 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoastTerm: a Corpus for Multidisciplinary Term Extraction in Coastal Scientific Literature
Jun 13, 2024



The growing impact of climate change on coastal areas, particularly active but fragile regions, necessitates collaboration among diverse stakeholders and disciplines to formulate effective environmental protection policies. We introduce a novel specialized corpus comprising 2,491 sentences from 410 scientific abstracts concerning coastal areas, for the Automatic Term Extraction (ATE) and Classification (ATC) tasks. Inspired by the ARDI framework, focused on the identification of Actors, Resources, Dynamics and Interactions, we automatically extract domain terms and their distinct roles in the functioning of coastal systems by leveraging monolingual and multilingual transformer models. The evaluation demonstrates consistent results, achieving an F1 score of approximately 80\% for automated term extraction and F1 of 70\% for extracting terms and their labels. These findings are promising and signify an initial step towards the development of a specialized Knowledge Base dedicated to coastal areas.
IDTrust: Deep Identity Document Quality Detection with Bandpass Filtering
Mar 01, 2024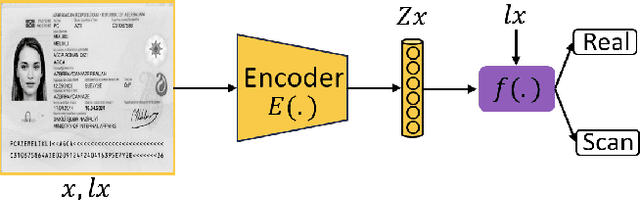
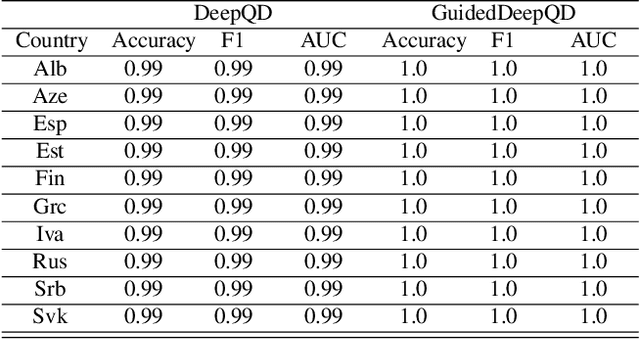
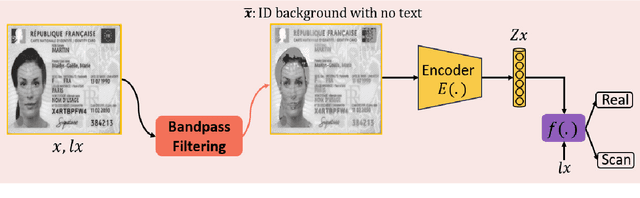
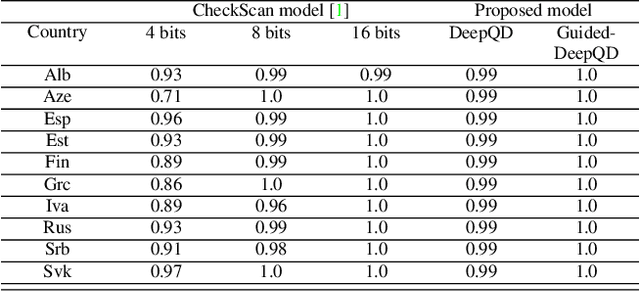
The increasing use of digital technologies and mobile-based registration procedures highlights the vital role of personal identity documents (IDs) in verifying users and safeguarding sensitive information. However, the rise in counterfeit ID production poses a significant challenge, necessitating the development of reliable and efficient automated verification methods. This paper introduces IDTrust, a deep-learning framework for assessing the quality of IDs. IDTrust is a system that enhances the quality of identification documents by using a deep learning-based approach. This method eliminates the need for relying on original document patterns for quality checks and pre-processing steps for alignment. As a result, it offers significant improvements in terms of dataset applicability. By utilizing a bandpass filtering-based method, the system aims to effectively detect and differentiate ID quality. Comprehensive experiments on the MIDV-2020 and L3i-ID datasets identify optimal parameters, significantly improving discrimination performance and effectively distinguishing between original and scanned ID documents.
A Comprehensive Survey of Document-level Relation Extraction (2016-2023)
Oct 12, 2023



Document-level relation extraction (DocRE) is an active area of research in natural language processing (NLP) concerned with identifying and extracting relationships between entities beyond sentence boundaries. Compared to the more traditional sentence-level relation extraction, DocRE provides a broader context for analysis and is more challenging because it involves identifying relationships that may span multiple sentences or paragraphs. This task has gained increased interest as a viable solution to build and populate knowledge bases automatically from unstructured large-scale documents (e.g., scientific papers, legal contracts, or news articles), in order to have a better understanding of relationships between entities. This paper aims to provide a comprehensive overview of recent advances in this field, highlighting its different applications in comparison to sentence-level relation extraction.
Named entity recognition architecture combining contextual and global features
Dec 15, 2021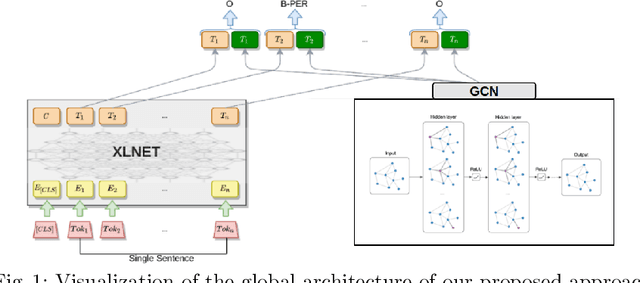
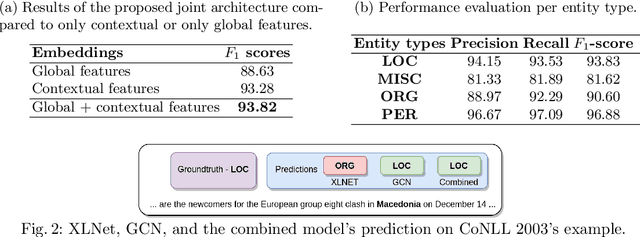
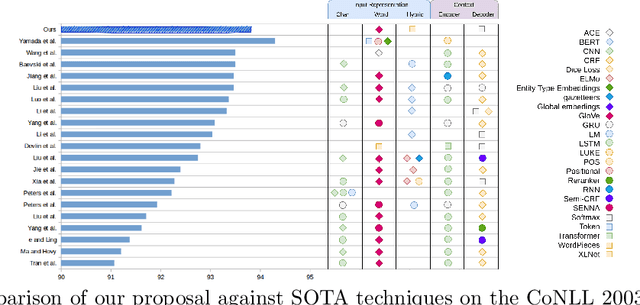
Named entity recognition (NER) is an information extraction technique that aims to locate and classify named entities (e.g., organizations, locations,...) within a document into predefined categories. Correctly identifying these phrases plays a significant role in simplifying information access. However, it remains a difficult task because named entities (NEs) have multiple forms and they are context-dependent. While the context can be represented by contextual features, global relations are often misrepresented by those models. In this paper, we propose the combination of contextual features from XLNet and global features from Graph Convolution Network (GCN) to enhance NER performance. Experiments over a widely-used dataset, CoNLL 2003, show the benefits of our strategy, with results competitive with the state of the art (SOTA).