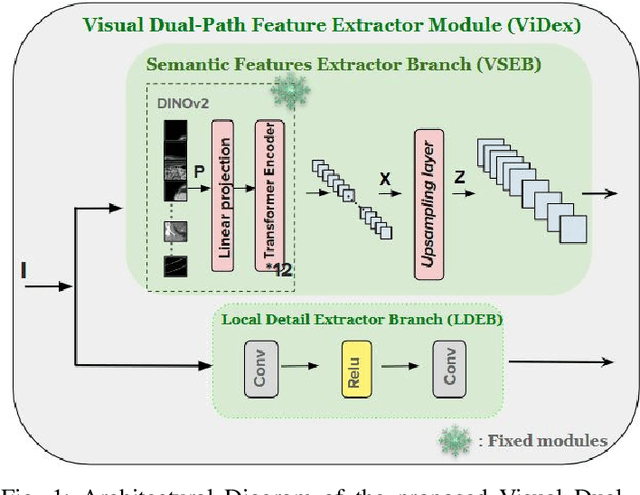
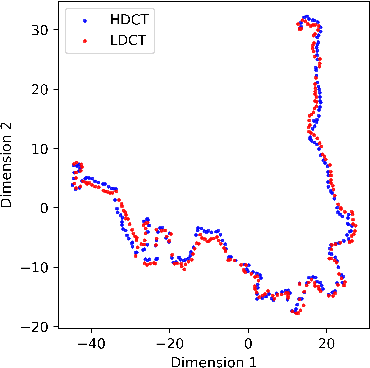
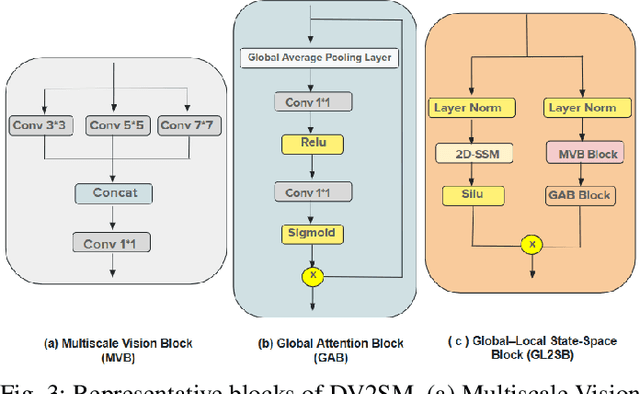
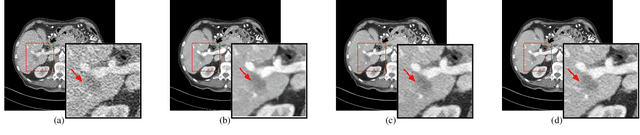
Low Dose Computed Tomography (LDCT) is widely used as an imaging solution to aid diagnosis and other clinical tasks. However, this comes at the price of a deterioration in image quality due to the low dose of radiation used to reduce the risk of secondary cancer development. While some efficient methods have been proposed to enhance LDCT quality, many overestimate noise and perform excessive smoothing, leading to a loss of critical details. In this paper, we introduce D-PerceptCT, a novel architecture inspired by key principles of the Human Visual System (HVS) to enhance LDCT images. The objective is to guide the model to enhance or preserve perceptually relevant features, thereby providing radiologists with CT images where critical anatomical structures and fine pathological details are perceptu- ally visible. D-PerceptCT consists of two main blocks: 1) a Visual Dual-path Extractor (ViDex), which integrates semantic priors from a pretrained DINOv2 model with local spatial features, allowing the network to incorporate semantic-awareness during enhancement; (2) a Global-Local State-Space block that captures long-range information and multiscale features to preserve the important structures and fine details for diagnosis. In addition, we propose a novel deep perceptual loss, designated as the Deep Perceptual Relevancy Loss Function (DPRLF), which is inspired by human contrast sensitivity, to further emphasize perceptually important features. Extensive experiments on the Mayo2016 dataset demonstrate the effectiveness of D-PerceptCT method for LDCT enhancement, showing better preservation of structural and textural information within LDCT images compared to SOTA methods.
