 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne model to rule them all: ranking Slovene summarizers
Jun 20, 2023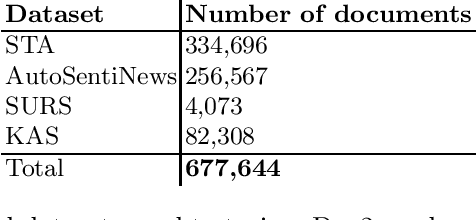


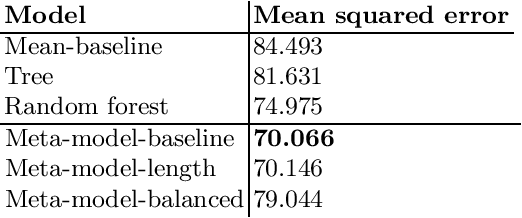
Text summarization is an essential task in natural language processing, and researchers have developed various approaches over the years, ranging from rule-based systems to neural networks. However, there is no single model or approach that performs well on every type of text. We propose a system that recommends the most suitable summarization model for a given text. The proposed system employs a fully connected neural network that analyzes the input content and predicts which summarizer should score the best in terms of ROUGE score for a given input. The meta-model selects among four different summarization models, developed for the Slovene language, using different properties of the input, in particular its Doc2Vec document representation. The four Slovene summarization models deal with different challenges associated with text summarization in a less-resourced language. We evaluate the proposed SloMetaSum model performance automatically and parts of it manually. The results show that the system successfully automates the step of manually selecting the best model.
Survey of NLP in Pharmacology: Methodology, Tasks, Resources, Knowledge, and Tools
Aug 22, 2022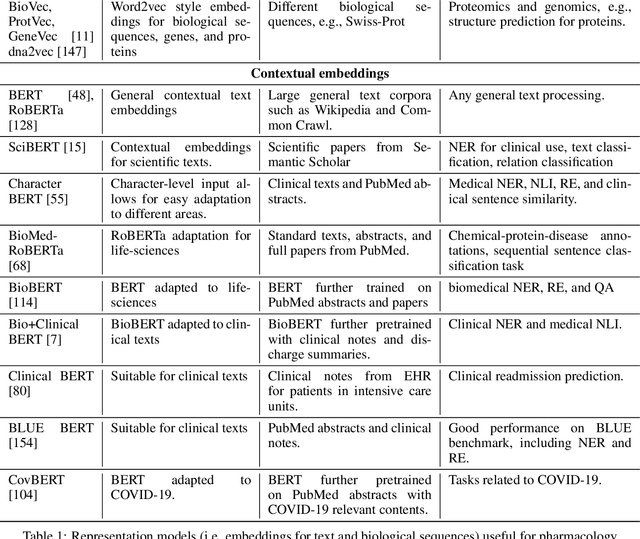

