 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast matrix multiplication for binary and ternary CNNs on ARM CPU
May 18, 2022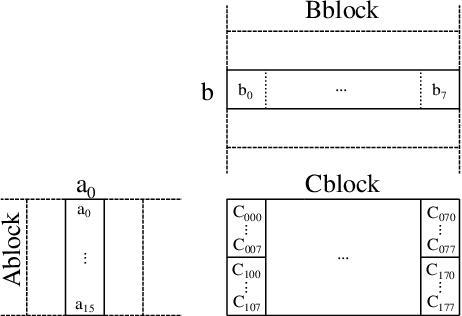
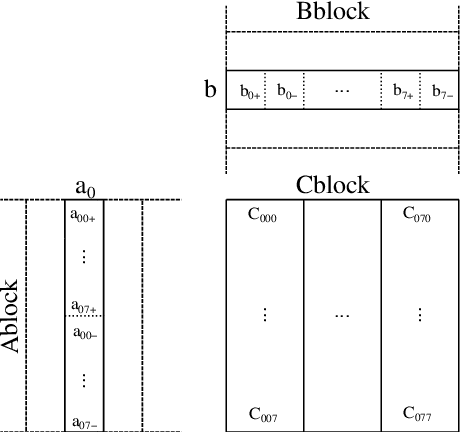
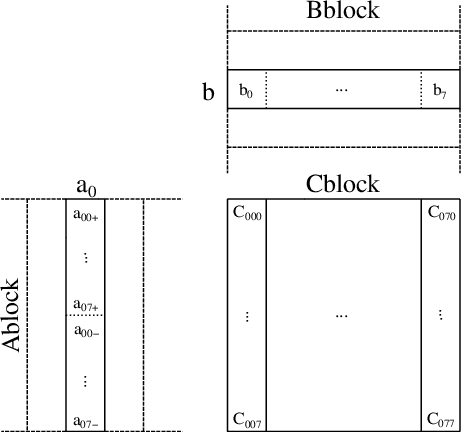

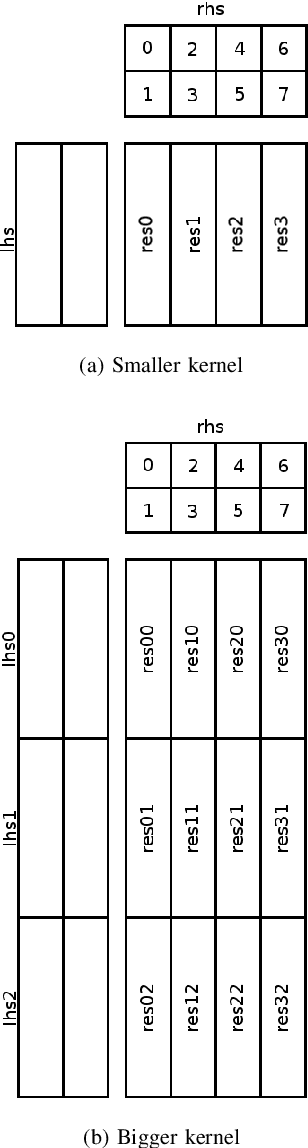
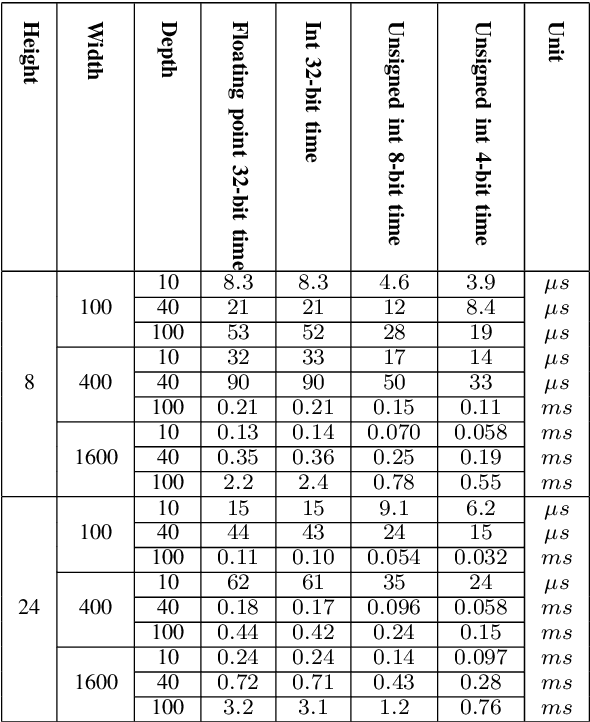
Low-bit quantized neural networks are of great interest in practical applications because they significantly reduce the consumption of both memory and computational resources. Binary neural networks are memory and computationally efficient as they require only one bit per weight and activation and can be computed using Boolean logic and bit count operations. QNNs with ternary weights and activations and binary weights and ternary activations aim to improve recognition quality compared to BNNs while preserving low bit-width. However, their efficient implementation is usually considered on ASICs and FPGAs, limiting their applicability in real-life tasks. At the same time, one of the areas where efficient recognition is most in demand is recognition on mobile devices using their CPUs. However, there are no known fast implementations of TBNs and TNN, only the daBNN library for BNNs inference. In this paper, we propose novel fast algorithms of ternary, ternary-binary, and binary matrix multiplication for mobile devices with ARM architecture. In our algorithms, ternary weights are represented using 2-bit encoding and binary - using one bit. It allows us to replace matrix multiplication with Boolean logic operations that can be computed on 128-bits simultaneously, using ARM NEON SIMD extension. The matrix multiplication results are accumulated in 16-bit integer registers. We also use special reordering of