 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast matrix multiplication for binary and ternary CNNs on ARM CPU
May 18, 2022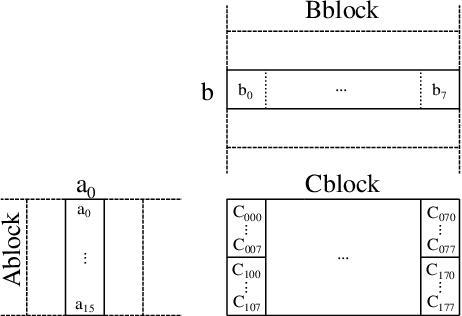
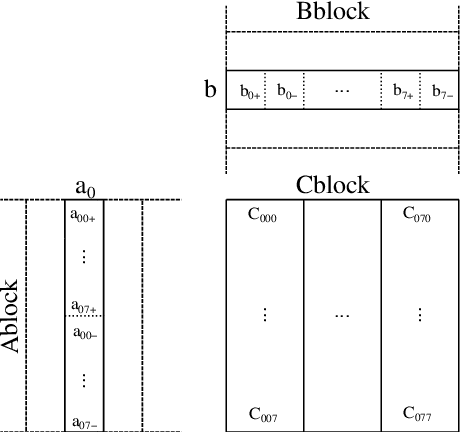
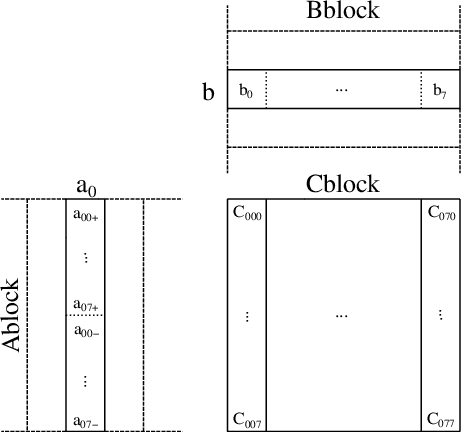

Low-bit quantized neural networks are of great interest in practical applications because they significantly reduce the consumption of both memory and computational resources. Binary neural networks are memory and computationally efficient as they require only one bit per weight and activation and can be computed using Boolean logic and bit count operations. QNNs with ternary weights and activations and binary weights and ternary activations aim to improve recognition quality compared to BNNs while preserving low bit-width. However, their efficient implementation is usually considered on ASICs and FPGAs, limiting their applicability in real-life tasks. At the same time, one of the areas where efficient recognition is most in demand is recognition on mobile devices using their CPUs. However, there are no known fast implementations of TBNs and TNN, only the daBNN library for BNNs inference. In this paper, we propose novel fast algorithms of ternary, ternary-binary, and binary matrix multiplication for mobile devices with ARM architecture. In our algorithms, ternary weights are represented using 2-bit encoding and binary - using one bit. It allows us to replace matrix multiplication with Boolean logic operations that can be computed on 128-bits simultaneously, using ARM NEON SIMD extension. The matrix multiplication results are accumulated in 16-bit integer registers. We also use special reordering of values in left and right matrices. All that allows us to efficiently compute a matrix product while minimizing the number of loads and stores compared to the algorithm from daBNN. Our algorithms can be used to implement inference of convolutional and fully connected layers of TNNs, TBNs, and BNNs. We evaluate them experimentally on ARM Cortex-A73 CPU and compare their inference speed to efficient implementations of full-precision, 8-bit, and 4-bit quantized matrix multiplications.
