 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuDoBa: Fusing Document and Knowledge Graph-based Representations with Bayesian Optimisation
Jul 09, 2025Building on the success of Large Language Models (LLMs), LLM-based representations have dominated the document representation landscape, achieving great performance on the document embedding benchmarks. However, the high-dimensional, computationally expensive embeddings from LLMs tend to be either too generic or inefficient for domain-specific applications. To address these limitations, we introduce FuDoBa a Bayesian optimisation-based method that integrates LLM-based embeddings with domain-specific structured knowledge, sourced both locally and from external repositories like WikiData. This fusion produces low-dimensional, task-relevant representations while reducing training complexity and yielding interpretable early-fusion weights for enhanced classification performance. We demonstrate the effectiveness of our approach on six datasets in two domains, showing that when paired with robust AutoML-based classifiers, our proposed representation learning approach performs on par with, or surpasses, those produced solely by the proprietary LLM-based embedding baselines.
From Symbolic to Neural and Back: Exploring Knowledge Graph-Large Language Model Synergies
Jun 11, 2025Integrating structured knowledge from Knowledge Graphs (KGs) into Large Language Models (LLMs) enhances factual grounding and reasoning capabilities. This survey paper systematically examines the synergy between KGs and LLMs, categorizing existing approaches into two main groups: KG-enhanced LLMs, which improve reasoning, reduce hallucinations, and enable complex question answering; and LLM-augmented KGs, which facilitate KG construction, completion, and querying. Through comprehensive analysis, we identify critical gaps and highlight the mutual benefits of structured knowledge integration. Compared to existing surveys, our study uniquely emphasizes scalability, computational efficiency, and data quality. Finally, we propose future research directions, including neuro-symbolic integration, dynamic KG updating, data reliability, and ethical considerations, paving the way for intelligent systems capable of managing more complex real-world knowledge tasks.
LLM Embeddings for Deep Learning on Tabular Data
Feb 17, 2025Tabular deep-learning methods require embedding numerical and categorical input features into high-dimensional spaces before processing them. Existing methods deal with this heterogeneous nature of tabular data by employing separate type-specific encoding approaches. This limits the cross-table transfer potential and the exploitation of pre-trained knowledge. We propose a novel approach that first transforms tabular data into text, and then leverages pre-trained representations from LLMs to encode this data, resulting in a plug-and-play solution to improv ing deep-learning tabular methods. We demonstrate that our approach improves accuracy over competitive models, such as MLP, ResNet and FT-Transformer, by validating on seven classification datasets.
HorNets: Learning from Discrete and Continuous Signals with Routing Neural Networks
Jan 24, 2025Construction of neural network architectures suitable for learning from both continuous and discrete tabular data is a challenging research endeavor. Contemporary high-dimensional tabular data sets are often characterized by a relatively small instance count, requiring data-efficient learning. We propose HorNets (Horn Networks), a neural network architecture with state-of-the-art performance on synthetic and real-life data sets from scarce-data tabular domains. HorNets are based on a clipped polynomial-like activation function, extended by a custom discrete-continuous routing mechanism that decides which part of the neural network to optimize based on the input's cardinality. By explicitly modeling parts of the feature combination space or combining whole space in a linear attention-like manner, HorNets dynamically decide which mode of operation is the most suitable for a given piece of data with no explicit supervision. This architecture is one of the few approaches that reliably retrieves logical clauses (including noisy XNOR) and achieves state-of-the-art classification performance on 14 real-life biomedical high-dimensional data sets. HorNets are made freely available under a permissive license alongside a synthetic generator of categorical benchmarks.
