 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhmerST: A Low-Resource Khmer Scene Text Detection and Recognition Benchmark
Oct 23, 2024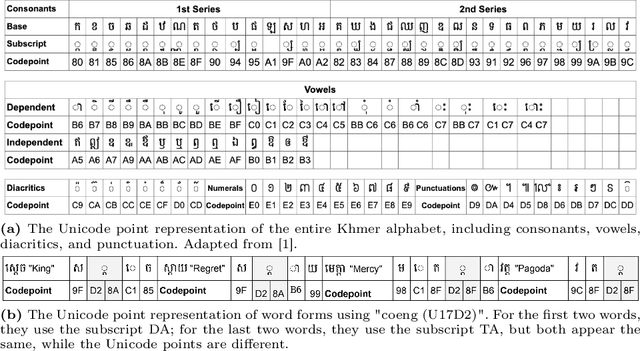
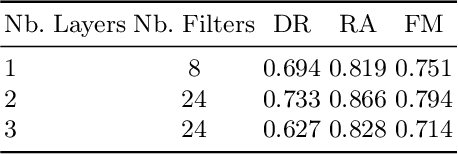

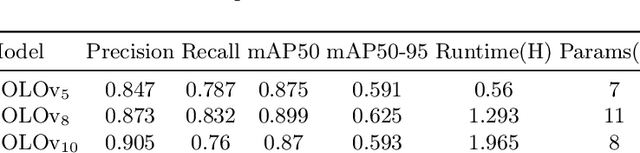
Developing effective scene text detection and recognition models hinges on extensive training data, which can be both laborious and costly to obtain, especially for low-resourced languages. Conventional methods tailored for Latin characters often falter with non-Latin scripts due to challenges like character stacking, diacritics, and variable character widths without clear word boundaries. In this paper, we introduce the first Khmer scene-text dataset, featuring 1,544 expert-annotated images, including 997 indoor and 547 outdoor scenes. This diverse dataset includes flat text, raised text, poorly illuminated text, distant and partially obscured text. Annotations provide line-level text and polygonal bounding box coordinates for each scene. The benchmark includes baseline models for scene-text detection and recognition tasks, providing a robust starting point for future research endeavors. The KhmerST dataset is publicly accessible at https://gitlab.com/vannkinhnom123/khmerst.
MIDV-2020: A Comprehensive Benchmark Dataset for Identity Document Analysis
Jul 01, 2021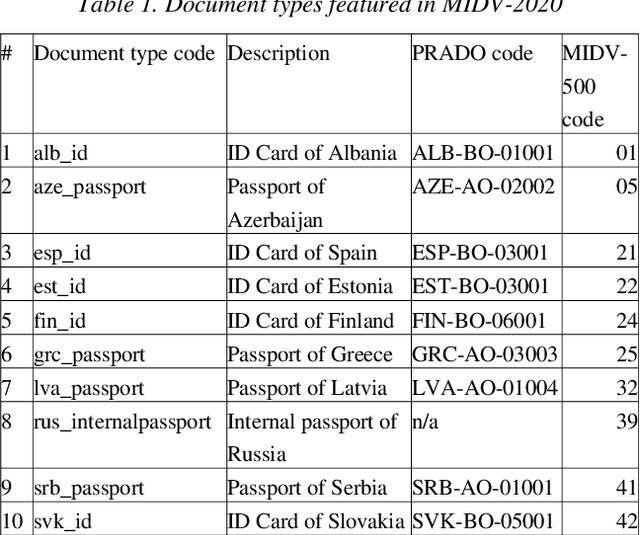

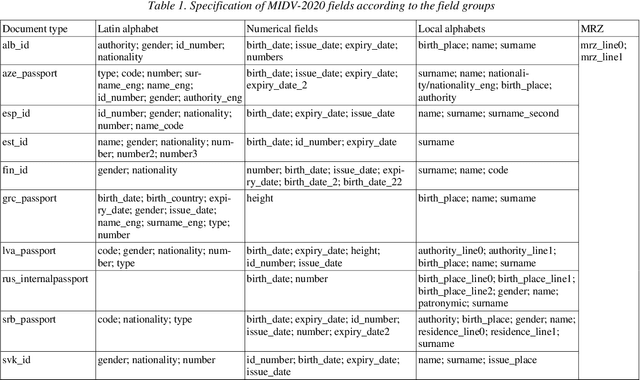

Identity documents recognition is an important sub-field of document analysis, which deals with tasks of robust document detection, type identification, text fields recognition, as well as identity fraud prevention and document authenticity validation given photos, scans, or video frames of an identity document capture. Significant amount of research has been published on this topic in recent years, however a chief difficulty for such research is scarcity of datasets, due to the subject matter being protected by security requirements. A few datasets of identity documents which are available lack diversity of document types, capturing conditions, or variability of document field values. In addition, the published datasets were typically designed only for a subset of document recognition problems, not for a complex identity document analysis. In this paper, we present a dataset MIDV-2020 which consists of 1000 video clips, 2000 scanned images, and 1000 photos of 1000 unique mock identity documents, each with unique text field values and unique artificially generated faces, with rich annotation. For the presented benchmark dataset baselines are provided for such tasks as document location and identification, text fields recognition, and face detection. With 72409 annotated images in total, to the date of publication the proposed dataset is the largest publicly available identity documents dataset with variable artificially generated data, and we believe that it will prove invaluable for advancement of the field of document analysis and recognition. The dataset is available for download at ftp://smartengines.com/midv-2020 and http://l3i-share.univ-lr.fr .
