 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Explaining Pretrained Clinical Text Classifiers
May 27, 2026Explaining the predictions of neural models in clinical NLP remains a significant challenge, especially for complex tasks involving long, unstructured medical texts. While post-hoc methods like LIME and SHAP are widely used, they often fall short when applied to clinical narratives. In this paper, we identify core limitations of token-level and perturbation-based explanation techniques through targeted demonstra- tions on a hospital length-of-stay prediction task. Our findings reveal issues such as overemphasis on non-informative tokens, instability in at- tributions, and high-confidence predictions for incoherent input variants. These results underscore the need for explanation strategies that are clin- ically meaningful, semantically grounded, and robust to linguistic noise.
* 9 pages, 7 figures. Accepted at the First Workshop on Responsible Healthcare using Machine Learning (RHCML 2025), co-located with ECML PKDD 2025
Evaluating Metalinguistic Knowledge in Large Language Models across the World's Languages
Feb 02, 2026Large language models (LLMs) are routinely evaluated on language use tasks, yet their knowledge of linguistic structure remains poorly understood. Existing linguistic benchmarks typically focus on narrow phenomena, emphasize high-resource languages, and rarely evaluate metalinguistic knowledge-explicit reasoning about language structure rather than language use. Using accuracy and macro F1, together with majority-class and chance baselines, we analyse overall performance and examine variation by linguistic domains and language-related factors. Our results show that metalinguistic knowledge in current LLMs is limited: GPT-4o performs best but achieves only moderate accuracy (0.367), while open-source models lag behind. All models perform above chance but fail to outperform the majority-class baseline, suggesting they capture cross-linguistic patterns but lack fine-grained grammatical distinctions. Performance varies across linguistic domains, with lexical features showing the highest accuracy and phonological features among the lowest, partially reflecting differences in online visibility. At the language level, accuracy shows a strong association with digital language status: languages with higher digital presence and resource availability are evaluated more accurately, while low-resource languages show substantially lower performance. Analyses of predictive factors confirm that resource-related indicators (Wikipedia size, corpus availability) are more informative predictors of accuracy than geographical, genealogical, or sociolinguistic factors. Together, these results suggest that LLMs' metalinguistic knowledge is fragmented and shaped by data availability rather than generalizable grammatical competence across the world's languages. We release our benchmark as an open-source dataset to support systematic evaluation and encourage greater global linguistic diversity in future LLMs.
Neural spell-checker: Beyond words with synthetic data generation
Oct 30, 2024Spell-checkers are valuable tools that enhance communication by identifying misspelled words in written texts. Recent improvements in deep learning, and in particular in large language models, have opened new opportunities to improve traditional spell-checkers with new functionalities that not only assess spelling correctness but also the suitability of a word for a given context. In our work, we present and compare two new spell-checkers and evaluate them on synthetic, learner, and more general-domain Slovene datasets. The first spell-checker is a traditional, fast, word-based approach, based on a morphological lexicon with a significantly larger word list compared to existing spell-checkers. The second approach uses a language model trained on a large corpus with synthetically inserted errors. We present the training data construction strategies, which turn out to be a crucial component of neural spell-checkers. Further, the proposed neural model significantly outperforms all existing spell-checkers for Slovene in both precision and recall.
Code-mixed Sentiment and Hate-speech Prediction
May 21, 2024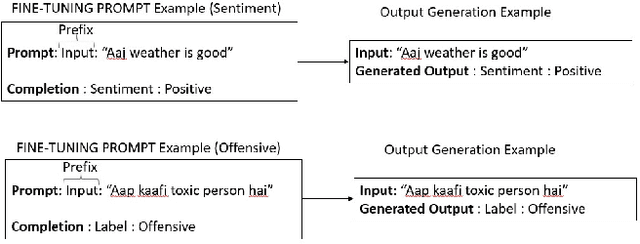