values in left and right matrices. All that allows us to efficiently compute a matrix product while minimizing the number of loads and stores compared to the algorithm from daBNN. Our algorithms can be used to implement inference of convolutional and fully connected layers of TNNs, TBNs, and BNNs. We evaluate them experimentally on ARM Cortex-A73 CPU and compare their inference speed to efficient implementations of full-precision, 8-bit, and 4-bit quantized matrix multiplications.
ResNet-like Architecture with Low Hardware Requirements
Sep 15, 2020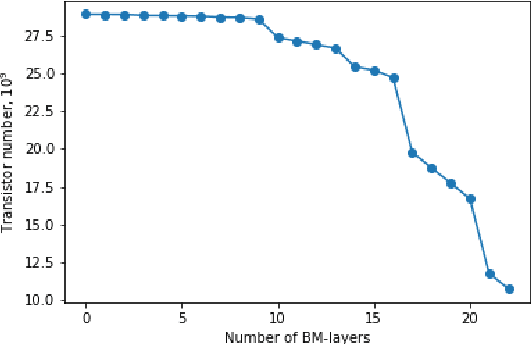
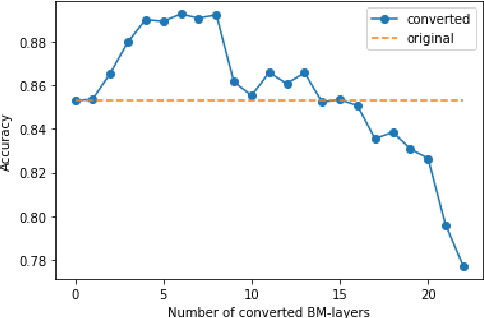
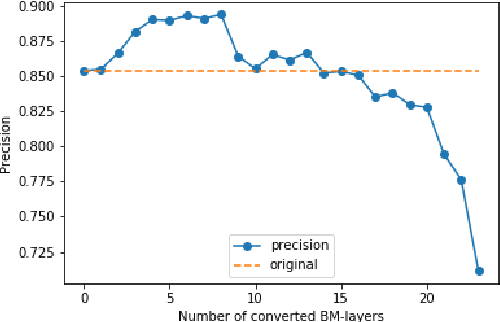
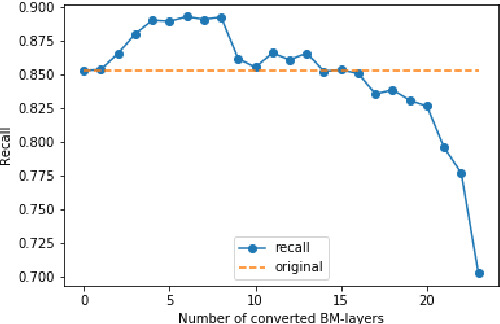
One of the most computationally intensive parts in modern recognition systems is an inference of deep neural networks that are used for image classification, segmentation, enhancement, and recognition. The growing popularity of edge computing makes us look for ways to reduce its time for mobile and embedded devices. One way to decrease the neural network inference time is to modify a neuron model to make it moreefficient for computations on a specific device. The example ofsuch a model is a bipolar morphological neuron model. The bipolar morphological neuron is based on the idea of replacing multiplication with addition and maximum operations. This model has been demonstrated for simple image classification with LeNet-like architectures [1]. In the paper, we introduce a bipolar morphological ResNet (BM-ResNet) model obtained from a much more complex ResNet architecture by converting its layers to bipolar morphological ones. We apply BM-ResNet to image classification on MNIST and CIFAR-10 datasets with only a moderate accuracy