A Survey On Anti-Spoofing Methods For Face Recognition with RGB Cameras of Generic Consumer Devices
Oct 08, 2020
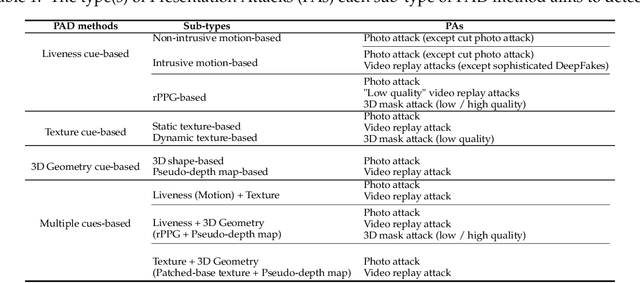

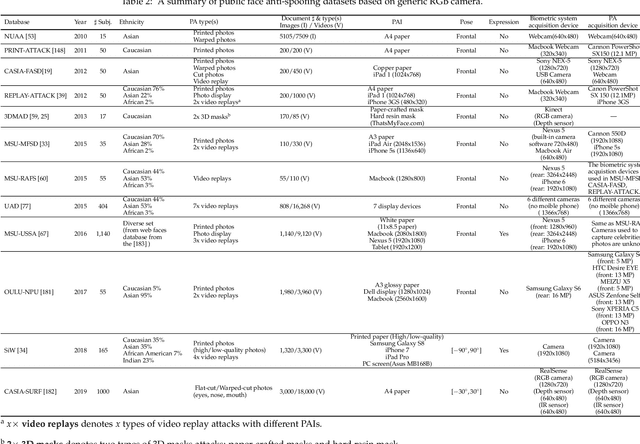
The widespread deployment of face recognition-based biometric systems has made face Presentation Attack Detection (face anti-spoofing) an increasingly critical issue. This survey thoroughly investigates the face Presentation Attack Detection (PAD) methods, that only require RGB cameras of generic consumer devices, over the past two decades. We present an attack scenario-oriented typology of the existing face PAD methods and we provide a review of over 50 of the most recent face PAD methods and their related issues. We adopt a comprehensive presentation of the methods that have most influenced face PAD following the proposed typology, and in chronological order. By doing so, we depict the main challenges, evolutions and current trends in the field of face PAD, and provide insights on its future research. From an experimental point of view, this survey paper provides a summarized overview of the available public databases and extensive comparative experimental results of different PAD methods.