MIDV-2020: A Comprehensive Benchmark Dataset for Identity Document Analysis
Jul 01, 2021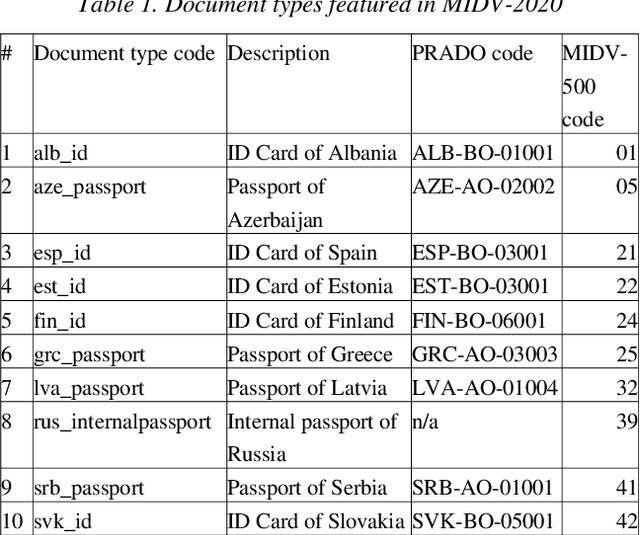

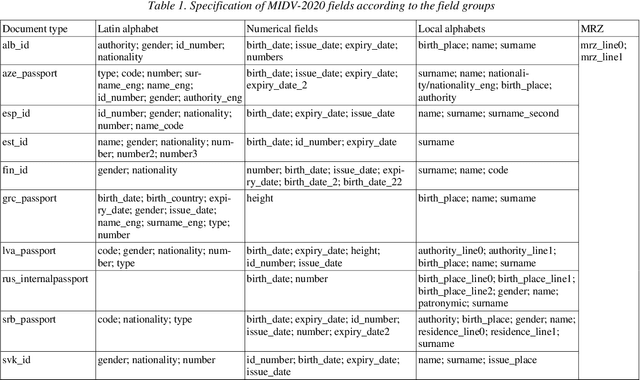

Identity documents recognition is an important sub-field of document analysis, which deals with tasks of robust document detection, type identification, text fields recognition, as well as identity fraud prevention and document authenticity validation given photos, scans, or video frames of an identity document capture. Significant amount of research has been published on this topic in recent years, however a chief difficulty for such research is scarcity of datasets, due to the subject matter being protected by security requirements. A few datasets of identity documents which are available lack diversity of document types, capturing conditions, or variability of document field values. In addition, the published datasets were typically designed only for a subset of document recognition problems, not for a complex identity document analysis. In this paper, we present a dataset MIDV-2020 which consists of 1000 video clips, 2000 scanned images, and 1000 photos of 1000 unique mock identity documents, each with unique text field values and unique artificially generated faces, with rich annotation. For the presented benchmark dataset baselines are provided for such tasks as document location and identification, text fields recognition, and face detection. With 72409 annotated images in total, to the date of publication the proposed dataset is the largest publicly available identity documents dataset with variable artificially generated data, and we believe that it will prove invaluable for advancement of the field of document analysis and recognition. The dataset is available for download at ftp://smartengines.com/midv-2020 and http://l3i-share.univ-lr.fr .
ResNet-like Architecture with Low Hardware Requirements
Sep 15, 2020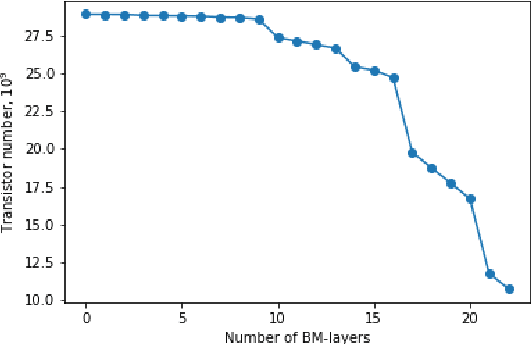
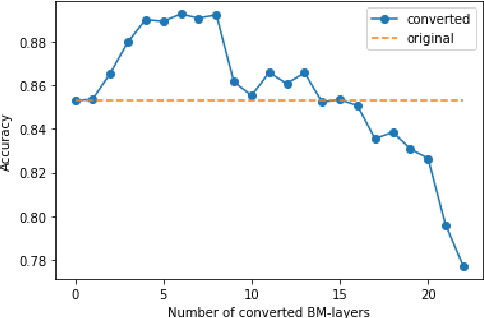
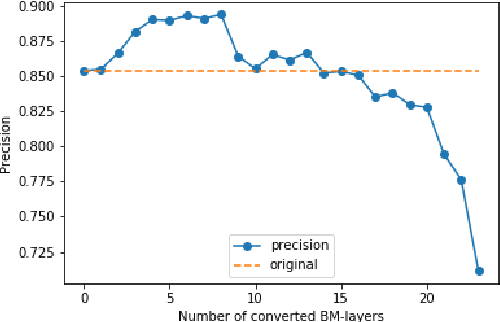
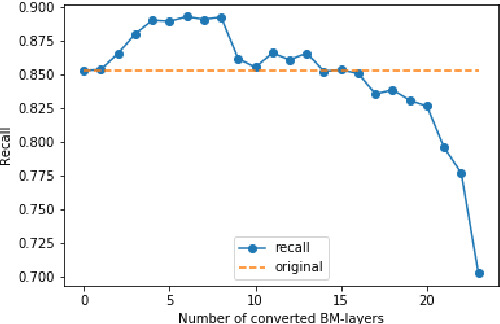
