 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Framework to Identify Self-Aspects in Text
Jul 17, 2025This Ph.D. proposal introduces a plan to develop a computational framework to identify Self-aspects in text. The Self is a multifaceted construct and it is reflected in language. While it is described across disciplines like cognitive science and phenomenology, it remains underexplored in natural language processing (NLP). Many of the aspects of the Self align with psychological and other well-researched phenomena (e.g., those related to mental health), highlighting the need for systematic NLP-based analysis. In line with this, we plan to introduce an ontology of Self-aspects and a gold-standard annotated dataset. Using this foundation, we will develop and evaluate conventional discriminative models, generative large language models, and embedding-based retrieval approaches against four main criteria: interpretability, ground-truth adherence, accuracy, and computational efficiency. Top-performing models will be applied in case studies in mental health and empirical phenomenology.
FuDoBa: Fusing Document and Knowledge Graph-based Representations with Bayesian Optimisation
Jul 09, 2025Building on the success of Large Language Models (LLMs), LLM-based representations have dominated the document representation landscape, achieving great performance on the document embedding benchmarks. However, the high-dimensional, computationally expensive embeddings from LLMs tend to be either too generic or inefficient for domain-specific applications. To address these limitations, we introduce FuDoBa a Bayesian optimisation-based method that integrates LLM-based embeddings with domain-specific structured knowledge, sourced both locally and from external repositories like WikiData. This fusion produces low-dimensional, task-relevant representations while reducing training complexity and yielding interpretable early-fusion weights for enhanced classification performance. We demonstrate the effectiveness of our approach on six datasets in two domains, showing that when paired with robust AutoML-based classifiers, our proposed representation learning approach performs on par with, or surpasses, those produced solely by the proprietary LLM-based embedding baselines.
From Symbolic to Neural and Back: Exploring Knowledge Graph-Large Language Model Synergies
Jun 11, 2025Integrating structured knowledge from Knowledge Graphs (KGs) into Large Language Models (LLMs) enhances factual grounding and reasoning capabilities. This survey paper systematically examines the synergy between KGs and LLMs, categorizing existing approaches into two main groups: KG-enhanced LLMs, which improve reasoning, reduce hallucinations, and enable complex question answering; and LLM-augmented KGs, which facilitate KG construction, completion, and querying. Through comprehensive analysis, we identify critical gaps and highlight the mutual benefits of structured knowledge integration. Compared to existing surveys, our study uniquely emphasizes scalability, computational efficiency, and data quality. Finally, we propose future research directions, including neuro-symbolic integration, dynamic KG updating, data reliability, and ethical considerations, paving the way for intelligent systems capable of managing more complex real-world knowledge tasks.
Extracting domain-specific terms using contextual word embeddings
Feb 24, 2025



Automated terminology extraction refers to the task of extracting meaningful terms from domain-specific texts. This paper proposes a novel machine learning approach to terminology extraction, which combines features from traditional term extraction systems with novel contextual features derived from contextual word embeddings. Instead of using a predefined list of part-of-speech patterns, we first analyse a new term-annotated corpus RSDO5 for the Slovenian language and devise a set of rules for term candidate selection and then generate statistical, linguistic and context-based features. We use a support-vector machine algorithm to train a classification model, evaluate it on the four domains (biomechanics, linguistics, chemistry, veterinary) of the RSDO5 corpus and compare the results with state-of-art term extraction approaches for the Slovenian language. Our approach provides significant improvements in terms of F1 score over the previous state-of-the-art, which proves that contextual word embeddings are valuable for improving term extraction.
SEKE: Specialised Experts for Keyword Extraction
Dec 18, 2024