Cross-modal Multi-task Learning for Graphic Recognition of Caricature Face
Mar 10, 2020
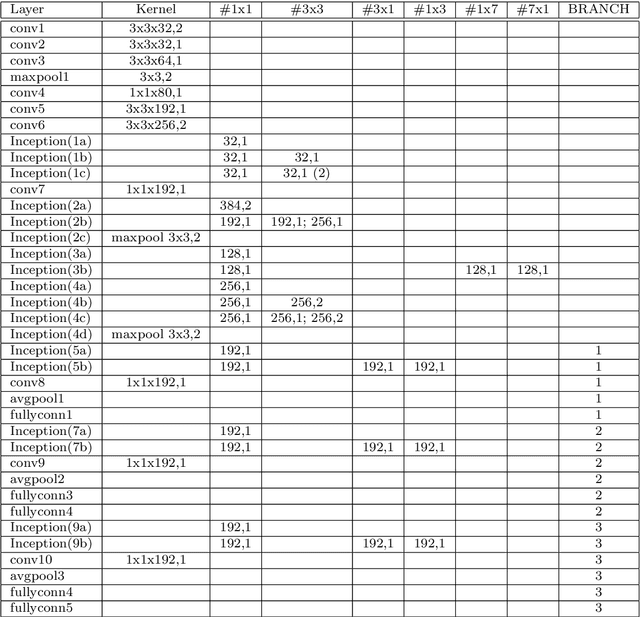
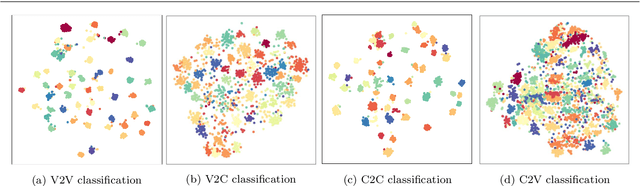
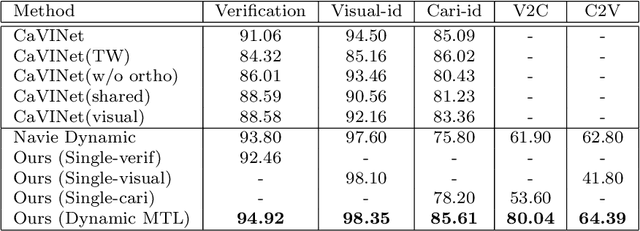
Face recognition of realistic visual images has been well studied and made a significant progress in the recent decade. Unlike the realistic visual images, the face recognition of the caricatures is far from the performance of the visual images. This is largely due to the extreme non-rigid distortions of the caricatures introduced by exaggerating the facial features to strengthen the characters. The heterogeneous modalities of the caricatures and the visual images result the caricature-visual face recognition is a cross-modal problem. In this paper, we propose a method to conduct caricature-visual face recognition via multi-task learning. Rather than the conventional multi-task learning with fixed weights of tasks, this work proposes an approach to learn the weights of tasks according to the importance of tasks. The proposed multi-task learning with dynamic tasks weights enables to appropriately train the hard task and easy task instead of being stuck in the over-training easy task as conventional methods. The experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning for cross-modal caricature-visual face recognition. The performances on the datasets CaVI and WebCaricature show the superiority over the state-of-art methods.
Face Detection in Camera Captured Images of Identity Documents under Challenging Conditions
Nov 08, 2019
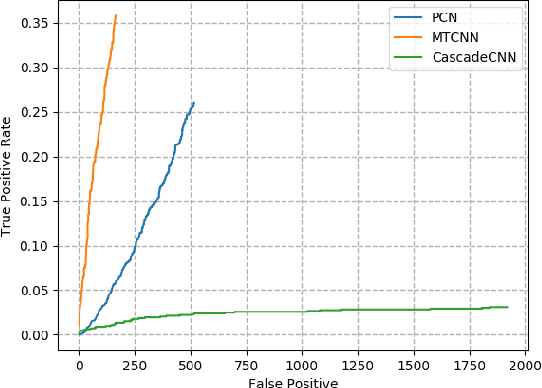


Benefiting from the advance of deep convolutional neural network approaches (CNNs), many face detection algorithms have achieved state-of-the-art performance in terms of accuracy and very high speed in unconstrained applications. However, due to the lack of public datasets and due to the variation of the orientation of face images, the complex background and lighting, defocus and the varying illumination of camera captured images, face detection on identity documents under unconstrained environments has not been sufficiently studied. To address this problem more efficiently, we survey three state-of-the-art face detection methods based on general images, i.e. Cascade-CNN, MTCNN and PCN, for face detection in camera captured images of identity documents, given different image quality assessments. For that, The MIDV-500 dataset, which is the largest and most challenging dataset for identity documents, is used to evaluate the three methods. The evaluation results show the performance and the limitations of the current methods for face detection on identity documents under the wild complex environments. These results show that the face detection task in camera captured images of identity documents is challenging, providing a space to improve in the future works.