One of the most computationally intensive parts in modern recognition systems is an inference of deep neural networks that are used for image classification, segmentation, enhancement, and recognition. The growing popularity of edge computing makes us look for ways to reduce its time for mobile and embedded devices. One way to decrease the neural network inference time is to modify a neuron model to make it moreefficient for computations on a specific device. The example ofsuch a model is a bipolar morphological neuron model. The bipolar morphological neuron is based on the idea of replacing multiplication with addition and maximum operations. This model has been demonstrated for simple image classification with LeNet-like architectures [1]. In the paper, we introduce a bipolar morphological ResNet (BM-ResNet) model obtained from a much more complex ResNet architecture by converting its layers to bipolar morphological ones. We apply BM-ResNet to image classification on MNIST and CIFAR-10 datasets with only a moderate accuracy decrease from 99.3% to 99.1% and from 85.3% to 85.1%. We also estimate the computational complexity of the resulting model. We show that for the majority of ResNet layers, the considered model requires 2.1-2.9 times fewer logic gates for implementation and 15-30% lower latency.
Fast Implementation of 4-bit Convolutional Neural Networks for Mobile Devices
Sep 14, 2020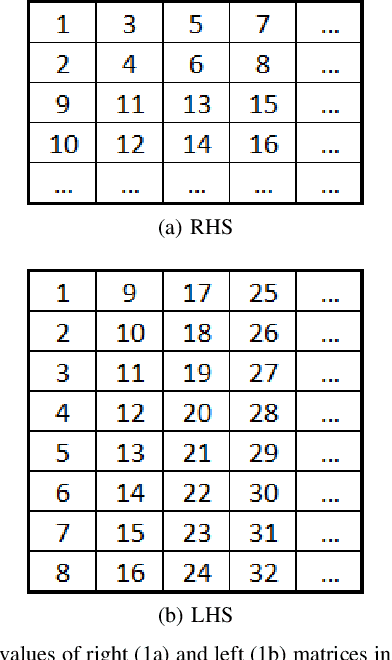
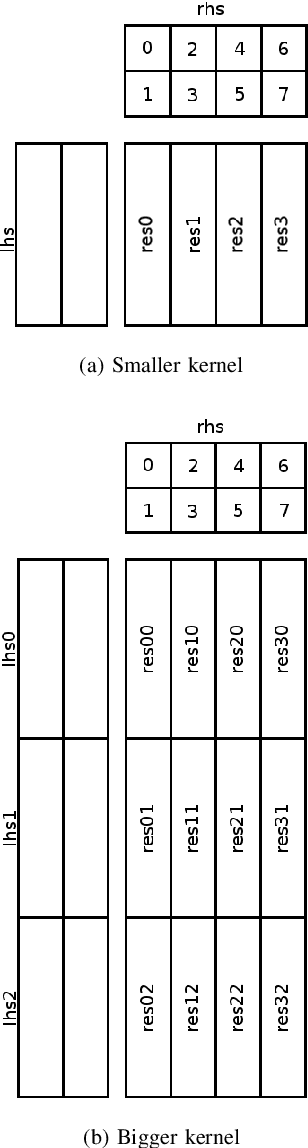

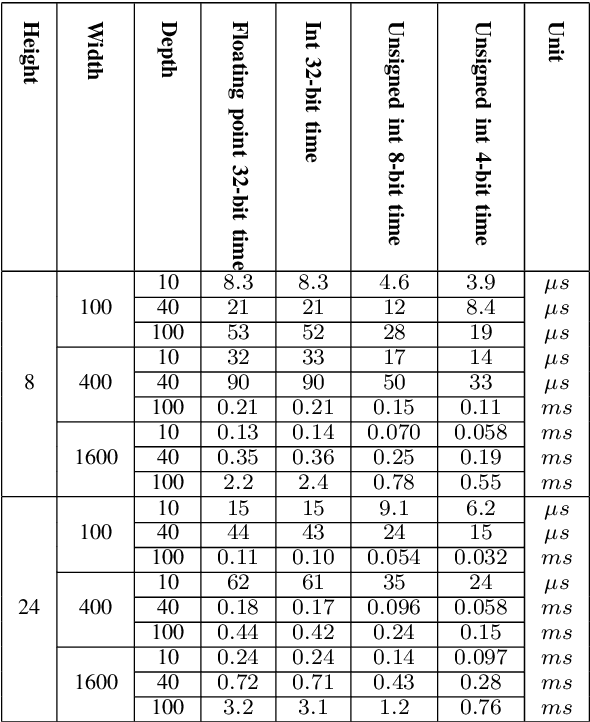
Quantized low-precision neural networks are very popular because they require less computational resources for inference and can provide high performance, which is vital for real-time and embedded recognition systems. However, their advantages are apparent for FPGA and ASIC devices, while general-purpose processor architectures are not always able to perform low-bit integer computations efficiently. The most frequently used low-precision neural network model for mobile central processors is an 8-bit quantized network. However, in a number of cases, it is possible to use fewer bits for weights and activations, and the only problem is the difficulty of efficient implementation. We introduce an efficient implementation of 4-bit matrix multiplication for quantized neural networks and perform time measurements on a mobile ARM processor. It shows 2.9 times speedup compared to standard floating-point multiplication and is 1.5 times faster than 8-bit quantized one. We also demonstrate a 4-bit quantized neural network for OCR recognition on the MIDV-500 dataset. 4-bit quantization gives 95.0% accuracy and 48% overall inference speedup, while an 8-bit quantized network gives 95.4% accuracy and 39% speedup. The results show that 4-bit quantization perfectly suits mobile devices, yielding good enough accuracy and low inference time.
