 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoughToRadon Transform: New Neural Network Layer for Features Improvement in Projection Space
Feb 05, 2024In this paper, we introduce HoughToRadon Transform layer, a novel layer designed to improve the speed of neural networks incorporated with Hough Transform to solve semantic image segmentation problems. By placing it after a Hough Transform layer, "inner" convolutions receive modified feature maps with new beneficial properties, such as a smaller area of processed images and parameter space linearity by angle and shift. These properties were not presented in Hough Transform alone. Furthermore, HoughToRadon Transform layer allows us to adjust the size of intermediate feature maps using two new parameters, thus allowing us to balance the speed and quality of the resulting neural network. Our experiments on the open MIDV-500 dataset show that this new approach leads to time savings in document segmentation tasks and achieves state-of-the-art 97.7% accuracy, outperforming HoughEncoder with larger computational complexity.
MIDV-2020: A Comprehensive Benchmark Dataset for Identity Document Analysis
Jul 01, 2021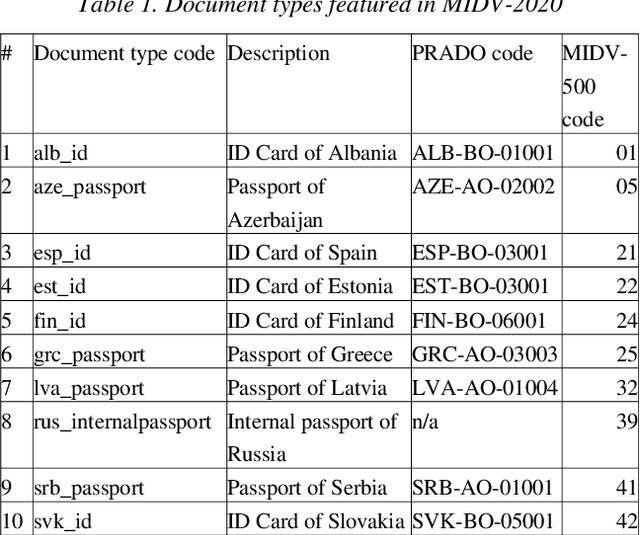

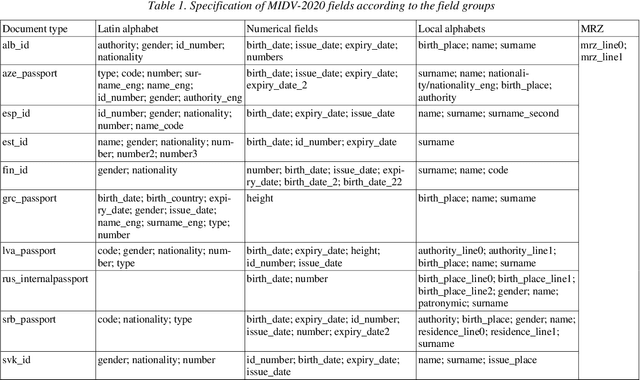

Identity documents recognition is an important sub-field of document analysis, which deals with tasks of robust document detection, type identification, text fields recognition, as well as identity fraud prevention and document authenticity validation given photos, scans, or video frames of an identity document capture. Significant amount of research has been published on this topic in recent years, however a chief difficulty for such research is scarcity of datasets, due to the subject matter being protected by security requirements. A few datasets of identity documents which are available lack diversity of document types, capturing conditions, or variability of document field values. In addition, the published datasets were typically designed only for a subset of document recognition problems, not for a complex identity document analysis. In this paper, we present a dataset MIDV-2020 which consists of 1000 video clips, 2000 scanned images, and 1000 photos of 1000 unique mock identity documents, each with unique text field values and unique artificially generated faces, with rich annotation. For the presented benchmark dataset baselines are provided for such tasks as document location and identification, text fields recognition, and face detection. With 72409 annotated images in total, to the date of publication the proposed dataset is the largest publicly available identity documents dataset with variable artificially generated data, and we believe that it will prove invaluable for advancement of the field of document analysis and recognition. The dataset is available for download at ftp://smartengines.com/midv-2020 and http://l3i-share.univ-lr.fr .
Computational optimization of convolutional neural networks using separated filters architecture
Feb 18, 2020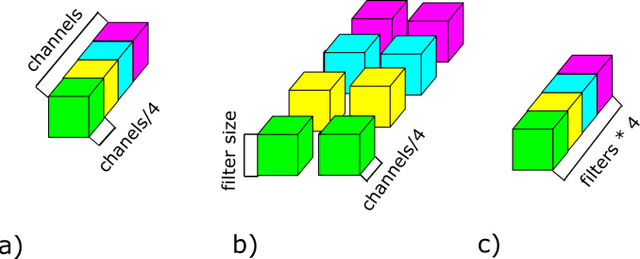


