 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Graph Construction Enables Robust Spectral Clustering of Texts
Mar 05, 2026Neighborhood graphs are a critical but often fragile step in spectral clustering of text embeddings. On realistic text datasets, standard $k$-NN graphs can contain many disconnected components at practical sparsity levels (small $k$), making spectral clustering degenerate and sensitive to hyperparameters. We introduce a simple incremental $k$-NN graph construction that preserves connectivity by design: each new node is linked to its $k$ nearest previously inserted nodes, which guarantees a connected graph for any $k$. We provide an inductive proof of connectedness and discuss implications for incremental updates when new documents arrive. We validate the approach on spectral clustering of SentenceTransformer embeddings using Laplacian eigenmaps across six clustering datasets from the Massive Text Embedding Benchmark. Compared to standard $k$-NN graphs, our method outperforms in the low-$k$ regime where disconnected components are prevalent, and matches standard $k$-NN at larger $k$.
Building a Strong Instruction Language Model for a Less-Resourced Language
Mar 02, 2026Large language models (LLMs) have become an essential tool for natural language processing and artificial intelligence in general. Current open-source models are primarily trained on English texts, resulting in poorer performance on less-resourced languages and cultures. We present a set of methodological approaches necessary for the successful adaptation of an LLM to a less-resourced language, and demonstrate them using the Slovene language. We present GaMS3-12B, a generative model for Slovene with 12 billion parameters, and demonstrate that it is the best-performing open-source model for Slovene within its parameter range. We adapted the model to the Slovene language using three-stage continual pre-training of the Gemma 3 model, followed by two-stage supervised fine-tuning (SFT). We trained the model on a combination of 140B Slovene, English, Bosnian, Serbian, and Croatian pretraining tokens, and over 200 thousand English and Slovene SFT examples. We evaluate GaMS3-12B on the Slovenian-LLM-Eval datasets, English-to-Slovene translation, and the Slovene LLM arena. We show that the described model outperforms 12B Gemma 3 across all three scenarios and performs comparably to much larger commercial GPT-4o in the Slovene LLM arena, achieving a win rate of over 60 %.
Evaluating Metalinguistic Knowledge in Large Language Models across the World's Languages
Feb 02, 2026Large language models (LLMs) are routinely evaluated on language use tasks, yet their knowledge of linguistic structure remains poorly understood. Existing linguistic benchmarks typically focus on narrow phenomena, emphasize high-resource languages, and rarely evaluate metalinguistic knowledge-explicit reasoning about language structure rather than language use. Using accuracy and macro F1, together with majority-class and chance baselines, we analyse overall performance and examine variation by linguistic domains and language-related factors. Our results show that metalinguistic knowledge in current LLMs is limited: GPT-4o performs best but achieves only moderate accuracy (0.367), while open-source models lag behind. All models perform above chance but fail to outperform the majority-class baseline, suggesting they capture cross-linguistic patterns but lack fine-grained grammatical distinctions. Performance varies across linguistic domains, with lexical features showing the highest accuracy and phonological features among the lowest, partially reflecting differences in online visibility. At the language level, accuracy shows a strong association with digital language status: languages with higher digital presence and resource availability are evaluated more accurately, while low-resource languages show substantially lower performance. Analyses of predictive factors confirm that resource-related indicators (Wikipedia size, corpus availability) are more informative predictors of accuracy than geographical, genealogical, or sociolinguistic factors. Together, these results suggest that LLMs' metalinguistic knowledge is fragmented and shaped by data availability rather than generalizable grammatical competence across the world's languages. We release our benchmark as an open-source dataset to support systematic evaluation and encourage greater global linguistic diversity in future LLMs.
