 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTransPAD: Video Transformer using convolution and self-attention for Face Presentation Attack Detection
Mar 14, 2022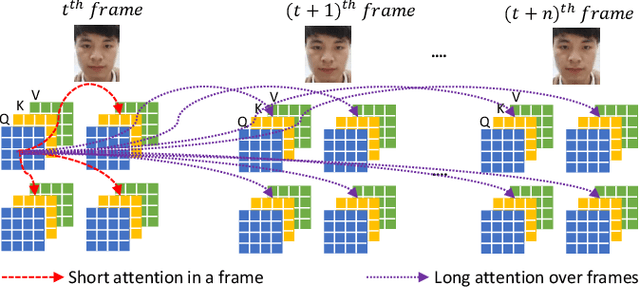
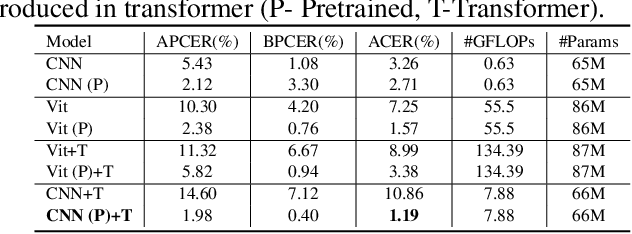
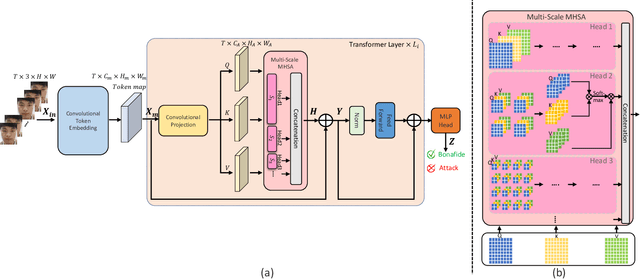
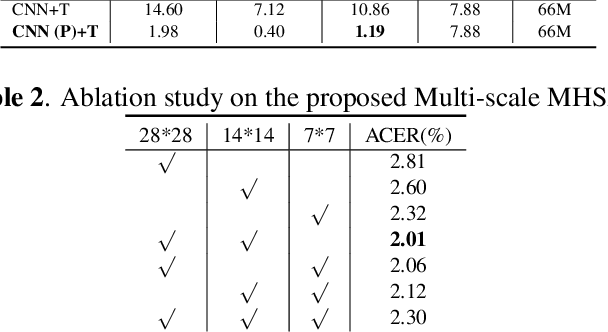
Face Presentation Attack Detection (PAD) is an important measure to prevent spoof attacks for face biometric systems. Many works based on Convolution Neural Networks (CNNs) for face PAD formulate the problem as an image-level binary classification task without considering the context. Alternatively, Vision Transformers (ViT) using self-attention to attend the context of an image become the mainstreams in face PAD. Inspired by ViT, we propose a Video-based Transformer for face PAD (ViTransPAD) with short/long-range spatio-temporal attention which can not only focus on local details with short attention within a frame but also capture long-range dependencies over frames. Instead of using coarse image patches with single-scale as in ViT, we propose the Multi-scale Multi-Head Self-Attention (MsMHSA) architecture to accommodate multi-scale patch partitions of Q, K, V feature maps to the heads of transformer in a coarse-to-fine manner, which enables to learn a fine-grained representation to perform pixel-level discrimination for face PAD. Due to lack inductive biases of convolutions in pure transformers, we also introduce convolutions to the proposed ViTransPAD to integrate the desirable properties of CNNs by using convolution patch embedding and convolution projection. The extensive experiments show the effectiveness of our proposed ViTransPAD with a preferable accuracy-computation balance, which can serve as a new backbone for face PAD.
Predicting Brain Degeneration with a Multimodal Siamese Neural Network
Nov 02, 2020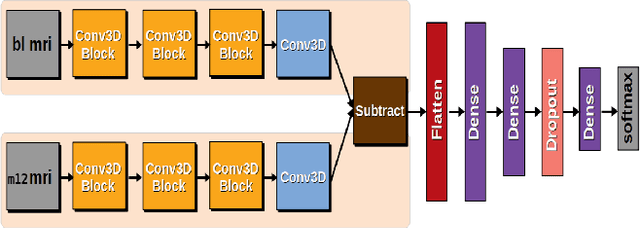
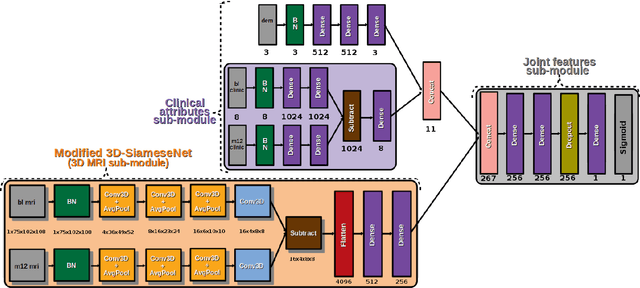
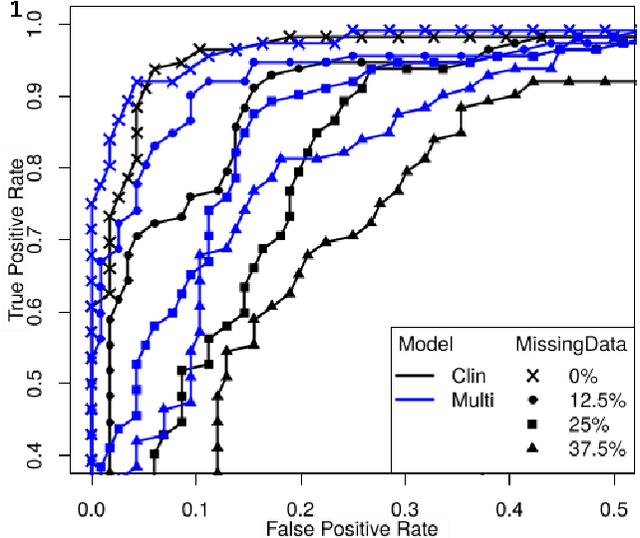
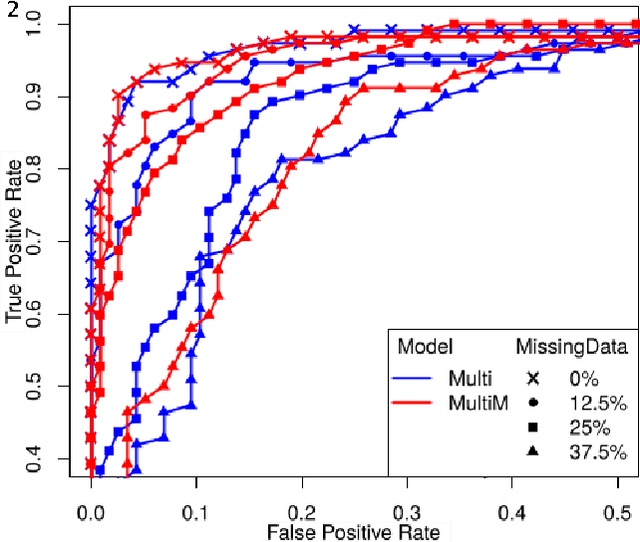