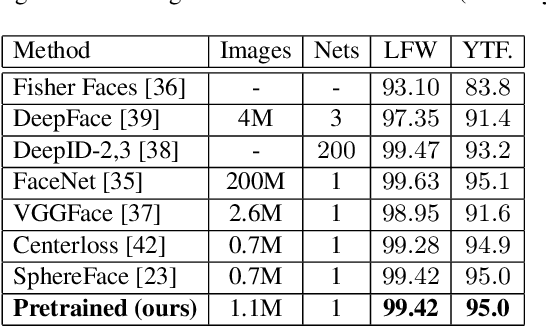
Dynamic Deep Multi-task Learning for Caricature-Visual Face Recognition
Nov 08, 2019

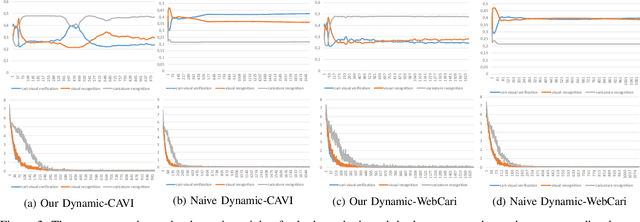
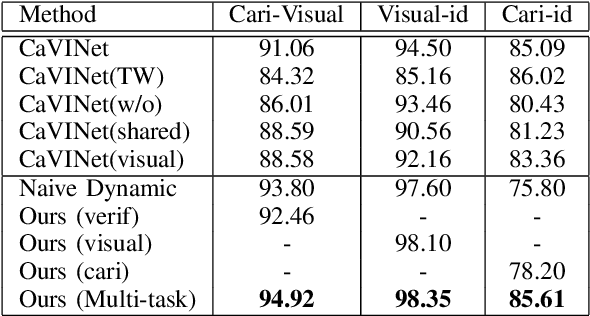
Rather than the visual images, the face recognition of the caricatures is far from the performance of the visual images. The challenge is the extreme non-rigid distortions of the caricatures introduced by exaggerating the facial features to strengthen the characters. In this paper, we propose dynamic multi-task learning based on deep CNNs for cross-modal caricature-visual face recognition. Instead of the conventional multi-task learning with fixed weights of the tasks, the proposed dynamic multi-task learning dynamically updates the weights of tasks according to the importance of the tasks, which enables the training of the networks focus on the hard task instead of being stuck in the overtraining of the easy task. The experimental results demonstrate the effectiveness of the dynamic multi-task learning for caricature-visual face recognition. The performance evaluated on the datasets CaVI and WebCaricature show the superiority over the state-of-art methods. The implementation code is available here.
Dynamic Multi-Task Learning for Face Recognition with Facial Expression
Nov 08, 2019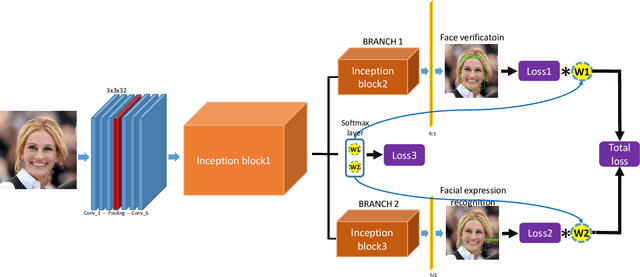

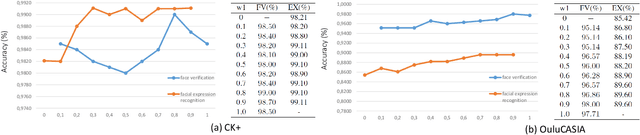
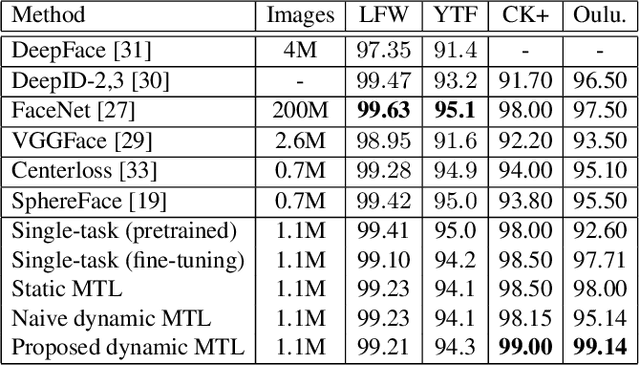
Benefiting from the joint learning of the multiple tasks in the deep multi-task networks, many applications have shown the promising performance comparing to single-task learning. However, the performance of multi-task learning framework is highly dependant on the relative weights of the tasks. How to assign the weight of each task is a critical issue in the multi-task learning. Instead of tuning the weights manually which is exhausted and time-consuming, in this paper we propose an approach which can dynamically adapt the weights of the tasks according to the difficulty for training the task. Specifically, the proposed method does not introduce the hyperparameters and the simple structure allows the other multi-task deep learning networks can easily realize or reproduce this method. We demonstrate our approach for face recognition with facial expression and facial expression recognition from a single input image based on a deep multi-task learning Conventional Neural Networks (CNNs). Both the theoretical analysis and the experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning method. This multi-task learning with dynamic weights also boosts of the performance on the different tasks comparing to the state-of-art methods with single-task learning.