Keyword extraction involves identifying the most descriptive words in a document, allowing automatic categorisation and summarisation of large quantities of diverse textual data. Relying on the insight that real-world keyword detection often requires handling of diverse content, we propose a novel supervised keyword extraction approach based on the mixture of experts (MoE) technique. MoE uses a learnable routing sub-network to direct information to specialised experts, allowing them to specialize in distinct regions of the input space. SEKE, a mixture of Specialised Experts for supervised Keyword Extraction, uses DeBERTa as the backbone model and builds on the MoE framework, where experts attend to each token, by integrating it with a recurrent neural network (RNN), to allow successful extraction even on smaller corpora, where specialisation is harder due to lack of training data. The MoE framework also provides an insight into inner workings of individual experts, enhancing the explainability of the approach. We benchmark SEKE on multiple English datasets, achieving state-of-the-art performance compared to strong supervised and unsupervised baselines. Our analysis reveals that depending on data size and type, experts specialize in distinct syntactic and semantic components, such as punctuation, stopwords, parts-of-speech, or named entities. Code is available at: https://github.com/matejMartinc/SEKE_keyword_extraction
Transformer verbatim in-context retrieval across time and scale
Nov 11, 2024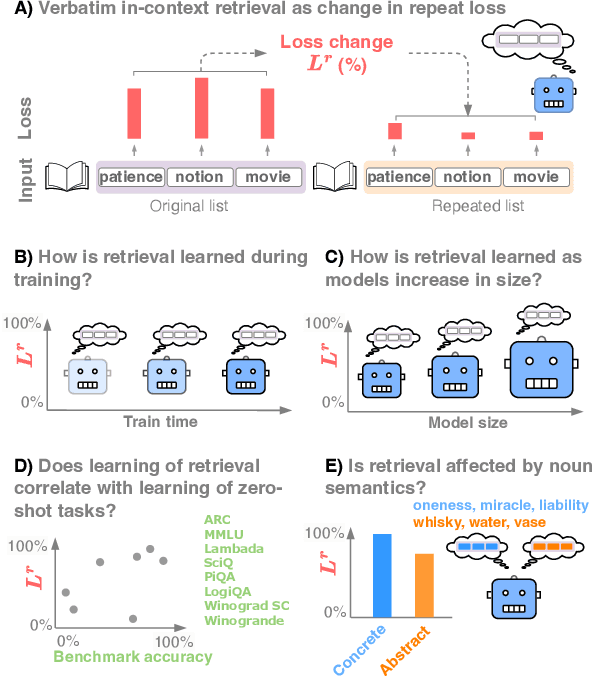

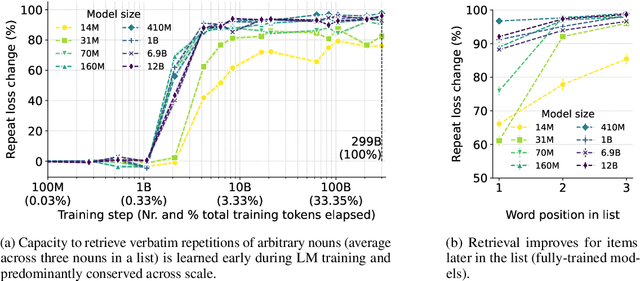

To predict upcoming text, language models must in some cases retrieve in-context information verbatim. In this report, we investigated how the ability of language models to retrieve arbitrary in-context nouns developed during training (across time) and as language models trained on the same dataset increase in size (across scale). We then asked whether learning of in-context retrieval correlates with learning of more challenging zero-shot benchmarks. Furthermore, inspired by semantic effects in human short-term memory, we evaluated the retrieval with respect to a major semantic component of target nouns, namely whether they denote a concrete or abstract entity, as rated by humans. We show that verbatim in-context retrieval developed in a sudden transition early in the training process, after about 1% of the training tokens. This was observed across model sizes (from 14M and up to 12B parameters), and the transition occurred slightly later for the two smallest models. We further found that the development of verbatim in-context retrieval is positively correlated with the learning of zero-shot benchmarks. Around the transition point, all models showed the advantage of retrieving concrete nouns as opposed to abstract nouns. In all but two smallest models, the advantage dissipated away toward the end of training.
Evaluating and explaining training strategies for zero-shot cross-lingual news sentiment analysis
Sep 30, 2024
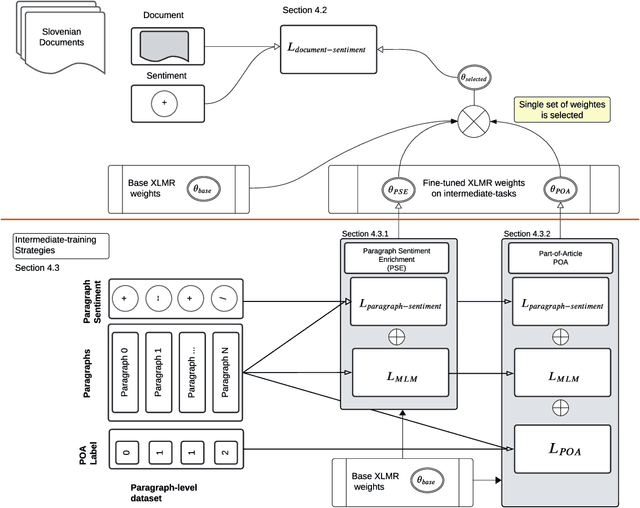
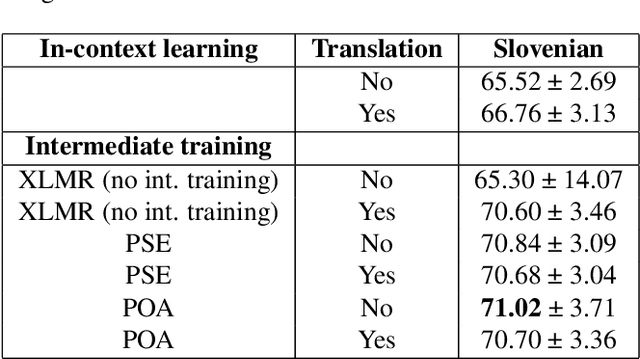
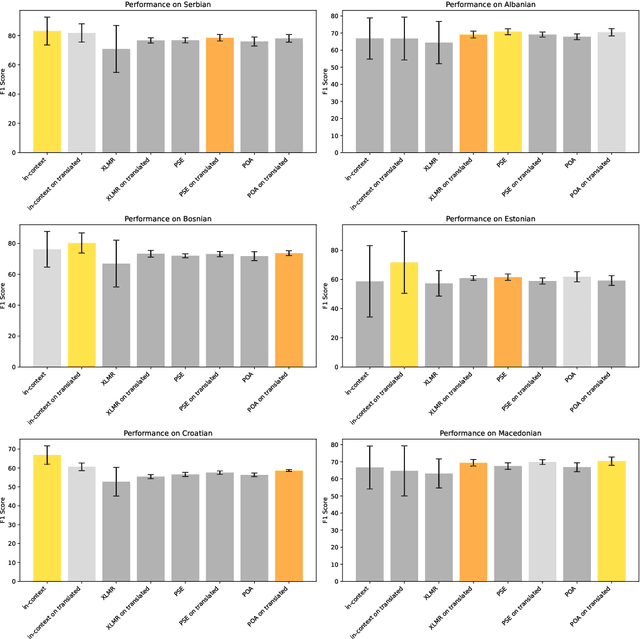
We investigate zero-shot cross-lingual news sentiment detection, aiming to develop robust sentiment classifiers that can be deployed across multiple languages without target-language training data. We introduce novel evaluation datasets in several less-resourced languages, and experiment with a range of approaches including the use of machine translation; in-context learning with large language models; and various intermediate training regimes including a novel task objective, POA, that leverages paragraph-level information. Our results demonstrate significant improvements over the state of the art, with in-context learning generally giving the best performance, but with the novel POA approach giving a competitive alternative with much lower computational overhead. We also show that language similarity is not in itself sufficient for predicting the success of cross-lingual transfer, but that similarity in semantic content and structure can be equally important.
AutoML-guided Fusion of Entity and LLM-based representations
Aug 19, 2024