Improving LLMs for Machine Translation Using Synthetic Preference Data
Aug 20, 2025Large language models have emerged as effective machine translation systems. In this paper, we explore how a general instruction-tuned large language model can be improved for machine translation using relatively few easily produced data resources. Using Slovene as a use case, we improve the GaMS-9B-Instruct model using Direct Preference Optimization (DPO) training on a programmatically curated and enhanced subset of a public dataset. As DPO requires pairs of quality-ranked instances, we generated its training dataset by translating English Wikipedia articles using two LLMs, GaMS-9B-Instruct and EuroLLM-9B-Instruct. We ranked the resulting translations based on heuristics coupled with automatic evaluation metrics such as COMET. The evaluation shows that our fine-tuned model outperforms both models involved in the dataset generation. In comparison to the baseline models, the fine-tuned model achieved a COMET score gain of around 0.04 and 0.02, respectively, on translating Wikipedia articles. It also more consistently avoids language and formatting errors.
Solving Word-Sense Disambiguation and Word-Sense Induction with Dictionary Examples
Mar 06, 2025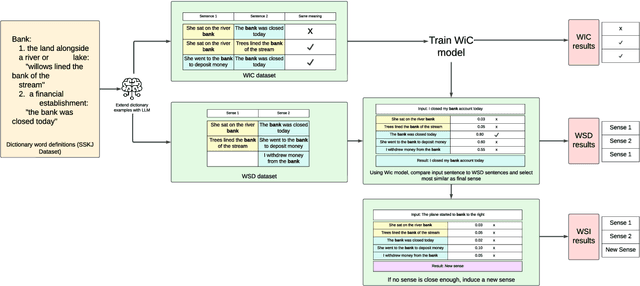



Many less-resourced languages struggle with a lack of large, task-specific datasets that are required for solving relevant tasks with modern transformer-based large language models (LLMs). On the other hand, many linguistic resources, such as dictionaries, are rarely used in this context despite their large information contents. We show how LLMs can be used to extend existing language resources in less-resourced languages for two important tasks: word-sense disambiguation (WSD) and word-sense induction (WSI). We approach the two tasks through the related but much more accessible word-in-context (WiC) task where, given a pair of sentences and a target word, a classification model is tasked with predicting whether the sense of a given word differs between sentences. We demonstrate that a well-trained model for this task can distinguish between different word senses and can be adapted to solve the WSD and WSI tasks. The advantage of using the WiC task, instead of directly predicting senses, is that the WiC task does not need pre-constructed sense inventories with a sufficient number of examples for each sense, which are rarely available in less-resourced languages. We show that sentence pairs for the WiC task can be successfully generated from dictionary examples using LLMs. The resulting prediction models outperform existing models on WiC, WSD, and WSI tasks. We demonstrate our methodology on the Slovene language, where a monolingual dictionary is available, but word-sense resources are tiny.
Neural spell-checker: Beyond words with synthetic data generation
Oct 30, 2024Spell-checkers are valuable tools that enhance communication by identifying misspelled words in written texts. Recent improvements in deep learning, and in particular in large language models, have opened new opportunities to improve traditional spell-checkers with new functionalities that not only assess spelling correctness but also the suitability of a word for a given context. In our work, we present and compare two new spell-checkers and evaluate them on synthetic, learner, and more general-domain Slovene datasets. The first spell-checker is a traditional, fast, word-based approach, based on a morphological lexicon with a significantly larger word list compared to existing spell-checkers. The second approach uses a language model trained on a large corpus with synthetically inserted errors. We present the training data construction strategies, which turn out to be a crucial component of neural spell-checkers. Further, the proposed neural model significantly outperforms all existing spell-checkers for Slovene in both precision and recall.