decrease from 99.3% to 99.1% and from 85.3% to 85.1%. We also estimate the computational complexity of the resulting model. We show that for the majority of ResNet layers, the considered model requires 2.1-2.9 times fewer logic gates for implementation and 15-30% lower latency.
Fast Implementation of 4-bit Convolutional Neural Networks for Mobile Devices
Sep 14, 2020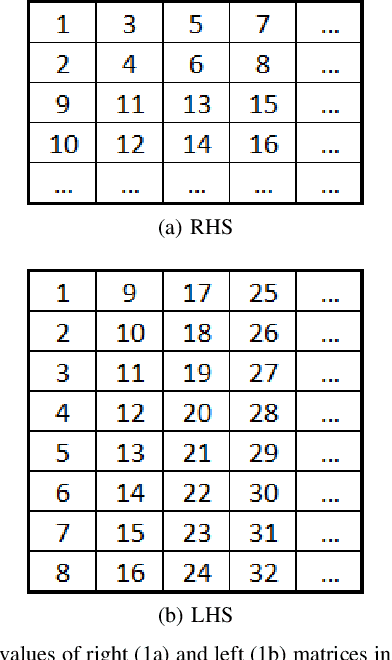

Quantized low-precision neural networks are very popular because they require less computational resources for inference and can provide high performance, which is vital for real-time and embedded recognition systems. However, their advantages are apparent for FPGA and ASIC devices, while general-purpose processor architectures are not always able to perform low-bit integer computations efficiently. The most frequently used low-precision neural network model for mobile central processors is an 8-bit quantized network. However, in a number of cases, it is possible to use fewer bits for weights and activations, and the only problem is the difficulty of efficient implementation. We introduce an efficient implementation of 4-bit matrix multiplication for quantized neural networks and perform time measurements on a mobile ARM processor. It shows 2.9 times speedup compared to standard floating-point multiplication and is 1.5 times faster than 8-bit quantized one. We also demonstrate a 4-bit quantized neural network for OCR recognition on the MIDV-500 dataset. 4-bit quantization gives 95.0% accuracy and 48% overall inference speedup, while an 8-bit quantized network gives 95.4% accuracy and 39% speedup. The results show that 4-bit quantization perfectly suits mobile devices, yielding good enough accuracy and low inference time.