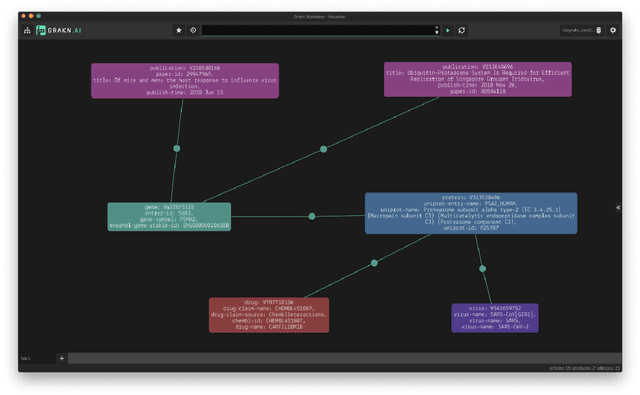
Natural language processing (NLP) is an area of artificial intelligence that applies information technologies to process the human language, understand it to a certain degree, and use it in various applications. This area has rapidly developed in the last few years and now employs modern variants of deep neural networks to extract relevant patterns from large text corpora. The main objective of this work is to survey the recent use of NLP in the field of pharmacology. As our work shows, NLP is a highly relevant information extraction and processing approach for pharmacology. It has been used extensively, from intelligent searches through thousands of medical documents to finding traces of adversarial drug interactions in social media. We split our coverage into five categories to survey modern NLP methodology, commonly addressed tasks, relevant textual data, knowledge bases, and useful programming libraries. We split each of the five categories into appropriate subcategories, describe their main properties and ideas, and summarize them in a tabular form. The resulting survey presents a comprehensive overview of the area, useful to practitioners and interested observers.
Slovene SuperGLUE Benchmark: Translation and Evaluation
Feb 10, 2022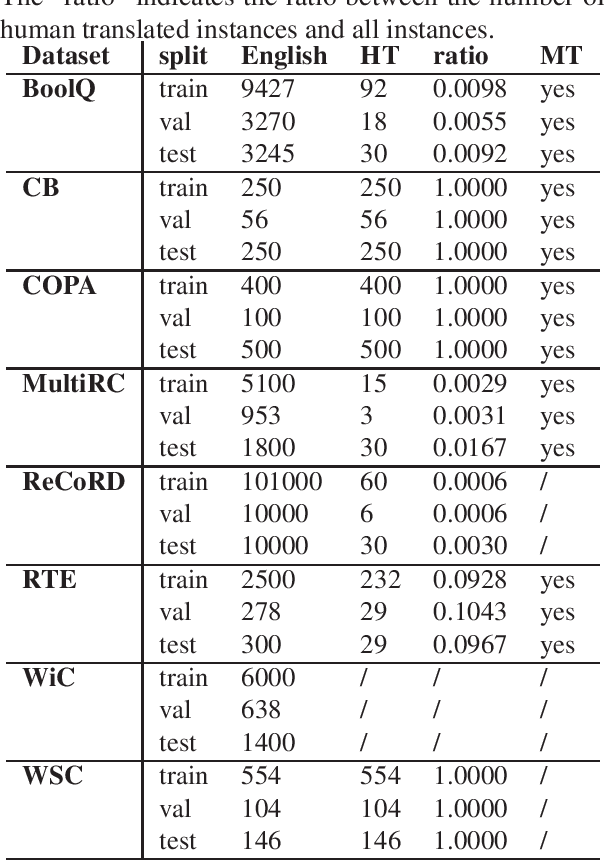
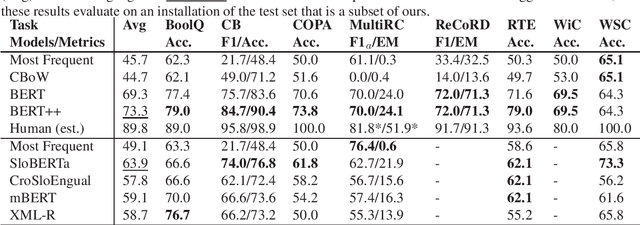


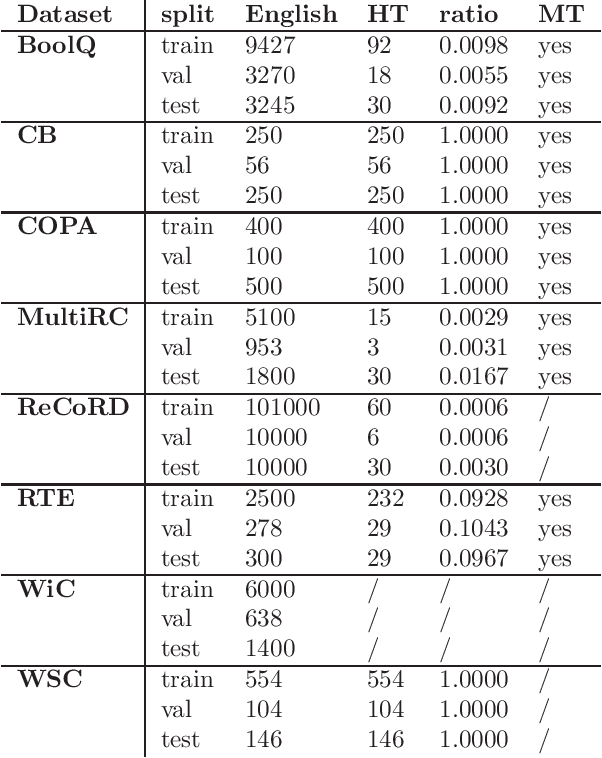
We present a Slovene combined machine-human translated SuperGLUE benchmark. We describe the translation process and problems arising due to differences in morphology and grammar. We evaluate the translated datasets in several modes: monolingual, cross-lingual, and multilingual, taking into account differences between machine and human translated training sets. The results show that the monolingual Slovene SloBERTa model is superior to massively multilingual and trilingual BERT models, but these also show a good cross-lingual performance on certain tasks. The performance of Slovene models still lags behind the best English models.
Evaluation of contextual embeddings on less-resourced languages
Jul 22, 2021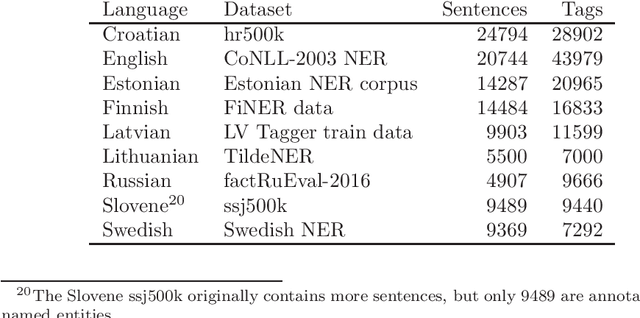