Generating Diverse Synthetic Datasets for Evaluation of Real-life Recommender Systems
Nov 27, 2024



Synthetic datasets are important for evaluating and testing machine learning models. When evaluating real-life recommender systems, high-dimensional categorical (and sparse) datasets are often considered. Unfortunately, there are not many solutions that would allow generation of artificial datasets with such characteristics. For that purpose, we developed a novel framework for generating synthetic datasets that are diverse and statistically coherent. Our framework allows for creation of datasets with controlled attributes, enabling iterative modifications to fit specific experimental needs, such as introducing complex feature interactions, feature cardinality, or specific distributions. We demonstrate the framework's utility through use cases such as benchmarking probabilistic counting algorithms, detecting algorithmic bias, and simulating AutoML searches. Unlike existing methods that either focus narrowly on specific dataset structures, or prioritize (private) data synthesis through real data, our approach provides a modular means to quickly generating completely synthetic datasets we can tailor to diverse experimental requirements. Our results show that the framework effectively isolates model behavior in unique situations and highlights its potential for significant advancements in the evaluation and development of recommender systems. The readily-available framework is available as a free open Python package to facilitate research with minimal friction.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024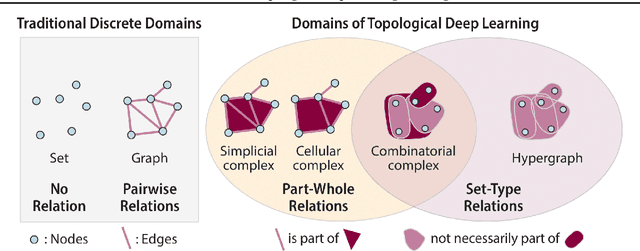
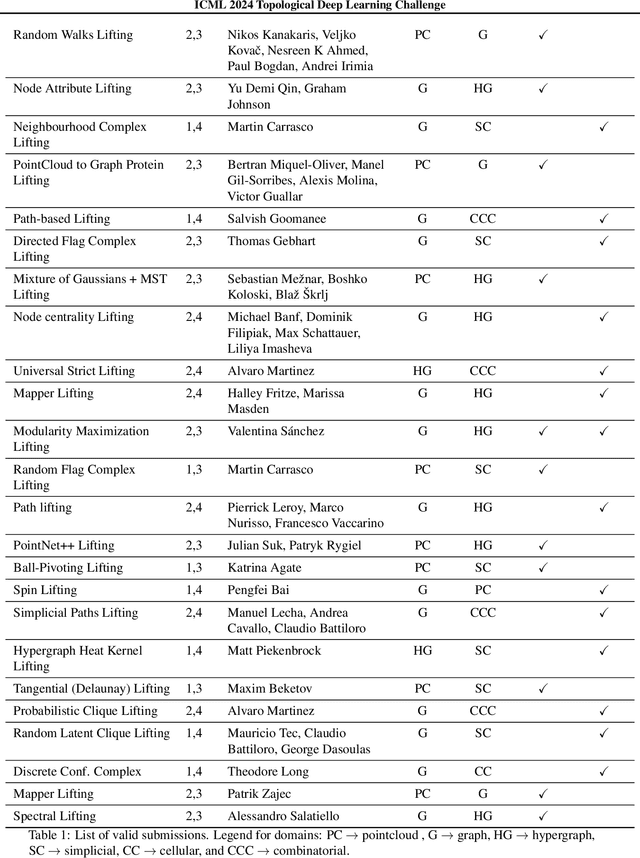
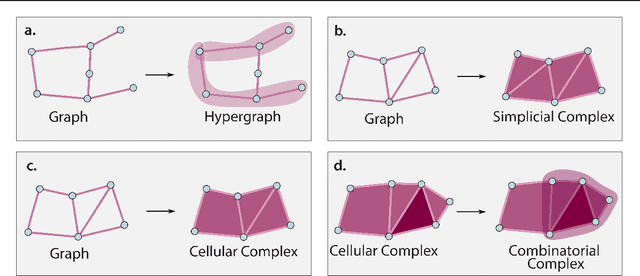
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
AutoML-guided Fusion of Entity and LLM-based representations
Aug 19, 2024



Large semantic knowledge bases are grounded in factual knowledge. However, recent approaches to dense text representations (embeddings) do not efficiently exploit these resources. Dense and robust representations of documents are essential for effectively solving downstream classification and retrieval tasks. This work demonstrates that injecting embedded information from knowledge bases can augment the performance of contemporary Large Language Model (LLM)-based representations for the task of text classification. Further, by considering automated machine learning (AutoML) with the fused representation space, we demonstrate it is possible to improve classification accuracy even if we use low-dimensional projections of the original representation space obtained via efficient matrix factorization. This result shows that significantly faster classifiers can be achieved with minimal or no loss in predictive performance, as demonstrated using five strong LLM baselines on six diverse real-life datasets.
