 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Catastrophic Forgetting in Cross-Lingual Transfer Paradigms: Exploring Tuning Strategies
Paper and Code
Sep 12, 2023


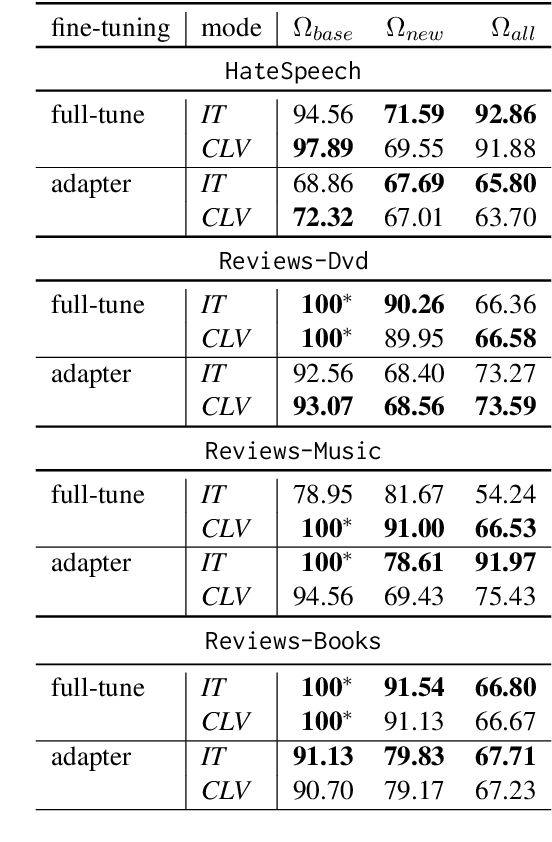
The cross-lingual transfer is a promising technique to solve tasks in less-resourced languages. In this empirical study, we compare two fine-tuning approaches combined with zero-shot and full-shot learning approaches for large language models in a cross-lingual setting. As fine-tuning strategies, we compare parameter-efficient adapter methods with fine-tuning of all parameters. As cross-lingual transfer strategies, we compare the intermediate-training (\textit{IT}) that uses each language sequentially and cross-lingual validation (\textit{CLV}) that uses a target language already in the validation phase of fine-tuning. We assess the success of transfer and the extent of catastrophic forgetting in a source language due to cross-lingual transfer, i.e., how much previously acquired knowledge is lost when we learn new information in a different language. The results on two different classification problems, hate speech detection and product reviews, each containing datasets in several languages, show that the \textit{IT} cross-lingual strategy outperforms \textit{CLV} for the target language. Our findings indicate that, in the majority of cases, the \textit{CLV} strategy demonstrates superior retention of knowledge in the base language (English) compared to the \textit{IT} strategy, when evaluating catastrophic forgetting in multiple cross-lingual transfers.