The current dominance of deep neural networks in natural language processing is based on contextual embeddings such as ELMo, BERT, and BERT derivatives. Most existing work focuses on English; in contrast, we present here the first multilingual empirical comparison of two ELMo and several monolingual and multilingual BERT models using 14 tasks in nine languages. In monolingual settings, our analysis shows that monolingual BERT models generally dominate, with a few exceptions such as the dependency parsing task, where they are not competitive with ELMo models trained on large corpora. In cross-lingual settings, BERT models trained on only a few languages mostly do best, closely followed by massively multilingual BERT models.
Cross-lingual Approach to Abstractive Summarization
Dec 08, 2020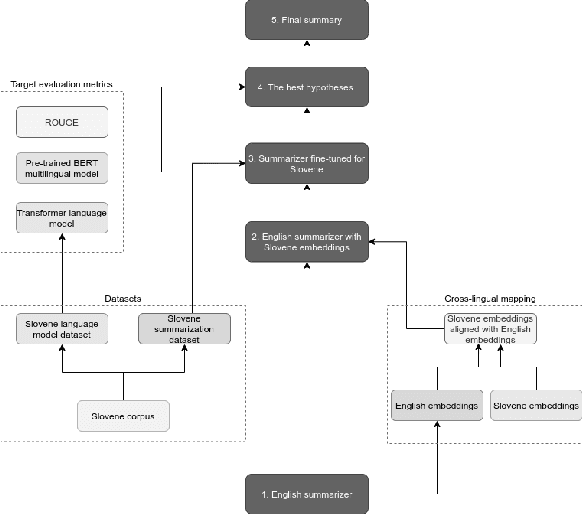

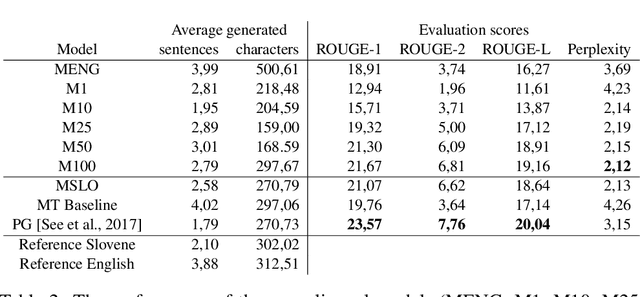
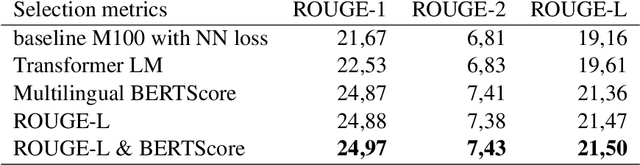
Automatic text summarization extracts important information from texts and presents the information in the form of a summary. Abstractive summarization approaches progressed significantly by switching to deep neural networks, but results are not yet satisfactory, especially for languages where large training sets do not exist. In several natural language processing tasks, cross-lingual model transfers are successfully applied in low-resource languages. For summarization such cross-lingual model transfer was so far not attempted due to a non-reusable decoder side of neural models. In our work, we used a pretrained English summarization model based on deep neural networks and sequence-to-sequence architecture to summarize Slovene news articles. We solved the problem of inadequate decoder by using an additional language model for target language evaluation. We developed several models with different proportions of target language data for fine-tuning. The results were assessed with automatic evaluation measures and with small-scale human evaluation. The results show that summaries of cross-lingual models fine-tuned with relatively small amount of target language data are useful and of similar quality to an abstractive summarizer trained with much more data in the target language.