Sarcasm Detection in a Less-Resourced Language
Oct 16, 2024
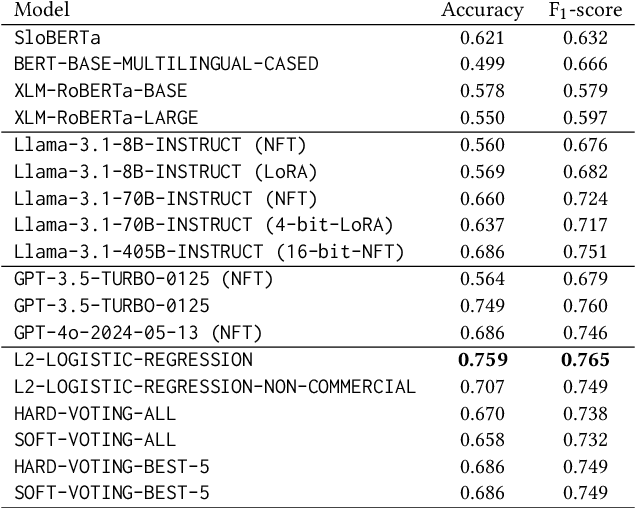
The sarcasm detection task in natural language processing tries to classify whether an utterance is sarcastic or not. It is related to sentiment analysis since it often inverts surface sentiment. Because sarcastic sentences are highly dependent on context, and they are often accompanied by various non-verbal cues, the task is challenging. Most of related work focuses on high-resourced languages like English. To build a sarcasm detection dataset for a less-resourced language, such as Slovenian, we leverage two modern techniques: a machine translation specific medium-size transformer model, and a very large generative language model. We explore the viability of translated datasets and how the size of a pretrained transformer affects its ability to detect sarcasm. We train ensembles of detection models and evaluate models' performance. The results show that larger models generally outperform smaller ones and that ensembling can slightly improve sarcasm detection performance. Our best ensemble approach achieves an $\text{F}_1$-score of 0.765 which is close to annotators' agreement in the source language.
* 4 pages, published in the Slovenian Conference on Artificial Intelligence
Generative Model for Less-Resourced Language with 1 billion parameters
Oct 09, 2024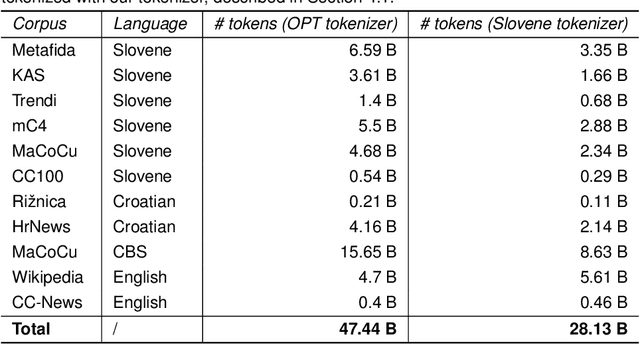
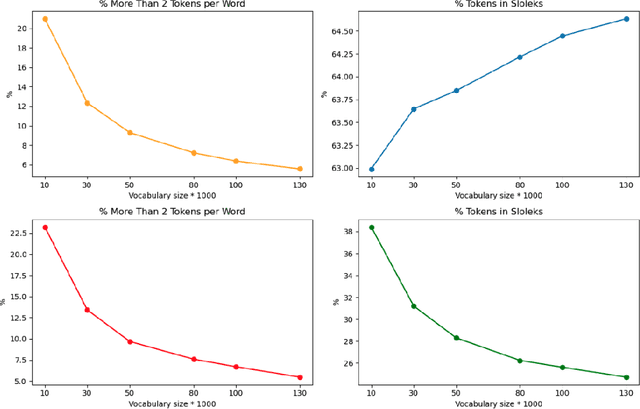
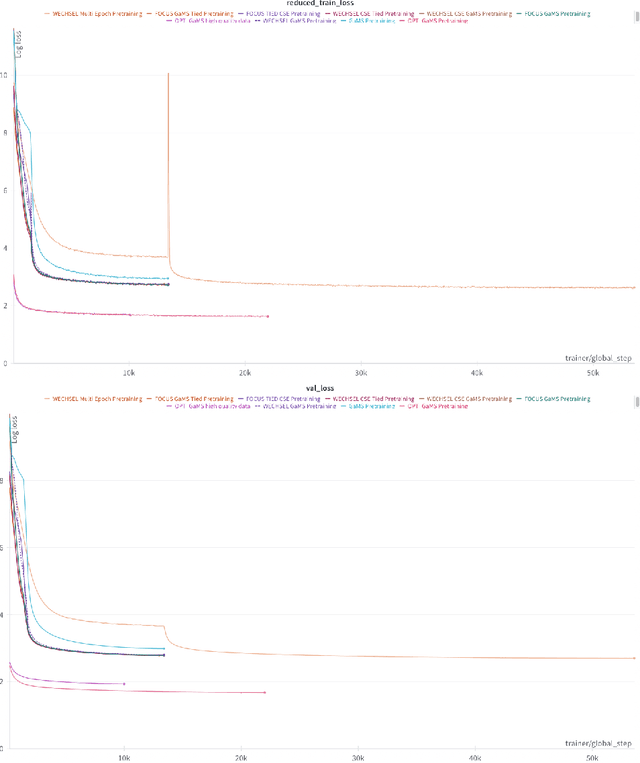
Large language models (LLMs) are a basic infrastructure for modern natural language processing. Many commercial and open-source LLMs exist for English, e.g., ChatGPT, Llama, Falcon, and Mistral. As these models are trained on mostly English texts, their fluency and knowledge of low-resource languages and societies are superficial. We present the development of large generative language models for a less-resourced language. GaMS 1B - Generative Model for Slovene with 1 billion parameters was created by continuing pretraining of the