Interactive Masked Image Modeling for Multimodal Object Detection in Remote Sensing
Sep 13, 2024Object detection in remote sensing imagery plays a vital role in various Earth observation applications. However, unlike object detection in natural scene images, this task is particularly challenging due to the abundance of small, often barely visible objects across diverse terrains. To address these challenges, multimodal learning can be used to integrate features from different data modalities, thereby improving detection accuracy. Nonetheless, the performance of multimodal learning is often constrained by the limited size of labeled datasets. In this paper, we propose to use Masked Image Modeling (MIM) as a pre-training technique, leveraging self-supervised learning on unlabeled data to enhance detection performance. However, conventional MIM such as MAE which uses masked tokens without any contextual information, struggles to capture the fine-grained details due to a lack of interactions with other parts of image. To address this, we propose a new interactive MIM method that can establish interactions between different tokens, which is particularly beneficial for object detection in remote sensing. The extensive ablation studies and evluation demonstrate the effectiveness of our approach.
Multimodal Transformer Using Cross-Channel attention for Object Detection in Remote Sensing Images
Oct 21, 2023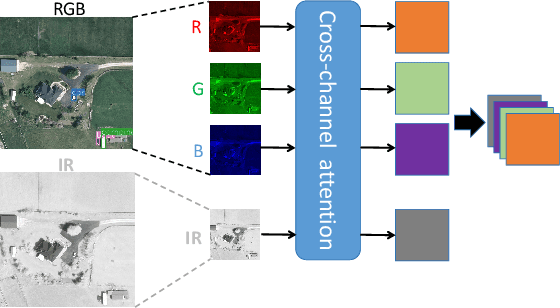



Object detection in Remote Sensing Images (RSI) is a critical task for numerous applications in Earth Observation (EO). Unlike general object detection, object detection in RSI has specific challenges: 1) the scarcity of labeled data in RSI compared to general object detection datasets, and 2) the small objects presented in a high-resolution image with a vast background. To address these challenges, we propose a multimodal transformer exploring multi-source remote sensing data for object detection. Instead of directly combining the multimodal input through a channel-wise concatenation, which ignores the heterogeneity of different modalities, we propose a cross-channel attention module. This module learns the relationship between different channels, enabling the construction of a coherent multimodal input by aligning the different modalities at the early stage. We also introduce a new architecture based on the Swin transformer that incorporates convolution layers in non-shifting blocks while maintaining fixed dimensions, allowing for the generation of fine-to-coarse representations with a favorable accuracy-computation trade-off. The extensive experiments prove the effectiveness of the proposed multimodal fusion module and architecture, demonstrating their applicability to multimodal aerial imagery.