Approach for document detection by contours and contrasts
Aug 06, 2020
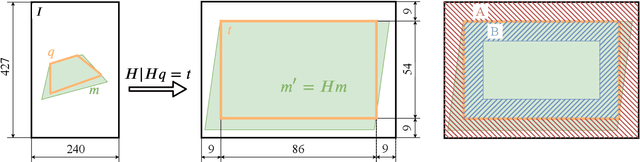


This paper considers the task of arbitrary document detection performed on a mobile device. The classical contour-based approach often mishandles cases with occlusion, complex background, or blur. Region-based approach, which relies on the contrast between object and background, does not have limitations, however its known implementations are highly resource-consuming. We propose a modification of a countor-based method, in which the competing hypotheses of the contour location are ranked according to the contrast between the areas inside and outside the border. In the performed experiments such modification leads to the 40% decrease of alternatives ordering errors and 10% decrease of the overall number of detection errors. We updated state-of-the-art performance on the open MIDV-500 dataset and demonstrated competitive results with the state-of-the-art on the SmartDoc dataset.
Fast Approximate Modelling of the Next Combination Result for Stopping the Text Recognition in a Video
Aug 06, 2020
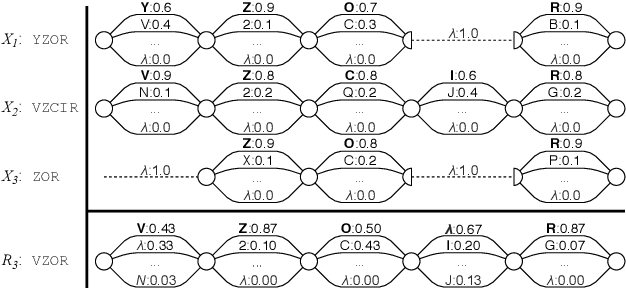
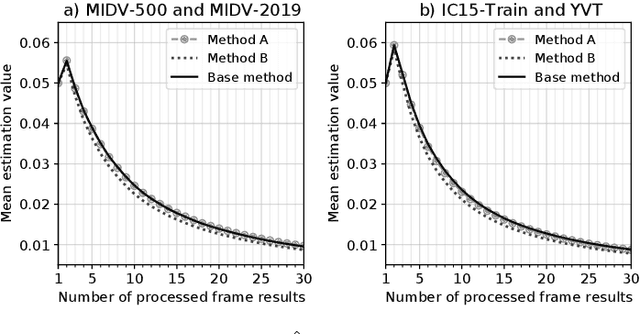
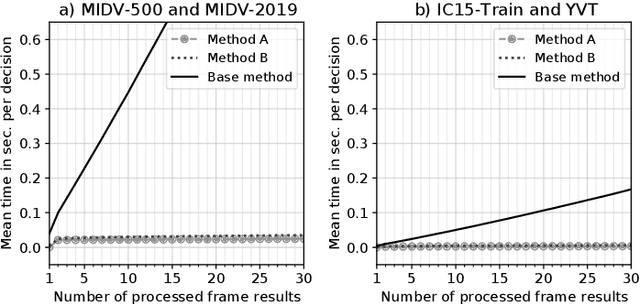
In this paper, we consider a task of stopping the video stream recognition process of a text field, in which each frame is recognized independently and the individual results are combined together. The video stream recognition stopping problem is an under-researched topic with regards to computer vision, but its relevance for building high-performance video recognition systems is clear. Firstly, we describe an existing method of optimally stopping such a process based on a modelling of the next combined result. Then, we describe approximations and assumptions which allowed us to build an optimized computation scheme and thus obtain a method with reduced computational complexity. The methods were evaluated for the tasks of document text field recognition and arbitrary text recognition in a video. The experimental comparison shows that the introduced approximations do not diminish the quality of the stopping method in terms of the achieved combined result precision, while dramatically reducing the time required to make the stopping decision. The results were consistent for both text recognition tasks.