Fast Implementation of Morphological Filtering Using ARM NEON Extension
Feb 19, 2020

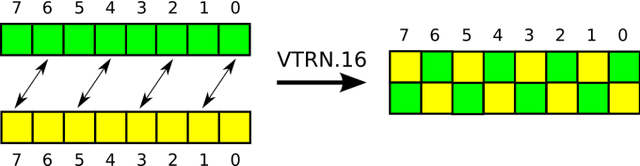
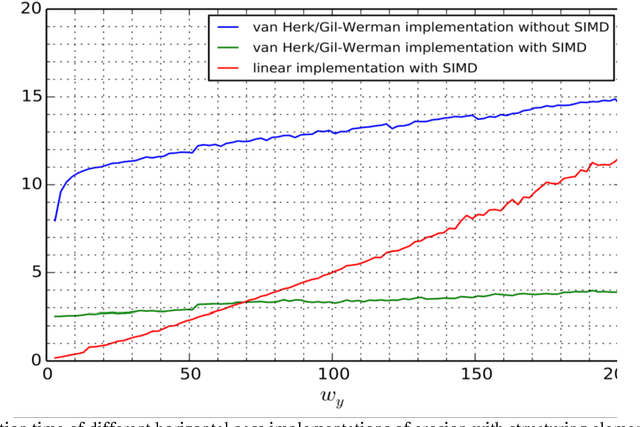
In this paper we consider speedup potential of morphological image filtering on ARM processors. Morphological operations are widely used in image analysis and recognition and their speedup in some cases can significantly reduce overall execution time of recognition. More specifically, we propose fast implementation of erosion and dilation using ARM SIMD extension NEON. These operations with the rectangular structuring element are separable. They were implemented using the advantages of separability as sequential horizontal and vertical passes. Each pass was implemented using van Herk/Gil-Werman algorithm for large windows and low-constant linear complexity algorithm for small windows. Final implementation was improved with SIMD and used a combination of these methods. We also considered fast transpose implementation of 8x8 and 16x16 matrices using ARM NEON to get additional computational gain for morphological operations. Experiments showed 3 times efficiency increase for final implementation of erosion and dilation compared to van Herk/Gil-Werman algorithm without SIMD, 5.7 times speedup for 8x8 matrix transpose and 12 times speedup for 16x16 matrix transpose compared to transpose without SIMD.
* 6 pages, 4 figures
Computational optimization of convolutional neural networks using separated filters architecture
Feb 18, 2020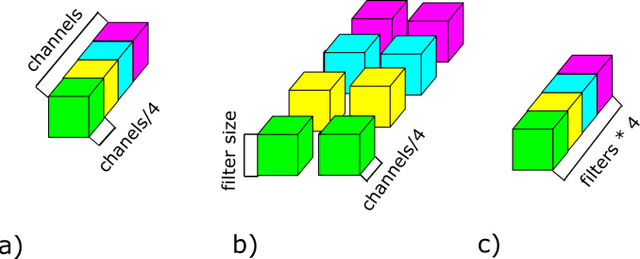


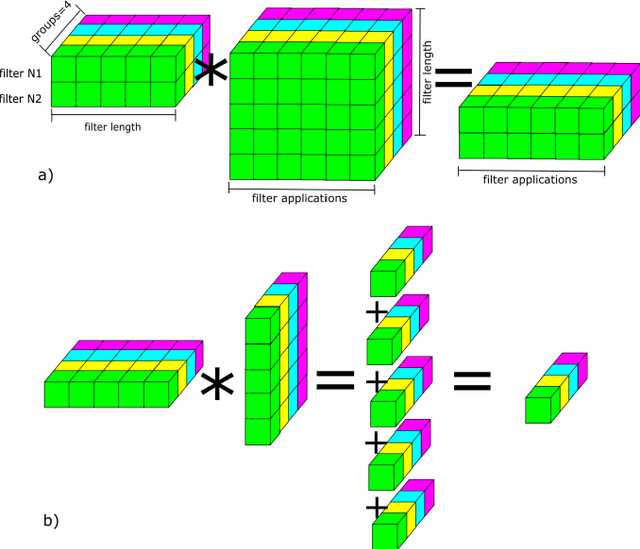
This paper considers a convolutional neural network transformation that reduces computation complexity and thus speedups neural network processing. Usage of convolutional neural networks (CNN) is the standard approach to image recognition despite the fact they can be too computationally demanding, for example for recognition on mobile platforms or in embedded systems. In this paper we propose CNN structure transformation which expresses 2D convolution filters as a linear combination of separable filters. It allows to obtain separated convolutional filters by standard training algorithms. We study the computation efficiency of this structure transformation and suggest fast implementation easily handled by CPU or GPU. We demonstrate that CNNs designed for letter and digit recognition of proposed structure show 15% speedup without accuracy loss in industrial image recognition system. In conclusion, we discuss the question of possible accuracy decrease and the application of proposed transformation to different recognition problems. convolutional neural networks, computational optimization, separable filters, complexity reduction.