TransferDoc: A Self-Supervised Transferable Document Representation Learning Model Unifying Vision and Language
Sep 11, 2023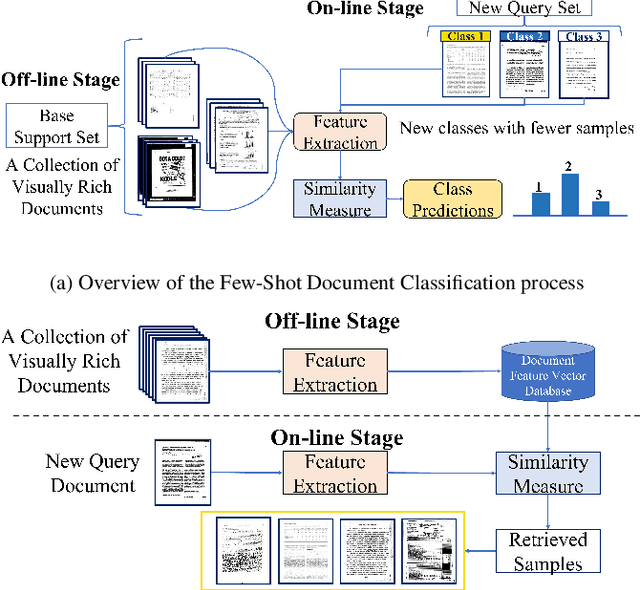
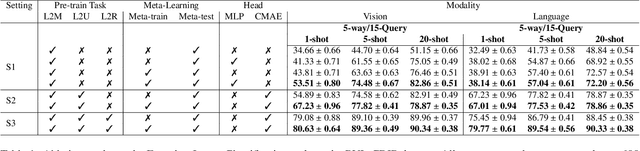
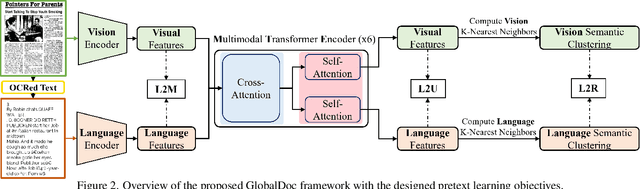

The field of visual document understanding has witnessed a rapid growth in emerging challenges and powerful multi-modal strategies. However, they rely on an extensive amount of document data to learn their pretext objectives in a ``pre-train-then-fine-tune'' paradigm and thus, suffer a significant performance drop in real-world online industrial settings. One major reason is the over-reliance on OCR engines to extract local positional information within a document page. Therefore, this hinders the model's generalizability, flexibility and robustness due to the lack of capturing global information within a document image. We introduce TransferDoc, a cross-modal transformer-based architecture pre-trained in a self-supervised fashion using three novel pretext objectives. TransferDoc learns richer semantic concepts by unifying language and visual representations, which enables the production of more transferable models. Besides, two novel downstream tasks have been introduced for a ``closer-to-real'' industrial evaluation scenario where TransferDoc outperforms other state-of-the-art approaches.
MMFormer: Multimodal Transformer Using Multiscale Self-Attention for Remote Sensing Image Classification
Mar 23, 2023



To benefit the complementary information between heterogeneous data, we introduce a new Multimodal Transformer (MMFormer) for Remote Sensing (RS) image classification using Hyperspectral Image (HSI) accompanied by another source of data such as Light Detection and Ranging (LiDAR). Compared with traditional Vision Transformer (ViT) lacking inductive biases of convolutions, we first introduce convolutional layers to our MMFormer to tokenize patches from multimodal data of HSI and LiDAR. Then we propose a Multi-scale Multi-head Self-Attention (MSMHSA) module to address the problem of compatibility which often limits to fuse HSI with high spectral resolution and LiDAR with relatively low spatial resolution. The proposed MSMHSA module can incorporate HSI to LiDAR data in a coarse-to-fine manner enabling us to learn a fine-grained representation. Extensive experiments on widely used benchmarks (e.g., Trento and MUUFL) demonstrate the effectiveness and superiority of our proposed MMFormer for RS image classification.