Comparison of scanned administrative document images
Jan 29, 2020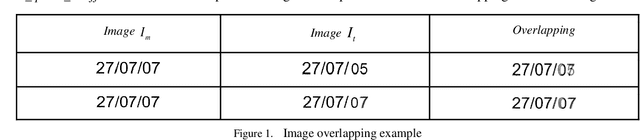
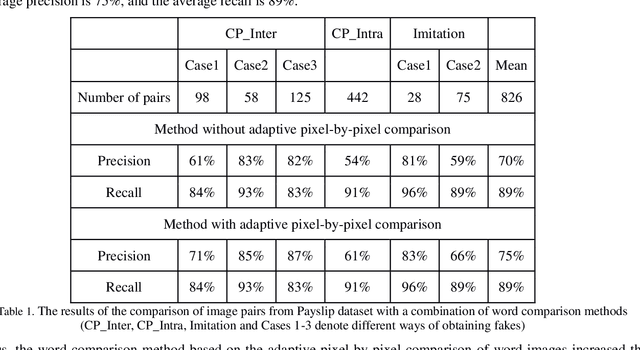
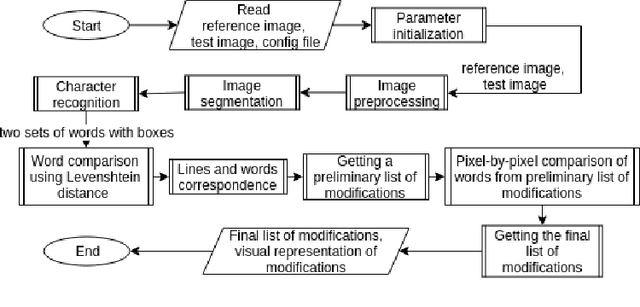
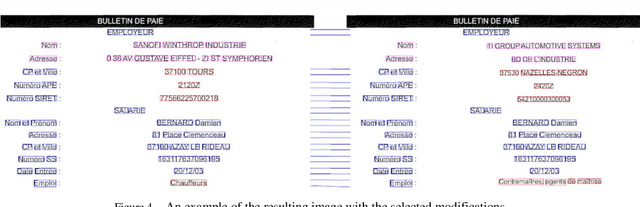
In this work the methods of comparison of digitized copies of administrative documents were considered. This problem arises, for example, when comparing two copies of documents signed by two parties in order to find possible modifications made by one party, in the banking sector at the conclusion of contracts in paper form. The proposed method of document image comparison is based on a combination of several ways of image comparison of words that are descriptors of text feature points. Testing was conducted on public Payslip Dataset (French). The results showed the high quality and the reliability of finding differences in two images that are versions of the same document.
