 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproach for document detection by contours and contrasts
Aug 06, 2020
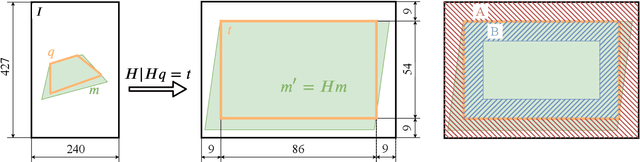


This paper considers the task of arbitrary document detection performed on a mobile device. The classical contour-based approach often mishandles cases with occlusion, complex background, or blur. Region-based approach, which relies on the contrast between object and background, does not have limitations, however its known implementations are highly resource-consuming. We propose a modification of a countor-based method, in which the competing hypotheses of the contour location are ranked according to the contrast between the areas inside and outside the border. In the performed experiments such modification leads to the 40% decrease of alternatives ordering errors and 10% decrease of the overall number of detection errors. We updated state-of-the-art performance on the open MIDV-500 dataset and demonstrated competitive results with the state-of-the-art on the SmartDoc dataset.
Recognition of Images of Korean Characters Using Embedded Networks
Dec 03, 2019



Despite the significant success in the field of text recognition, complex and unsolved problems still exist in this field. In recent years, the recognition accuracy of the English language has greatly increased, while the problem of recognition of hieroglyphs has received much less attention. Hieroglyph recognition or image recognition with Korean, Japanese or Chinese characters have differences from the traditional text recognition task. This article discusses the main differences between hieroglyph languages and the Latin alphabet in the context of image recognition. A light-weight method for recognizing images of the hieroglyphs is proposed and tested on a public dataset of Korean hieroglyph images. Despite the existing solutions, the proposed method is suitable for mobile devices. Its recognition accuracy is better than the accuracy of the open-source OCR framework. The presented method of training embedded net bases on the similarities in the recognition data.