 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDTrust: Deep Identity Document Quality Detection with Bandpass Filtering
Mar 01, 2024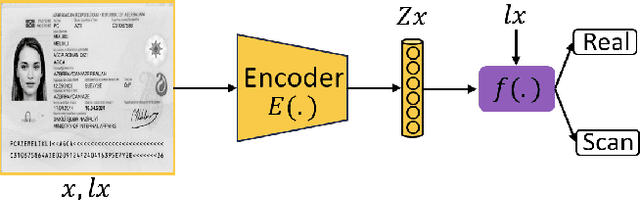
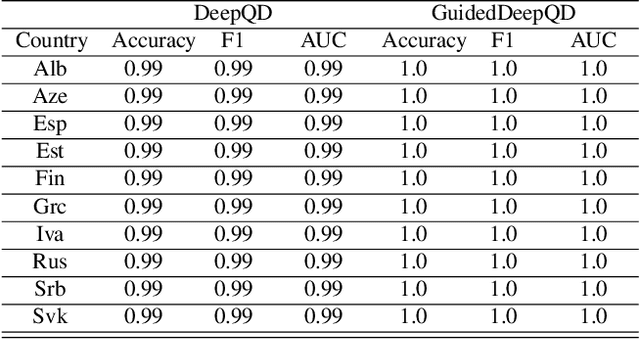
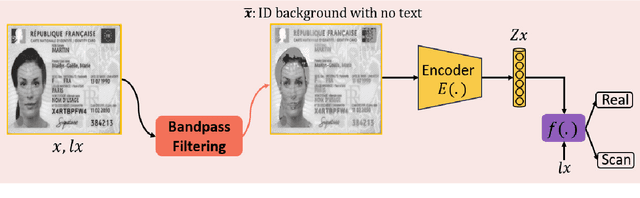
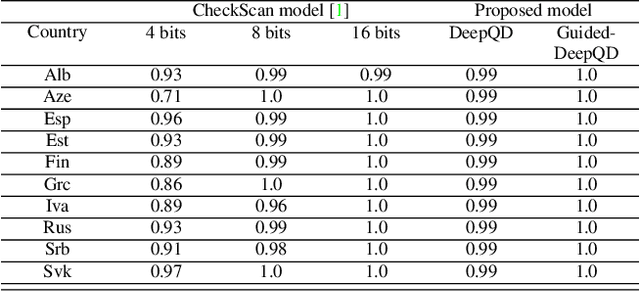
The increasing use of digital technologies and mobile-based registration procedures highlights the vital role of personal identity documents (IDs) in verifying users and safeguarding sensitive information. However, the rise in counterfeit ID production poses a significant challenge, necessitating the development of reliable and efficient automated verification methods. This paper introduces IDTrust, a deep-learning framework for assessing the quality of IDs. IDTrust is a system that enhances the quality of identification documents by using a deep learning-based approach. This method eliminates the need for relying on original document patterns for quality checks and pre-processing steps for alignment. As a result, it offers significant improvements in terms of dataset applicability. By utilizing a bandpass filtering-based method, the system aims to effectively detect and differentiate ID quality. Comprehensive experiments on the MIDV-2020 and L3i-ID datasets identify optimal parameters, significantly improving discrimination performance and effectively distinguishing between original and scanned ID documents.
Identity Documents Authentication based on Forgery Detection of Guilloche Pattern
Jun 22, 2022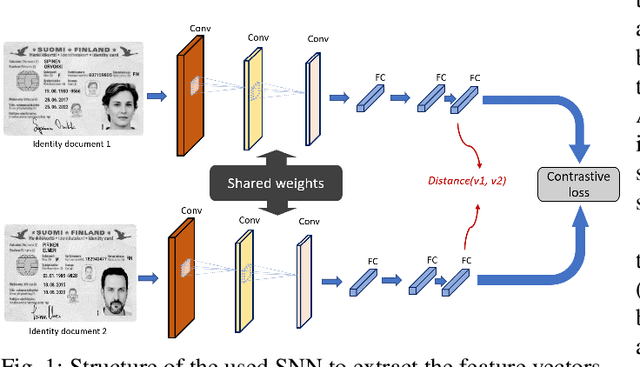

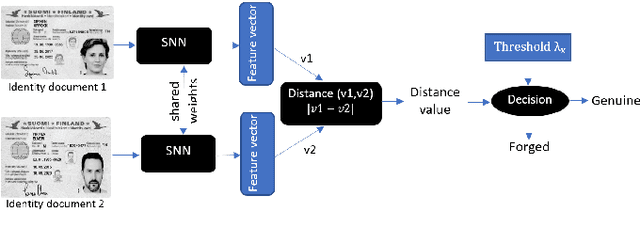

In cases such as digital enrolment via mobile and online services, identity document verification is critical in order to efficiently detect forgery and therefore build user trust in the digital world. In this paper, an authentication model for identity documents based on forgery detection of guilloche patterns is proposed. The proposed approach is made up of two steps: feature extraction and similarity measure between a pair of feature vectors of identity documents. The feature extraction step involves learning the similarity between a pair of identity documents via a convolutional neural network (CNN) architecture and ends by extracting highly discriminative features between them. While, the similarity measure step is applied to decide if a given identity document is authentic or forged. In this work, these two steps are combined together to achieve two objectives: (i) extracted features should have good anticollision (discriminative) capabilities to distinguish between a pair of identity documents belonging to different classes, (ii) checking out the conformity of the guilloche pattern of a given identity document and its similarity to the guilloche pattern of an authentic version of the same country. Experiments are conducted in order to analyze and identify the most proper parameters to achieve higher authentication performance. The experimental results are performed on the MIDV-2020 dataset. The results show the ability of the proposed approach to extract the relevant characteristics of the processed pair of identity documents in order to model the guilloche patterns, and thus distinguish them correctly. The implementation code and the forged dataset are provided here (https://drive.google.com/id-FDGP-1)
ViTransPAD: Video Transformer using convolution and self-attention for Face Presentation Attack Detection
Mar 14, 2022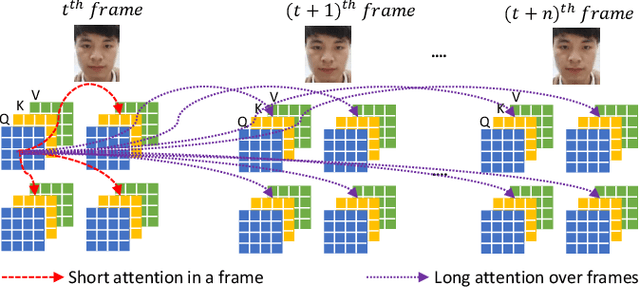
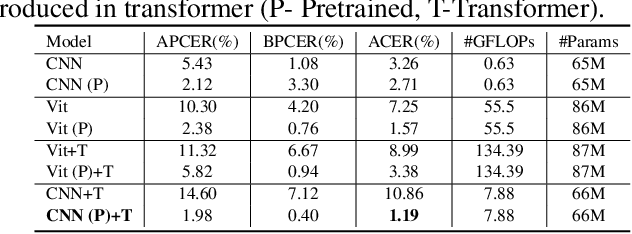
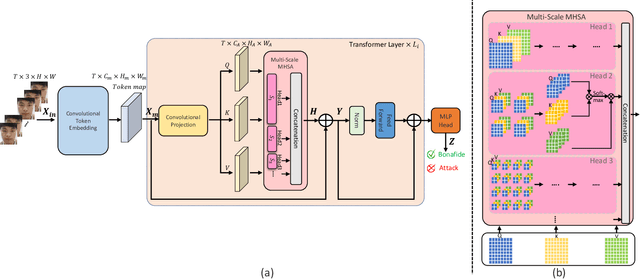
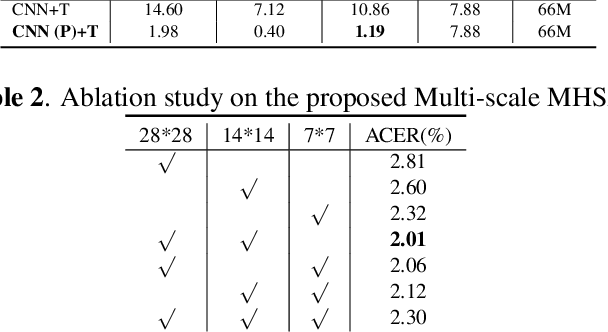
Face Presentation Attack Detection (PAD) is an important measure to prevent spoof attacks for face biometric systems. Many works based on Convolution Neural Networks (CNNs) for face PAD formulate the problem as an image-level binary classification task without considering the context. Alternatively, Vision Transformers (ViT) using self-attention to attend the context of an image become the mainstreams in face PAD. Inspired by ViT, we propose a Video-based Transformer for face PAD (ViTransPAD) with short/long-range spatio-temporal attention which can not only focus on local details with short attention within a frame but also capture long-range dependencies over frames. Instead of using coarse image patches with single-scale as in ViT, we propose the Multi-scale Multi-Head Self-Attention (MsMHSA) architecture to accommodate multi-scale patch partitions of Q, K, V feature maps to the heads of transformer in a coarse-to-fine manner, which enables to learn a fine-grained representation to perform pixel-level discrimination for face PAD. Due to lack inductive biases of convolutions in pure transformers, we also introduce convolutions to the proposed ViTransPAD to integrate the desirable properties of CNNs by using convolution patch embedding and convolution projection. The extensive experiments show the effectiveness of our proposed ViTransPAD with a preferable accuracy-computation balance, which can serve as a new backbone for face PAD.