existing English OPT model. We developed a new tokenizer adapted to Slovene, Croatian, and English languages and used embedding initialization methods FOCUS and WECHSEL to transfer the embeddings from the English OPT model. We evaluate our models on several classification datasets from the Slovene suite of benchmarks and generative sentence simplification task SENTA. We only used a few-shot in-context learning of our models, which are not yet instruction-tuned. For classification tasks, in this mode, the generative models lag behind the existing Slovene BERT-type models fine-tuned for specific tasks. On a sentence simplification task, the GaMS models achieve comparable or better performance than the GPT-3.5-Turbo model.
Retrieval-augmented code completion for local projects using large language models
Aug 09, 2024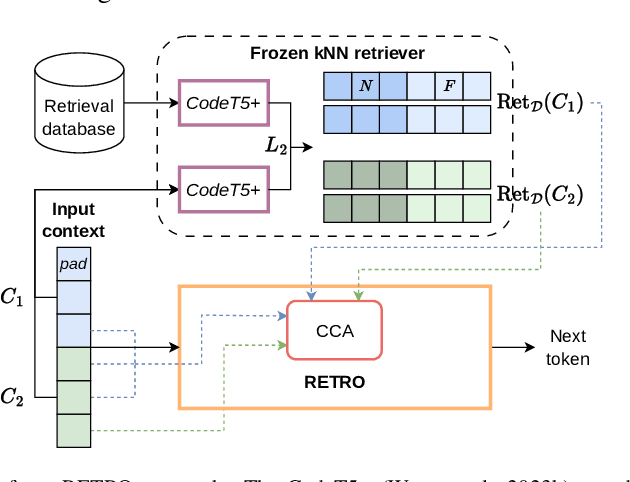
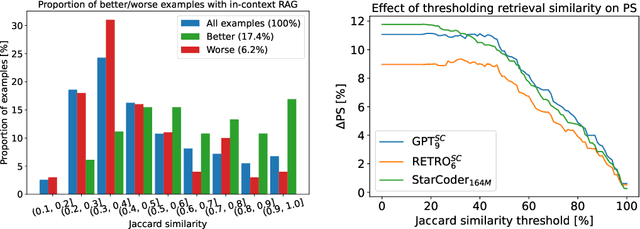
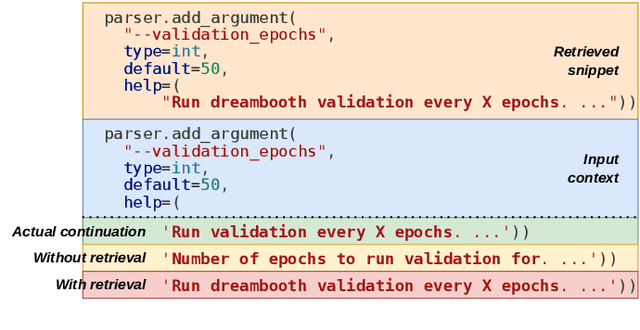

The use of large language models (LLMs) is becoming increasingly widespread among software developers. However, privacy and computational requirements are problematic with commercial solutions and the use of LLMs. In this work, we focus on using LLMs with around 160 million parameters that are suitable for local execution and augmentation with retrieval from local projects. We train two models based on the transformer architecture, the generative model GPT-2 and the retrieval-adapted RETRO model, on open-source Python files, and empirically evaluate and compare them, confirming the benefits of vector embedding based retrieval. Further, we improve our models' performance with In-context retrieval-augmented generation, which retrieves code snippets based on the Jaccard similarity of tokens. We evaluate In-context retrieval-augmented generation on larger models and conclude that, despite its simplicity, the approach is more suitable than using the RETRO architecture. We highlight the key role of proper tokenization in achieving the full potential of LLMs in code completion.