FaceLiveNet+: A Holistic Networks For Face Authentication Based On Dynamic Multi-task Convolutional Neural Networks
Feb 28, 2019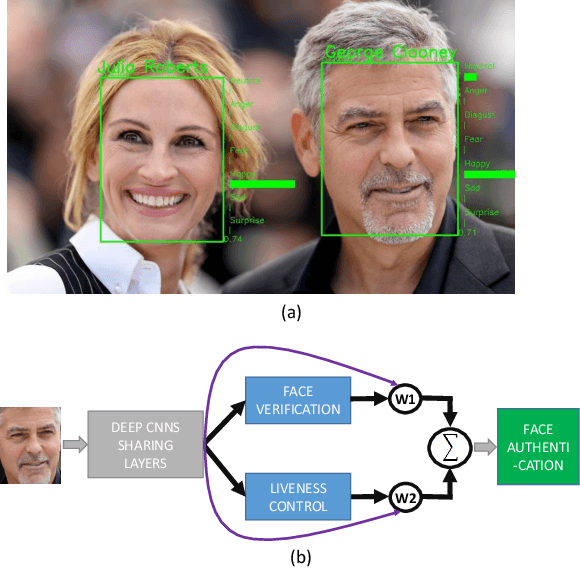

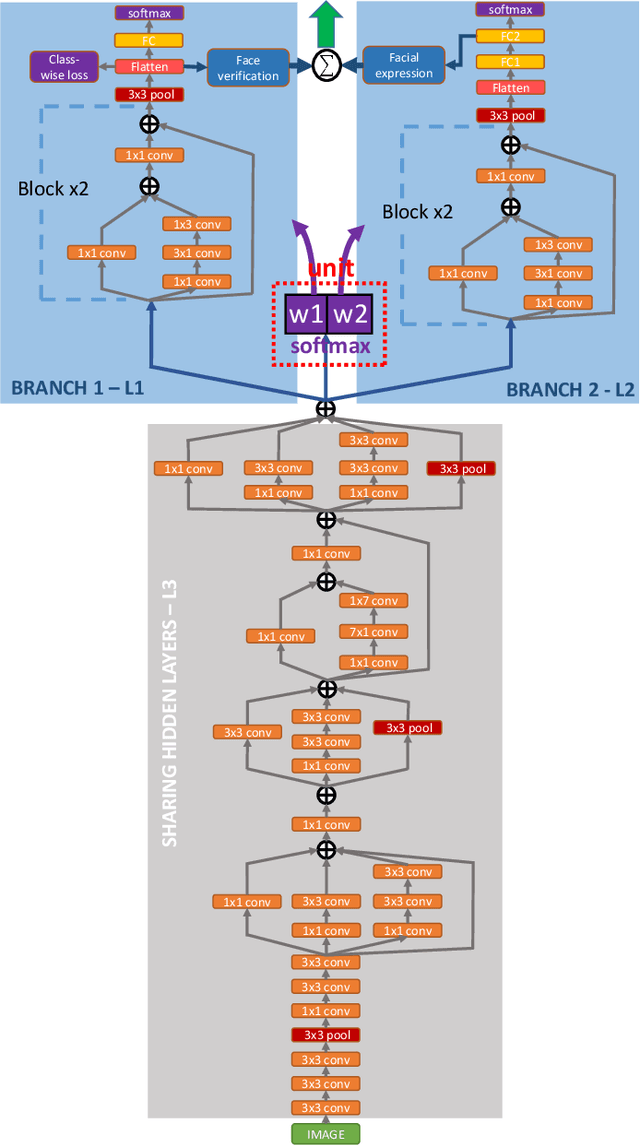
This paper proposes a holistic multi-task Convolutional Neural Networks (CNNs) with the dynamic weights of the tasks,namely FaceLiveNet+, for face authentication. FaceLiveNet+ can employ face verification and facial expression recognition as a solution of liveness control simultaneously. Comparing to the single-task learning, the proposed multi-task learning can better capture the feature representation for all of the tasks. The experimental results show the superiority of the multi-task learning to the single-task learning for both the face verification task and facial expression recognition task. Rather using a conventional multi-task learning with fixed weights for the tasks, this work proposes a so called dynamic-weight-unit to automatically learn the weights of the tasks. The experiments have shown the effectiveness of the dynamic weights for training the networks. Finally, the holistic evaluation for face authentication based on the proposed protocol has shown the feasibility to apply the FaceLiveNet+ for face authentication.
