 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Implementation of 4-bit Convolutional Neural Networks for Mobile Devices
Sep 14, 2020

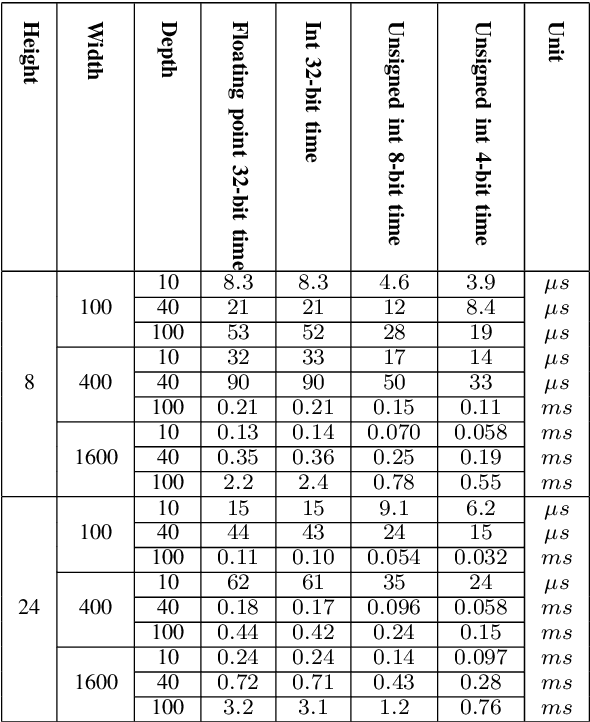
Quantized low-precision neural networks are very popular because they require less computational resources for inference and can provide high performance, which is vital for real-time and embedded recognition systems. However, their advantages are apparent for FPGA and ASIC devices, while general-purpose processor architectures are not always able to perform low-bit integer computations efficiently. The most frequently used low-precision neural network model for mobile central processors is an 8-bit quantized network. However, in a number of cases, it is possible to use fewer bits for weights and activations, and the only problem is the difficulty of efficient implementation. We introduce an efficient implementation of 4-bit matrix multiplication for quantized neural networks and perform time measurements on a mobile ARM processor. It shows 2.9 times speedup compared to standard floating-point multiplication and is 1.5 times faster than 8-bit quantized one. We also demonstrate a 4-bit quantized neural network for OCR recognition on the MIDV-500 dataset. 4-bit quantization gives 95.0% accuracy and 48% overall inference speedup, while an 8-bit quantized network gives 95.4% accuracy and 39% speedup. The results show that 4-bit quantization perfectly suits mobile devices, yielding good enough accuracy and low inference time.
Training the Convolutional Neural Network with Statistical Dependence of the Response on the Input Data Distortion
Dec 02, 2019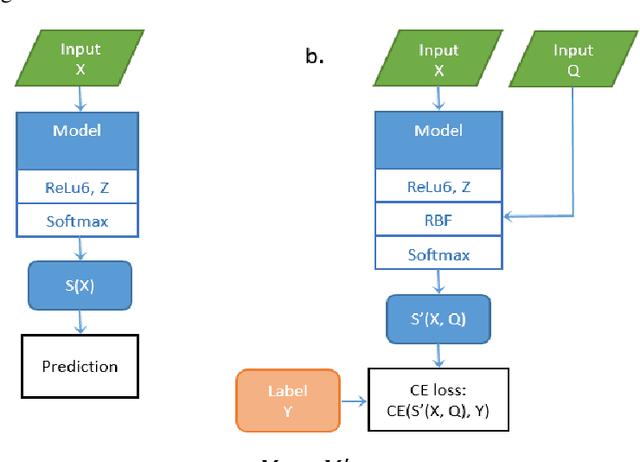



The paper proposes an approach to training a convolutional neural network using information on the level of distortion of input data. The learning process is modified with an additional layer, which is subsequently deleted, so the architecture of the original network does not change. As an example, the LeNet5 architecture network with training data based on the MNIST symbols and a distortion model as Gaussian blur with a variable level of distortion is considered. This approach does not have quality loss of the network and has a significant error-free zone in responses on the test data which is absent in the traditional approach to training. The responses are statistically dependent on the level of input image's distortions and there is a presence of a strong relationship between them.