A Bag of Tricks for Scaling CPU-based Deep FFMs to more than 300m Predictions per Second
Jul 14, 2024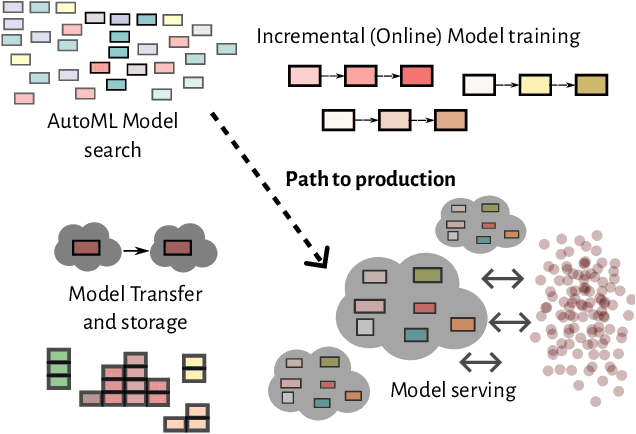
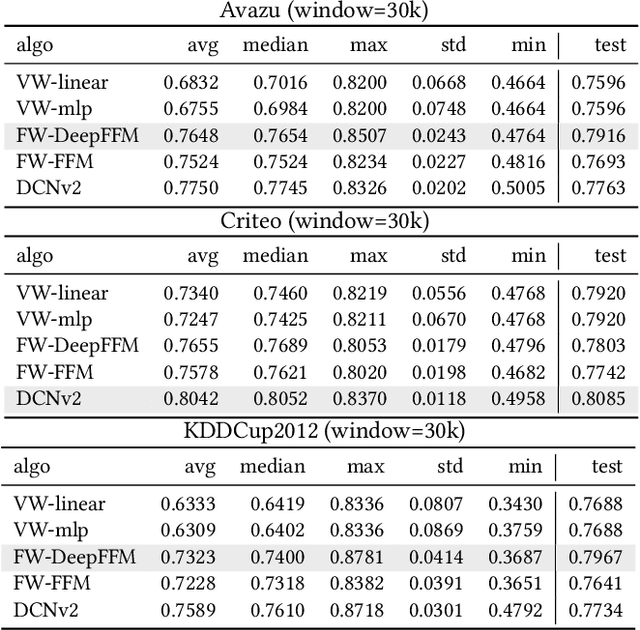
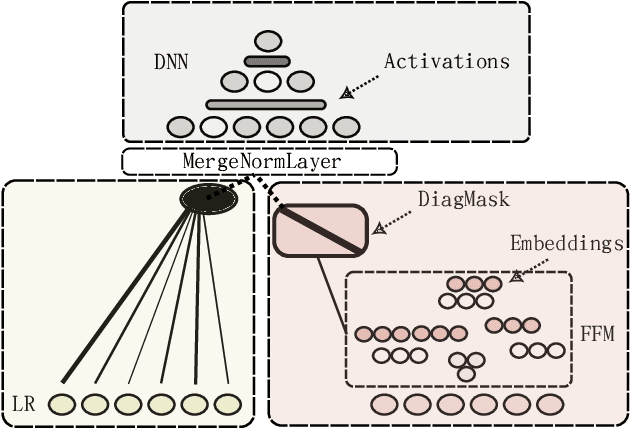

Field-aware Factorization Machines (FFMs) have emerged as a powerful model for click-through rate prediction, particularly excelling in capturing complex feature interactions. In this work, we present an in-depth analysis of our in-house, Rust-based Deep FFM implementation, and detail its deployment on a CPU-only, multi-data-center scale. We overview key optimizations devised for both training and inference, demonstrated by previously unpublished benchmark results in efficient model search and online training. Further, we detail an in-house weight quantization that resulted in more than an order of magnitude reduction in bandwidth footprint related to weight transfers across data-centres. We disclose the engine and associated techniques under an open-source license to contribute to the broader machine learning community. This paper showcases one of the first successful CPU-only deployments of Deep FFMs at such scale, marking a significant stride in practical, low-footprint click-through rate prediction methodologies.
AHAM: Adapt, Help, Ask, Model -- Harvesting LLMs for literature mining
Dec 25, 2023In an era marked by a rapid increase in scientific publications, researchers grapple with the challenge of keeping pace with field-specific advances. We present the `AHAM' methodology and a metric that guides the domain-specific \textbf{adapt}ation of the BERTopic topic modeling framework to improve scientific text analysis. By utilizing the LLaMa2 generative language model, we generate topic definitions via one-shot learning by crafting prompts with the \textbf{help} of domain experts to guide the LLM for literature mining by \textbf{asking} it to model the topic names. For inter-topic similarity evaluation, we leverage metrics from language generation and translation processes to assess lexical and semantic similarity of the generated topics. Our system aims to reduce both the ratio of outlier topics to the total number of topics and the similarity between topic definitions. The methodology has been assessed on a newly gathered corpus of scientific papers on literature-based discovery. Through rigorous evaluation by domain experts, AHAM has been validated as effective in uncovering intriguing and novel insights within broad research areas. We explore the impact of domain adaptation of sentence-transformers for the task of topic \textbf{model}ing using two datasets, each specialized to specific scientific domains within arXiv and medarxiv. We evaluate the impact of data size, the niche of adaptation, and the importance of domain adaptation. Our results suggest a strong interaction between domain adaptation and topic modeling precision in terms of outliers and topic definitions.
Latent Graphs for Semi-Supervised Learning on Biomedical Tabular Data
Oct 14, 2023



In the domain of semi-supervised learning, the current approaches insufficiently exploit the potential of considering inter-instance relationships among (un)labeled data. In this work, we address this limitation by providing an approach for inferring latent graphs that capture the intrinsic data relationships. By leveraging graph-based representations, our approach facilitates the seamless propagation of information throughout the graph, effectively incorporating global and local knowledge. Through evaluations on biomedical tabular datasets, we compare the capabilities of our approach to other contemporary methods. Our work demonstrates the significance of inter-instance relationship discovery as practical means for constructing robust latent graphs to enhance semi-supervised learning techniques. The experiments show that the proposed methodology outperforms contemporary state-of-the-art methods for (semi-)supervised learning on three biomedical datasets.