Measuring Catastrophic Forgetting in Cross-Lingual Transfer Paradigms: Exploring Tuning Strategies
Sep 12, 2023


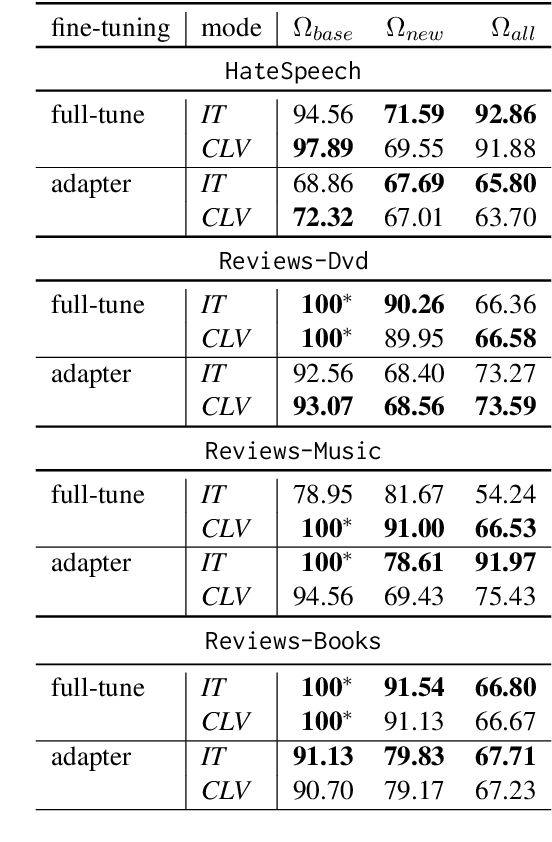
The cross-lingual transfer is a promising technique to solve tasks in less-resourced languages. In this empirical study, we compare two fine-tuning approaches combined with zero-shot and full-shot learning approaches for large language models in a cross-lingual setting. As fine-tuning strategies, we compare parameter-efficient adapter methods with fine-tuning of all parameters. As cross-lingual transfer strategies, we compare the intermediate-training (\textit{IT}) that uses each language sequentially and cross-lingual validation (\textit{CLV}) that uses a target language already in the validation phase of fine-tuning. We assess the success of transfer and the extent of catastrophic forgetting in a source language due to cross-lingual transfer, i.e., how much previously acquired knowledge is lost when we learn new information in a different language. The results on two different classification problems, hate speech detection and product reviews, each containing datasets in several languages, show that the \textit{IT} cross-lingual strategy outperforms \textit{CLV} for the target language. Our findings indicate that, in the majority of cases, the \textit{CLV} strategy demonstrates superior retention of knowledge in the base language (English) compared to the \textit{IT} strategy, when evaluating catastrophic forgetting in multiple cross-lingual transfers.