* 4 pages, 3 figures
The Analysis of Projective Transformation Algorithms for Image Recognition on Mobile Devices
Dec 03, 2019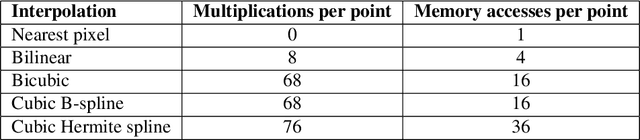
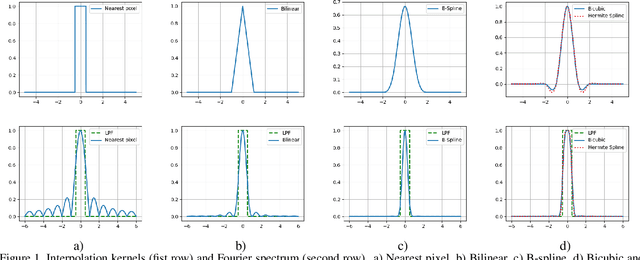

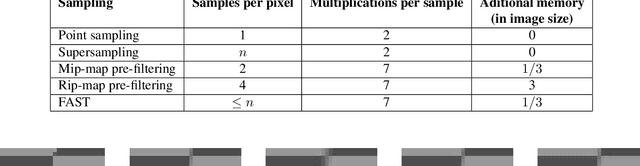
In this work we apply commonly known methods of non-adaptive interpolation (nearest pixel, bilinear, B-spline, bicubic, Hermite spline) and sampling (point sampling, supersampling, mip-map pre-filtering, rip-map pre-filtering and FAST) to the problem of projective image transformation. We compare their computational complexity, describe their artifacts and than experimentally measure their quality and working time on mobile processor with ARM architecture. Those methods were widely developed in the 90s and early 2000s, but were not in an area of active research in resent years due to a lower need in computationally efficient algorithms. However, real-time mobile recognition systems, which collect more and more attention, do not only require fast projective transform methods, but also demand high quality images without artifacts. As a result, in this work we choose methods appropriate for those systems, which allow to avoid artifacts, while preserving low computational complexity. Based on the experimental results for our setting they are bilinear interpolation combined with either mip-map pre-filtering or FAST sampling, but could be modified for specific use cases.
Bipolar Morphological Neural Networks: Convolution Without Multiplication
Nov 05, 2019



In the paper we introduce a novel bipolar morphological neuron and bipolar morphological layer models. The models use only such operations as addition, subtraction and maximum inside the neuron and exponent and logarithm as activation functions for the layer. The proposed models unlike previously introduced morphological neural networks approximate the classical computations and show better recognition results. We also propose layer-by-layer approach to train the bipolar morphological networks, which can be further developed to an incremental approach for separate neurons to get higher accuracy. Both these approaches do not require special training algorithms and can use a variety of gradient descent methods. To demonstrate efficiency of the proposed model we consider classical convolutional neural networks and convert the pre-trained convolutional layers to the bipolar morphological layers. Seeing that the experiments on recognition of MNIST and MRZ symbols show only moderate decrease of accuracy after conversion and training, bipolar neuron model can provide faster inference and be very useful in mobile and embedded systems.