To study neurodegenerative diseases, longitudinal studies are carried on volunteer patients. During a time span of several months to several years, they go through regular medical visits to acquire data from different modalities, such as biological samples, cognitive tests, structural and functional imaging. These variables are heterogeneous but they all depend on the patient's health condition, meaning that there are possibly unknown relationships between all modalities. Some information may be specific to some modalities, others may be complementary, and others may be redundant. Some data may also be missing. In this work we present a neural network architecture for multimodal learning, able to use imaging and clinical data from two time points to predict the evolution of a neurodegenerative disease, and robust to missing values. Our multimodal network achieves 92.5\% accuracy and an AUC score of 0.978 over a test set of 57 subjects. We also show the superiority of the multimodal architecture, for up to 37.5\% of missing values in test set subjects' clinical measurements, compared to a model using only the clinical modality.
A Survey On Anti-Spoofing Methods For Face Recognition with RGB Cameras of Generic Consumer Devices
Oct 08, 2020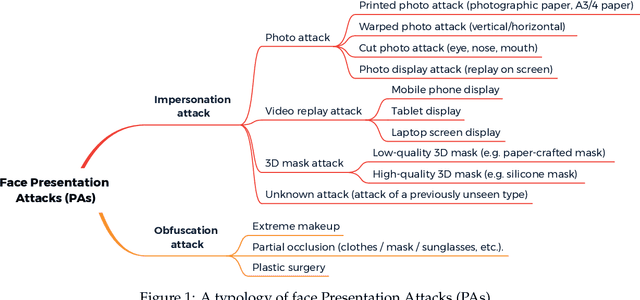
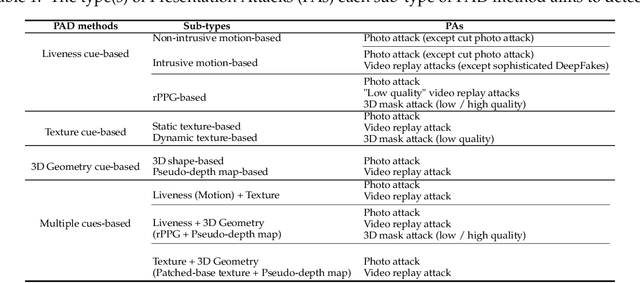

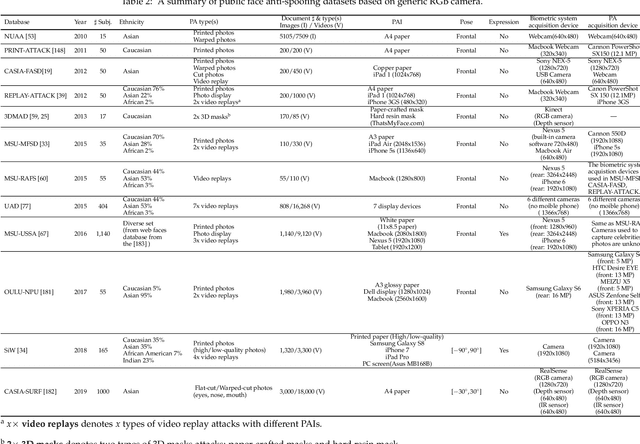
The widespread deployment of face recognition-based biometric systems has made face Presentation Attack Detection (face anti-spoofing) an increasingly critical issue. This survey thoroughly investigates the face Presentation Attack Detection (PAD) methods, that only require RGB cameras of generic consumer devices, over the past two decades. We present an attack scenario-oriented typology of the existing face PAD methods and we provide a review of over 50 of the most recent face PAD methods and their related issues. We adopt a comprehensive presentation of the methods that have most influenced face PAD following the proposed typology, and in chronological order. By doing so, we depict the main challenges, evolutions and current trends in the field of face PAD, and provide insights on its future research. From an experimental point of view, this survey paper provides a summarized overview of the available public databases and extensive comparative experimental results of different PAD methods.