Identity Documents Authentication based on Forgery Detection of Guilloche Pattern
Jun 22, 2022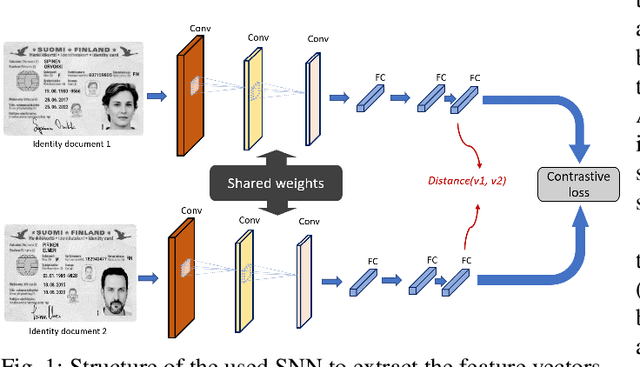

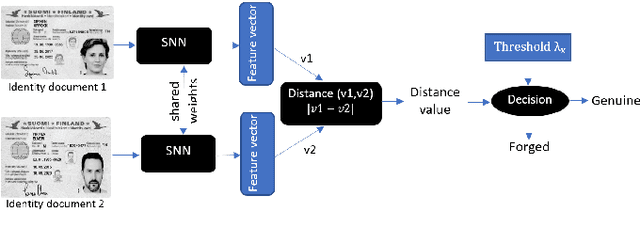

In cases such as digital enrolment via mobile and online services, identity document verification is critical in order to efficiently detect forgery and therefore build user trust in the digital world. In this paper, an authentication model for identity documents based on forgery detection of guilloche patterns is proposed. The proposed approach is made up of two steps: feature extraction and similarity measure between a pair of feature vectors of identity documents. The feature extraction step involves learning the similarity between a pair of identity documents via a convolutional neural network (CNN) architecture and ends by extracting highly discriminative features between them. While, the similarity measure step is applied to decide if a given identity document is authentic or forged. In this work, these two steps are combined together to achieve two objectives: (i) extracted features should have good anticollision (discriminative) capabilities to distinguish between a pair of identity documents belonging to different classes, (ii) checking out the conformity of the guilloche pattern of a given identity document and its similarity to the guilloche pattern of an authentic version of the same country. Experiments are conducted in order to analyze and identify the most proper parameters to achieve higher authentication performance. The experimental results are performed on the MIDV-2020 dataset. The results show the ability of the proposed approach to extract the relevant characteristics of the processed pair of identity documents in order to model the guilloche patterns, and thus distinguish them correctly. The implementation code and the forged dataset are provided here (https://drive.google.com/id-FDGP-1)
VLCDoC: Vision-Language Contrastive Pre-Training Model for Cross-Modal Document Classification
May 24, 2022
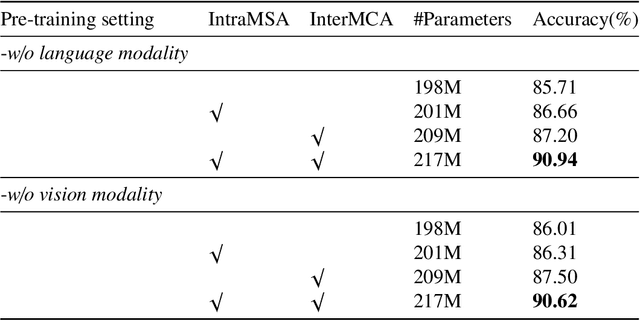
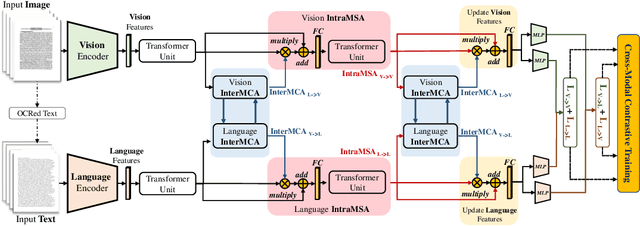
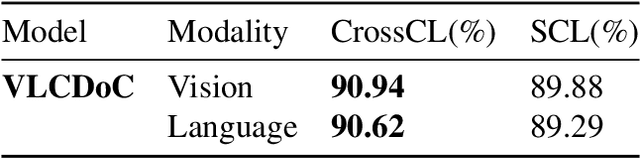
Multimodal learning from document data has achieved great success lately as it allows to pre-train semantically meaningful features as a prior into a learnable downstream approach. In this paper, we approach the document classification problem by learning cross-modal representations through language and vision cues, considering intra- and inter-modality relationships. Instead of merging features from different modalities into a common representation space, the proposed method exploits high-level interactions and learns relevant semantic information from effective attention flows within and across modalities. The proposed learning objective is devised between intra- and inter-modality alignment tasks, where the similarity distribution per task is computed by contracting positive sample pairs while simultaneously contrasting negative ones in the common feature representation space}. Extensive experiments on public document classification datasets demonstrate the effectiveness and the generalization capacity of our model on both low-scale and large-scale datasets.