Code-mixed discourse combines multiple languages in a single text. It is commonly used in informal discourse in countries with several official languages, but also in many other countries in combination with English or neighboring languages. As recently large language models have dominated most natural language processing tasks, we investigated their performance in code-mixed settings for relevant tasks. We first created four new bilingual pre-trained masked language models for English-Hindi and English-Slovene languages, specifically aimed to support informal language. Then we performed an evaluation of monolingual, bilingual, few-lingual, and massively multilingual models on several languages, using two tasks that frequently contain code-mixed text, in particular, sentiment analysis and offensive language detection in social media texts. The results show that the most successful classifiers are fine-tuned bilingual models and multilingual models, specialized for social media texts, followed by non-specialized massively multilingual and monolingual models, while huge generative models are not competitive. For our affective problems, the models mostly perform slightly better on code-mixed data compared to non-code-mixed data.
Survey of NLP in Pharmacology: Methodology, Tasks, Resources, Knowledge, and Tools
Aug 22, 2022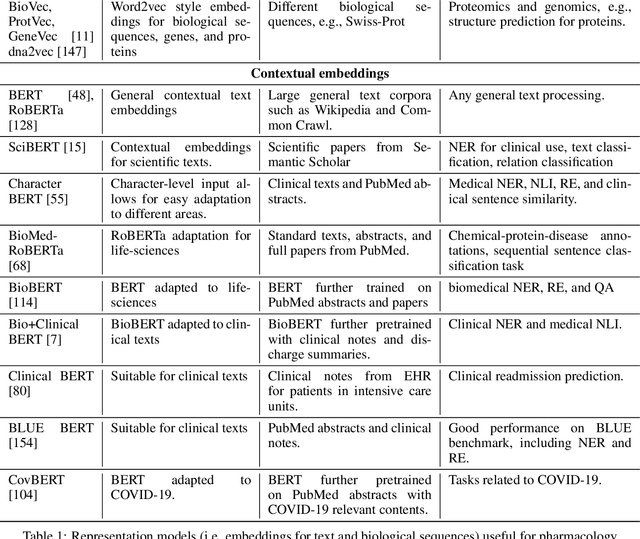

Natural language processing (NLP) is an area of artificial intelligence that applies information technologies to process the human language, understand it to a certain degree, and use it in various applications. This area has rapidly developed in the last few years and now employs modern variants of deep neural networks to extract relevant patterns from large text corpora. The main objective of this work is to survey the recent use of NLP in the field of pharmacology. As our work shows, NLP is a highly relevant information extraction and processing approach for pharmacology. It has been used extensively, from intelligent searches through thousands of medical documents to finding traces of adversarial drug interactions in social media. We split our coverage into five categories to survey modern NLP methodology, commonly addressed tasks, relevant textual data, knowledge bases, and useful programming libraries. We split each of the five categories into appropriate subcategories, describe their main properties and ideas, and summarize them in a tabular form. The resulting survey presents a comprehensive overview of the area, useful to practitioners and interested observers.
Extracting and filtering paraphrases by bridging natural language inference and paraphrasing
Nov 13, 2021
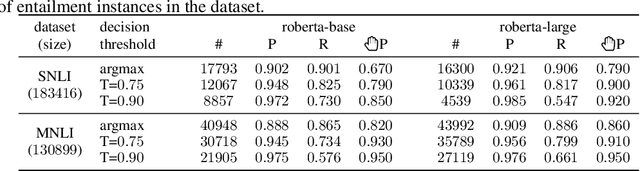
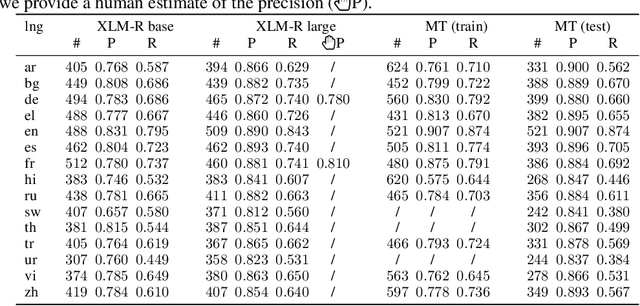

Paraphrasing is a useful natural language processing task that can contribute to more diverse generated or translated texts. Natural language inference (NLI) and paraphrasing share some similarities and can benefit from a joint approach. We propose a novel methodology for the extraction of paraphrasing datasets from NLI datasets and cleaning existing paraphrasing datasets. Our approach is based on bidirectional entailment; namely, if two sentences can be mutually entailed, they are paraphrases. We evaluate our approach using several large pretrained transformer language models in the monolingual and cross-lingual setting. The results show high quality of extracted paraphrasing datasets and surprisingly high noise levels in two existing paraphrasing datasets.
Enhancing deep neural networks with morphological information
Nov 24, 2020

