 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting domain-specific terms using contextual word embeddings
Feb 24, 2025



Automated terminology extraction refers to the task of extracting meaningful terms from domain-specific texts. This paper proposes a novel machine learning approach to terminology extraction, which combines features from traditional term extraction systems with novel contextual features derived from contextual word embeddings. Instead of using a predefined list of part-of-speech patterns, we first analyse a new term-annotated corpus RSDO5 for the Slovenian language and devise a set of rules for term candidate selection and then generate statistical, linguistic and context-based features. We use a support-vector machine algorithm to train a classification model, evaluate it on the four domains (biomechanics, linguistics, chemistry, veterinary) of the RSDO5 corpus and compare the results with state-of-art term extraction approaches for the Slovenian language. Our approach provides significant improvements in terms of F1 score over the previous state-of-the-art, which proves that contextual word embeddings are valuable for improving term extraction.
Evaluation of contextual embeddings on less-resourced languages
Jul 22, 2021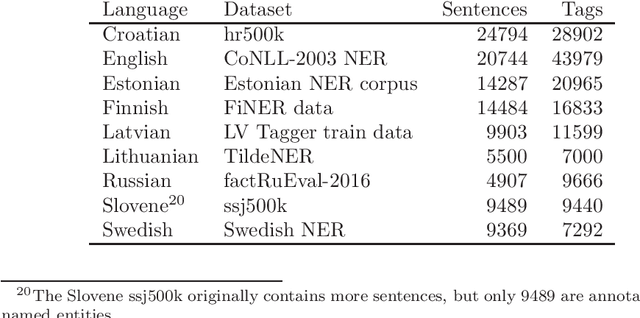


The current dominance of deep neural networks in natural language processing is based on contextual embeddings such as ELMo, BERT, and BERT derivatives. Most existing work focuses on English; in contrast, we present here the first multilingual empirical comparison of two ELMo and several monolingual and multilingual BERT models using 14 tasks in nine languages. In monolingual settings, our analysis shows that monolingual BERT models generally dominate, with a few exceptions such as the dependency parsing task, where they are not competitive with ELMo models trained on large corpora. In cross-lingual settings, BERT models trained on only a few languages mostly do best, closely followed by massively multilingual BERT models.
RaKUn: Rank-based Keyword extraction via Unsupervised learning and Meta vertex aggregation
Jul 15, 2019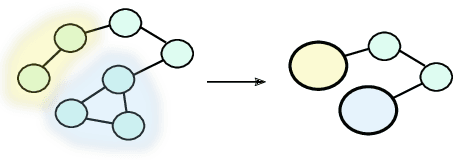
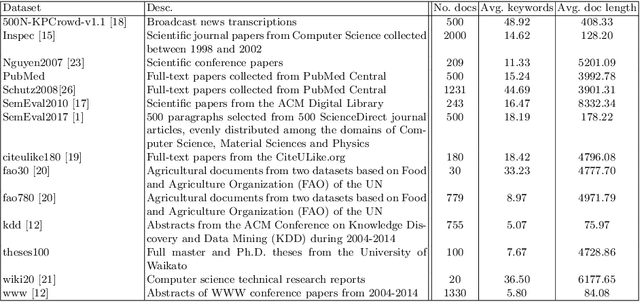


Keyword extraction is used for summarizing the content of a document and supports efficient document retrieval, and is as such an indispensable part of modern text-based systems. We explore how load centrality, a graph-theoretic measure applied to graphs derived from a given text can be used to efficiently identify and rank keywords. Introducing meta vertices (aggregates of existing vertices) and systematic redundancy filters, the proposed method performs on par with state-of-the-art for the keyword extraction task on 14 diverse datasets. The proposed method is unsupervised, interpretable and can also be used for document visualization.