ViTransPAD: Video Transformer using convolution and self-attention for Face Presentation Attack Detection
Mar 14, 2022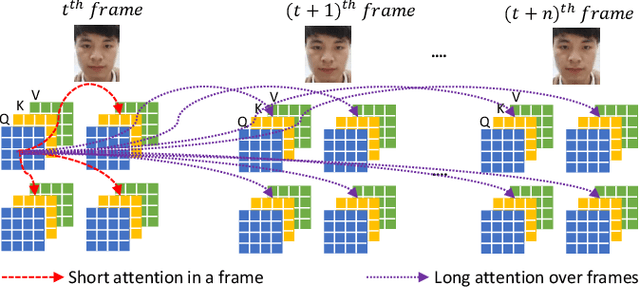
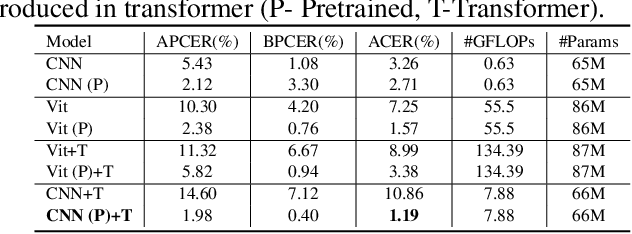
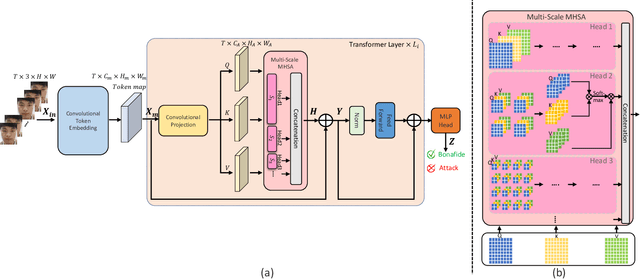
Face Presentation Attack Detection (PAD) is an important measure to prevent spoof attacks for face biometric systems. Many works based on Convolution Neural Networks (CNNs) for face PAD formulate the problem as an image-level binary classification task without considering the context. Alternatively, Vision Transformers (ViT) using self-attention to attend the context of an image become the mainstreams in face PAD. Inspired by ViT, we propose a Video-based Transformer for face PAD (ViTransPAD) with short/long-range spatio-temporal attention which can not only focus on local details with short attention within a frame but also capture long-range dependencies over frames. Instead of using coarse image patches with single-scale as in ViT, we propose the Multi-scale Multi-Head Self-Attention (MsMHSA) architecture to accommodate multi-scale patch partitions of Q, K, V feature maps to the heads of transformer in a coarse-to-fine manner, which enables to learn a fine-grained representation to perform pixel-level discrimination for face PAD. Due to lack inductive biases of convolutions in pure transformers, we also introduce convolutions to the proposed ViTransPAD to integrate the desirable properties of CNNs by using convolution patch embedding and convolution projection. The extensive experiments show the effectiveness of our proposed ViTransPAD with a preferable accuracy-computation balance, which can serve as a new backbone for face PAD.