Large semantic knowledge bases are grounded in factual knowledge. However, recent approaches to dense text representations (embeddings) do not efficiently exploit these resources. Dense and robust representations of documents are essential for effectively solving downstream classification and retrieval tasks. This work demonstrates that injecting embedded information from knowledge bases can augment the performance of contemporary Large Language Model (LLM)-based representations for the task of text classification. Further, by considering automated machine learning (AutoML) with the fused representation space, we demonstrate it is possible to improve classification accuracy even if we use low-dimensional projections of the original representation space obtained via efficient matrix factorization. This result shows that significantly faster classifiers can be achieved with minimal or no loss in predictive performance, as demonstrated using five strong LLM baselines on six diverse real-life datasets.
CoastTerm: a Corpus for Multidisciplinary Term Extraction in Coastal Scientific Literature
Jun 13, 2024



The growing impact of climate change on coastal areas, particularly active but fragile regions, necessitates collaboration among diverse stakeholders and disciplines to formulate effective environmental protection policies. We introduce a novel specialized corpus comprising 2,491 sentences from 410 scientific abstracts concerning coastal areas, for the Automatic Term Extraction (ATE) and Classification (ATC) tasks. Inspired by the ARDI framework, focused on the identification of Actors, Resources, Dynamics and Interactions, we automatically extract domain terms and their distinct roles in the functioning of coastal systems by leveraging monolingual and multilingual transformer models. The evaluation demonstrates consistent results, achieving an F1 score of approximately 80\% for automated term extraction and F1 of 70\% for extracting terms and their labels. These findings are promising and signify an initial step towards the development of a specialized Knowledge Base dedicated to coastal areas.
A Computational Analysis of the Dehumanisation of Migrants from Syria and Ukraine in Slovene News Media
Apr 10, 2024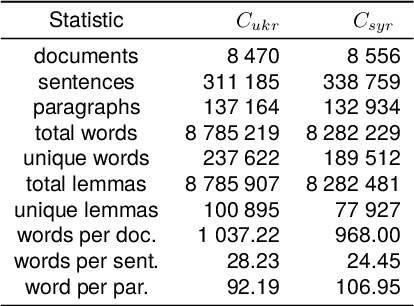

Dehumanisation involves the perception and or treatment of a social group's members as less than human. This phenomenon is rarely addressed with computational linguistic techniques. We adapt a recently proposed approach for English, making it easier to transfer to other languages and to evaluate, introducing a new sentiment resource, the use of zero-shot cross-lingual valence and arousal detection, and a new method for statistical significance testing. We then apply it to study attitudes to migration expressed in Slovene newspapers, to examine changes in the Slovene discourse on migration between the 2015-16 migration crisis following the war in Syria and the 2022-23 period following the war in Ukraine. We find that while this discourse became more negative and more intense over time, it is less dehumanising when specifically addressing Ukrainian migrants compared to others.