Employing fuzzy intervals and loop-based methodology for designing structural signature: an application to symbol recognition
Apr 30, 2010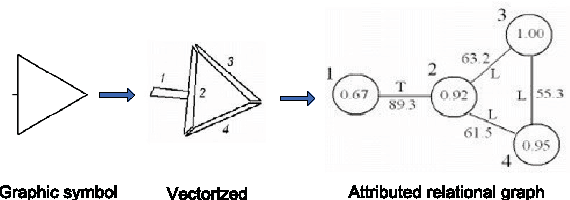
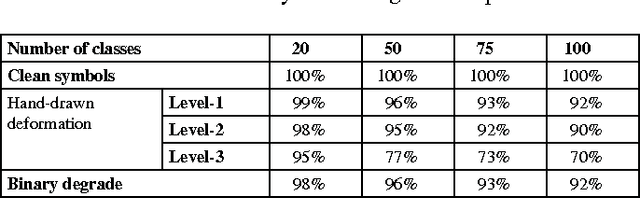
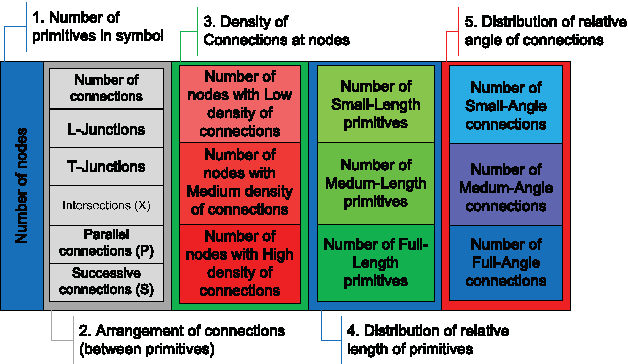
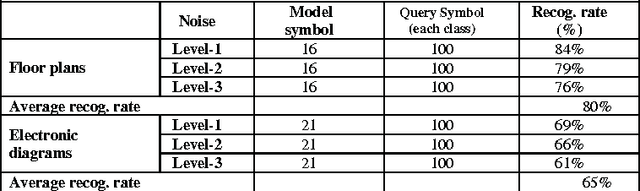
Motivation of our work is to present a new methodology for symbol recognition. We support structural methods for representing visual associations in graphic documents. The proposed method employs a structural approach for symbol representation and a statistical classifier for recognition. We vectorize a graphic symbol, encode its topological and geometrical information by an ARG and compute a signature from this structural graph. To address the sensitivity of structural representations to deformations and degradations, we use data adapted fuzzy intervals while computing structural signature. The joint probability distribution of signatures is encoded by a Bayesian network. This network in fact serves as a mechanism for pruning irrelevant features and choosing a subset of interesting features from structural signatures, for underlying symbol set. Finally we deploy the Bayesian network in supervised learning scenario for recognizing query symbols. We have evaluated the robustness of our method against noise, on synthetically deformed and degraded images of pre-segmented 2D architectural and electronic symbols from GREC databases and have obtained encouraging recognition rates. A second set of experimentation was carried out for evaluating the performance of our method against context noise i.e. symbols cropped from complete documents. The results support the use of our signature by a symbol spotting system.