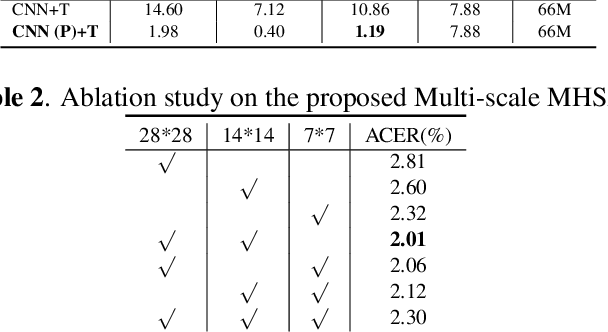
Exploring Multi-Tasking Learning in Document Attribute Classification
Aug 30, 2021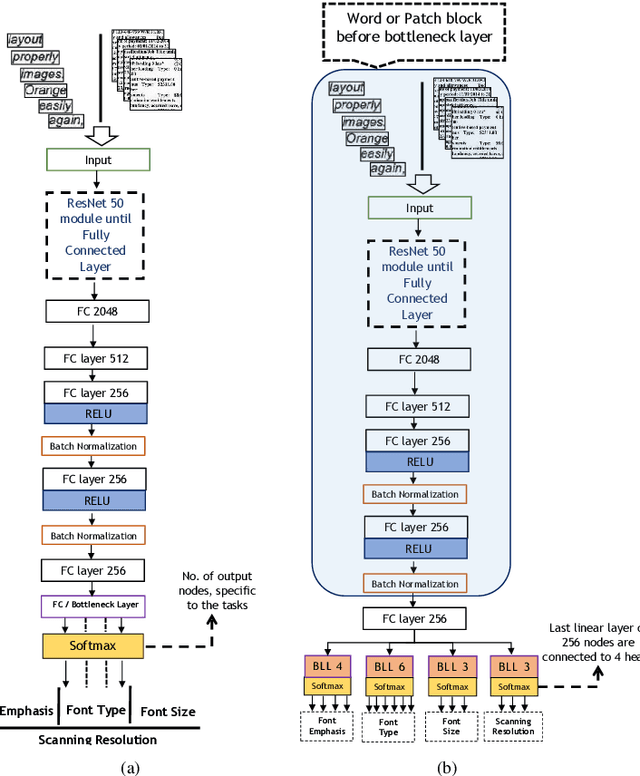
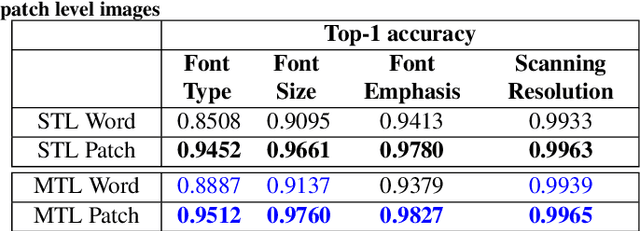
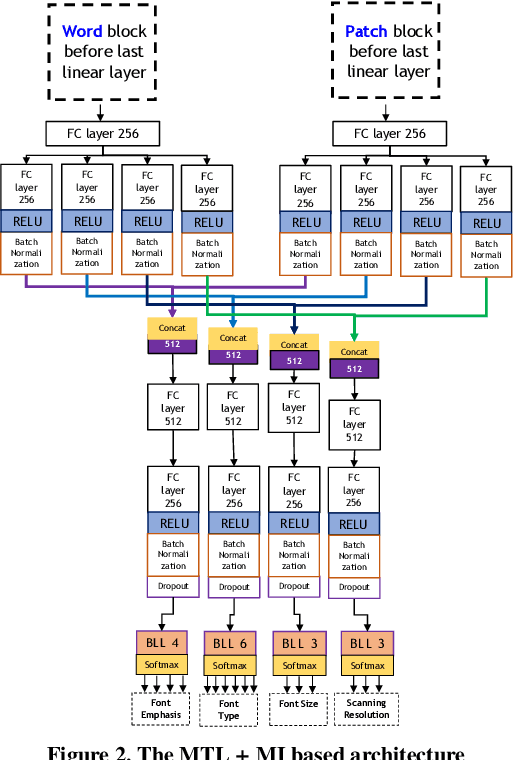

In this work, we adhere to explore a Multi-Tasking learning (MTL) based network to perform document attribute classification such as the font type, font size, font emphasis and scanning resolution classification of a document image. To accomplish these tasks, we operate on either segmented word level or on uniformed size patches randomly cropped out of the document. Furthermore, a hybrid convolution neural network (CNN) architecture "MTL+MI", which is based on the combination of MTL and Multi-Instance (MI) of patch and word is used to accomplish joint learning for the classification of the same document attributes. The contribution of this paper are three fold: firstly, based on segmented word images and patches, we present a MTL based network for the classification of a full document image. Secondly, we propose a MTL and MI (using segmented words and patches) based combined CNN architecture ("MTL+MI") for the classification of same document attributes. Thirdly, based on the multi-tasking classifications of the words and/or patches, we propose an intelligent voting system which is based on the posterior probabilities of each words and/or patches to perform the classification of document's attributes of complete document image.