Training the Convolutional Neural Network with Statistical Dependence of the Response on the Input Data Distortion
Dec 02, 2019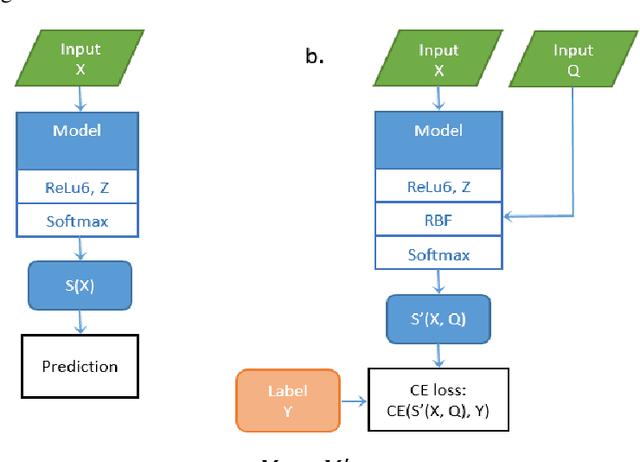



The paper proposes an approach to training a convolutional neural network using information on the level of distortion of input data. The learning process is modified with an additional layer, which is subsequently deleted, so the architecture of the original network does not change. As an example, the LeNet5 architecture network with training data based on the MNIST symbols and a distortion model as Gaussian blur with a variable level of distortion is considered. This approach does not have quality loss of the network and has a significant error-free zone in responses on the test data which is absent in the traditional approach to training. The responses are statistically dependent on the level of input image's distortions and there is a presence of a strong relationship between them.
Bipolar Morphological Neural Networks: Convolution Without Multiplication
Nov 05, 2019



In the paper we introduce a novel bipolar morphological neuron and bipolar morphological layer models. The models use only such operations as addition, subtraction and maximum inside the neuron and exponent and logarithm as activation functions for the layer. The proposed models unlike previously introduced morphological neural networks approximate the classical computations and show better recognition results. We also propose layer-by-layer approach to train the bipolar morphological networks, which can be further developed to an incremental approach for separate neurons to get higher accuracy. Both these approaches do not require special training algorithms and can use a variety of gradient descent methods. To demonstrate efficiency of the proposed model we consider classical convolutional neural networks and convert the pre-trained convolutional layers to the bipolar morphological layers. Seeing that the experiments on recognition of MNIST and MRZ symbols show only moderate decrease of accuracy after conversion and training, bipolar neuron model can provide faster inference and be very useful in mobile and embedded systems.
Next integrated result modelling for stopping the text field recognition process in a video using a result model with per-character alternatives
Oct 09, 2019

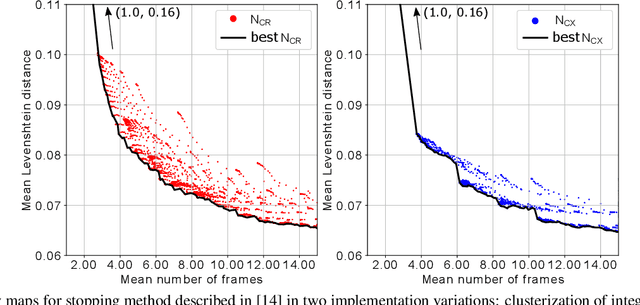
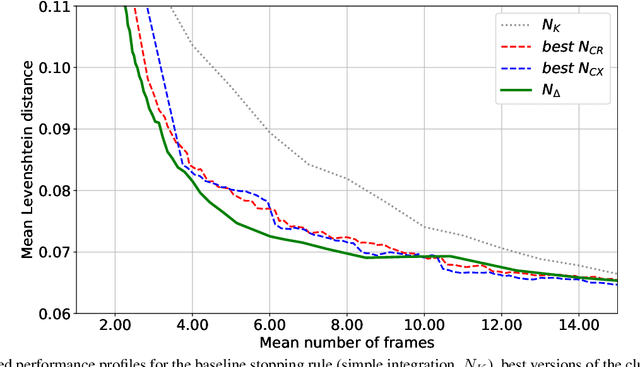
In the field of document analysis and recognition using mobile devices for capturing, and the field of object recognition in a video stream, an important problem is determining the time when the capturing process should be stopped. Efficient stopping influences not only the total time spent for performing recognition and data entry, but the expected accuracy of the result as well. This paper is directed on extending the stopping method based on next integrated recognition result modelling, in order for it to be used within a string result recognition model with per-character alternatives. The stopping method and notes on its extension are described, and experimental evaluation is performed on an open dataset MIDV-500. The method was compares with previously published methods based on input observations clustering. The obtained results indicate that the stopping method based on the next integrated result modelling allows to achieve higher accuracy, even when compared with the best achievable configuration of the competing methods.