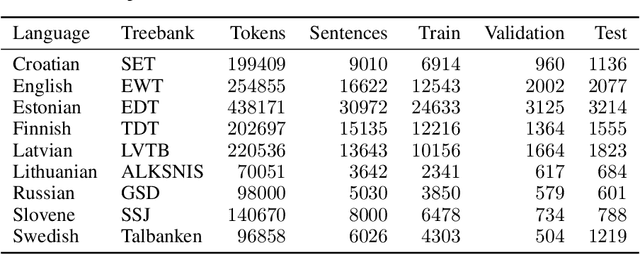

Currently, deep learning approaches are superior in natural language processing due to their ability to extract informative features and patterns from languages. Two most successful neural architectures are LSTM and transformers, the latter mostly used in the form of large pretrained language models such as BERT. While cross-lingual approaches are on the rise, a vast majority of current natural language processing techniques is designed and applied to English, and less-resourced languages are lagging behind. In morphologically rich languages, plenty of information is conveyed through changes in morphology, e.g., through different prefixes and suffixes modifying stems of words. The existing neural approaches do not explicitly use the information on word morphology. We analyze the effect of adding morphological features to LSTM and BERT models. We use three tasks available in many less-resourced languages: named entity recognition (NER), dependency parsing (DP), and comment filtering (CF). We construct sensible baselines involving LSTM and BERT models, which we adjust by adding additional input in the form of part of speech (POS) tags and universal features. We compare the obtained models across subsets of eight languages. Our results suggest that adding morphological features has mixed effects depending on the quality of features and the task. The features improve the performance of LSTM-based models on the NER and DP tasks, while they do not benefit the performance on the CF task. For BERT-based models, the added morphological features only improve the performance on DP when they are of high quality, while they do not show any practical improvement when they are predicted. As in NER and CF datasets manually checked features are not available, we only experiment with the predicted morphological features and find that they do not cause any practical improvement in performance.
Predicting kills in Game of Thrones using network properties
Jun 22, 2019
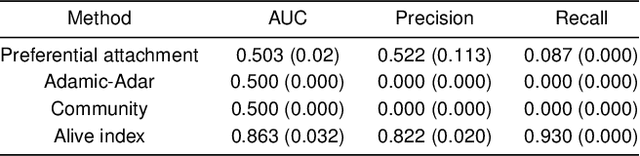
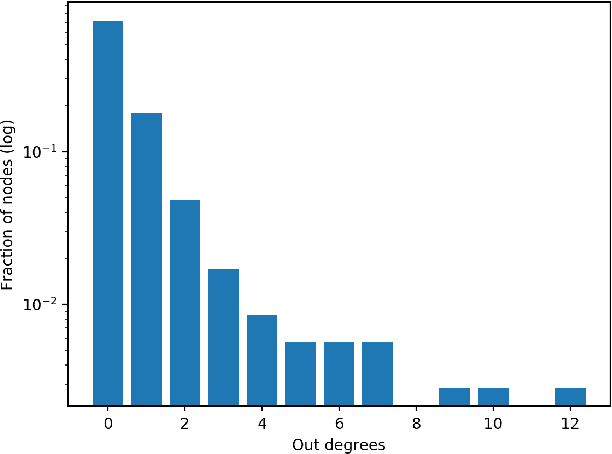
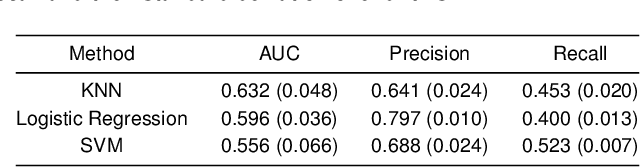
TV series such as HBO's most popular show Game of Thrones have seen a high number of dedicated followers, who watch and thoroughly analyze every minute of the show. Largely discussed aspect of the show between viewers seems to be the dramatic murders of the most important characters, the thing that the series is most known for. In our work, we try to predict characters' kills (killer and victim pairs) using data about previous kills by the characters and additional metadata. We construct a network with characters as nodes, where two nodes are linked if one killed the other. Then we use a link prediction framework and evaluate different techniques to predict the next possible kills. Lastly, we construct features from various network properties on a social network of characters, which we use in conjunction with classic data mining techniques. We see that due to the small size of the kills dataset and the somewhat random distribution of kills, we cannot predict much with standard indices. However, we show that we can construct an index which is very customized for the exact network we create for Game of Thrones but might not work on other series. We also see that the features we compute on the social network of characters help with standard machine learning approaches as well but do not yield as accurate predictions as we would hope. The best results overall are achieved by using a custom index for link prediction, which is fitting for our type of network and gives us an Area Under the ROC Curve (AUC) of 0.863.