Graphic Symbol Recognition using Graph Based Signature and Bayesian Network Classifier
Apr 30, 2010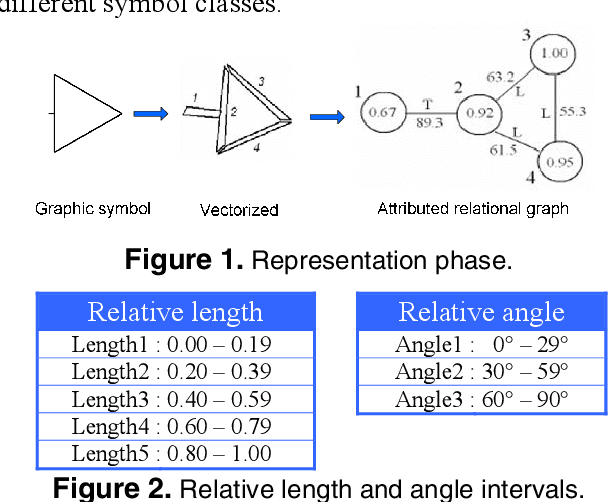
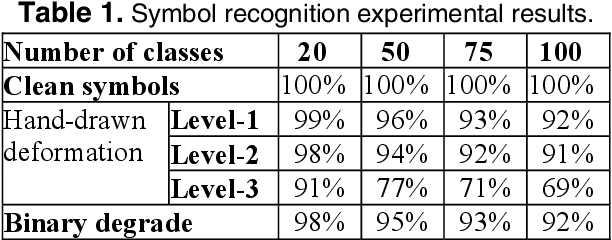
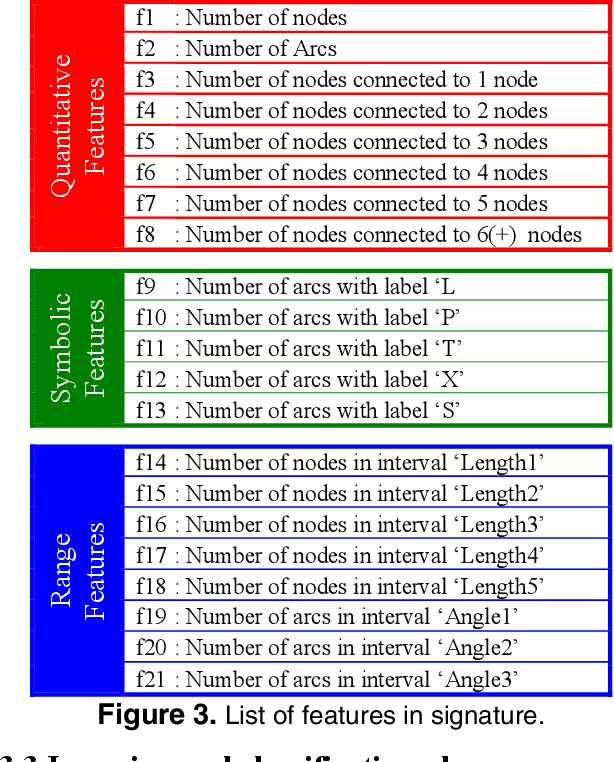
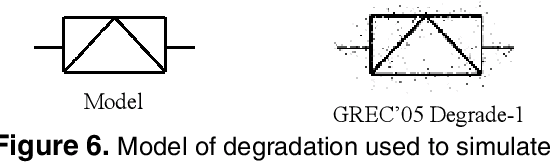
We present a new approach for recognition of complex graphic symbols in technical documents. Graphic symbol recognition is a well known challenge in the field of document image analysis and is at heart of most graphic recognition systems. Our method uses structural approach for symbol representation and statistical classifier for symbol recognition. In our system we represent symbols by their graph based signatures: a graphic symbol is vectorized and is converted to an attributed relational graph, which is used for computing a feature vector for the symbol. This signature corresponds to geometry and topology of the symbol. We learn a Bayesian network to encode joint probability distribution of symbol signatures and use it in a supervised learning scenario for graphic symbol recognition. We have evaluated our method on synthetically deformed and degraded images of pre-segmented 2D architectural and electronic symbols from GREC databases and have obtained encouraging recognition rates.