 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing deep neural networks with morphological information
Nov 24, 2020

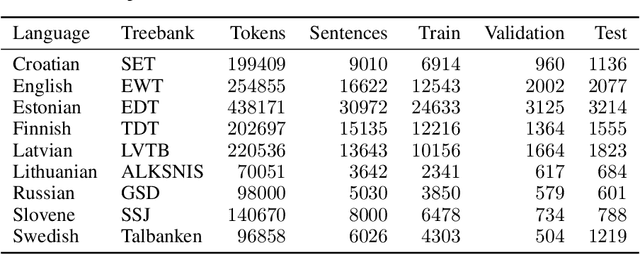

Currently, deep learning approaches are superior in natural language processing due to their ability to extract informative features and patterns from languages. Two most successful neural architectures are LSTM and transformers, the latter mostly used in the form of large pretrained language models such as BERT. While cross-lingual approaches are on the rise, a vast majority of current natural language processing techniques is designed and applied to English, and less-resourced languages are lagging behind. In morphologically rich languages, plenty of information is conveyed through changes in morphology, e.g., through different prefixes and suffixes modifying stems of words. The existing neural approaches do not explicitly use the information on word morphology. We analyze the effect of adding morphological features to LSTM and BERT models. We use three tasks available in many less-resourced languages: named entity recognition (NER), dependency parsing (DP), and comment filtering (CF). We construct sensible baselines involving LSTM and BERT models, which we adjust by adding additional input in the form of part of speech (POS) tags and universal features. We compare the obtained models across subsets of eight languages. Our results suggest that adding morphological features has mixed effects depending on the quality of features and the task. The features improve the performance of LSTM-based models on the NER and DP tasks, while they do not benefit the performance on the CF task. For BERT-based models, the added morphological features only improve the performance on DP when they are of high quality, while they do not show any practical improvement when they are predicted. As in NER and CF datasets manually checked features are not available, we only experiment with the predicted morphological features and find that they do not cause any practical improvement in performance.