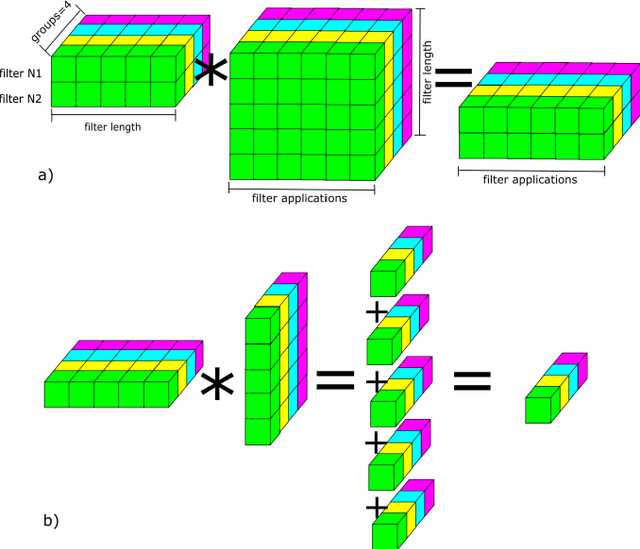
This paper considers a convolutional neural network transformation that reduces computation complexity and thus speedups neural network processing. Usage of convolutional neural networks (CNN) is the standard approach to image recognition despite the fact they can be too computationally demanding, for example for recognition on mobile platforms or in embedded systems. In this paper we propose CNN structure transformation which expresses 2D convolution filters as a linear combination of separable filters. It allows to obtain separated convolutional filters by standard training algorithms. We study the computation efficiency of this structure transformation and suggest fast implementation easily handled by CPU or GPU. We demonstrate that CNNs designed for letter and digit recognition of proposed structure show 15% speedup without accuracy loss in industrial image recognition system. In conclusion, we discuss the question of possible accuracy decrease and the application of proposed transformation to different recognition problems. convolutional neural networks, computational optimization, separable filters, complexity reduction.
* 4 pages, 3 figures
HoughNet: neural network architecture for vanishing points detection
Oct 06, 2019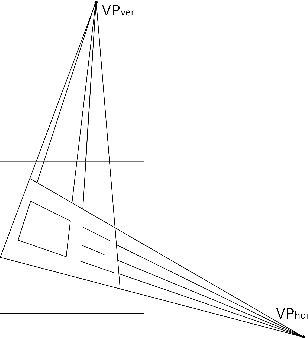



In this paper we introduce a novel neural network architecture based on Fast Hough Transform layer. The layer of this type allows our neural network to accumulate features from linear areas across the entire image instead of local areas. We demonstrate its potential by solving the problem of vanishing points detection in the images of documents. Such problem occurs when dealing with camera shots of the documents in uncontrolled conditions. In this case, the document image can suffer several specific distortions including projective transform. To train our model, we use MIDV-500 dataset and provide testing results. The strong generalization ability of the suggested method is proven with its applying to a completely different ICDAR 2011 dewarping contest. In previously published papers considering these dataset authors measured the quality of vanishing point detection by counting correctly recognized words with open OCR engine Tesseract. To compare with them, we reproduce this experiment and show that our method outperforms the state-of-the-art result.
* 6 pages, 6 figures, 2 tables, 28 references, conference