MIDV-2020: A Comprehensive Benchmark Dataset for Identity Document Analysis
Jul 01, 2021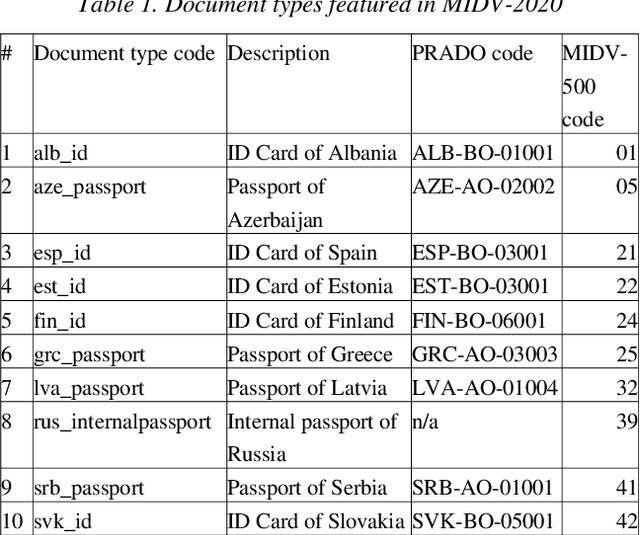

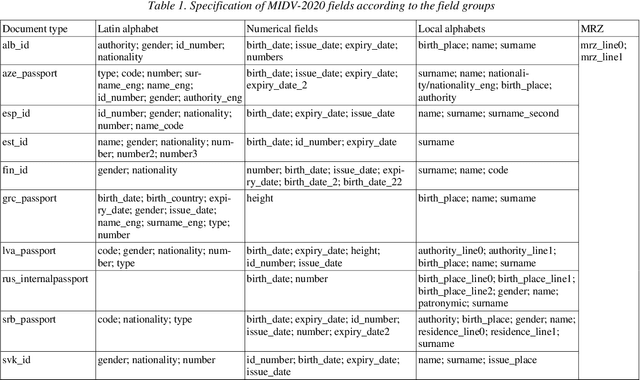

Identity documents recognition is an important sub-field of document analysis, which deals with tasks of robust document detection, type identification, text fields recognition, as well as identity fraud prevention and document authenticity validation given photos, scans, or video frames of an identity document capture. Significant amount of research has been published on this topic in recent years, however a chief difficulty for such research is scarcity of datasets, due to the subject matter being protected by security requirements. A few datasets of identity documents which are available lack diversity of document types, capturing conditions, or variability of document field values. In addition, the published datasets were typically designed only for a subset of document recognition problems, not for a complex identity document analysis. In this paper, we present a dataset MIDV-2020 which consists of 1000 video clips, 2000 scanned images, and 1000 photos of 1000 unique mock identity documents, each with unique text field values and unique artificially generated faces, with rich annotation. For the presented benchmark dataset baselines are provided for such tasks as document location and identification, text fields recognition, and face detection. With 72409 annotated images in total, to the date of publication the proposed dataset is the largest publicly available identity documents dataset with variable artificially generated data, and we believe that it will prove invaluable for advancement of the field of document analysis and recognition. The dataset is available for download at ftp://smartengines.com/midv-2020 and http://l3i-share.univ-lr.fr .