 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization in Autoregressive Models via Logit Composition
May 27, 2026Composing autoregressive models remains a core challenge in understanding how large language models can combine behaviors or skills learned across tasks. We introduce a new and principled composition strategy for autoregressive systems, inspired by composition methods developed for diffusion models. Under a factorized-conditionals assumption, we show that the resulting composition is projective: each component model preserves control over its own designated subspace of the output distribution avoiding interference between models. This property is further preserved under smooth reparameterizations of the output space, yielding a feature-space theorem. Finally, we show that composition preserves length-generalizing behavior when the factorization assumptions and component guarantees hold uniformly at the target length. These results provide a principled understanding of when model composition and merging succeed in autoregressive systems and identify conditions under which their interactions remain stable.
Select, Label, Evaluate: Active Testing in NLP
Mar 23, 2026Human annotation cost and time remain significant bottlenecks in Natural Language Processing (NLP), with test data annotation being particularly expensive due to the stringent requirement for low-error and high-quality labels necessary for reliable model evaluation. Traditional approaches require annotating entire test sets, leading to substantial resource requirements. Active Testing is a framework that selects the most informative test samples for annotation. Given a labeling budget, it aims to choose the subset that best estimates model performance while minimizing cost and human effort. In this work, we formalize Active Testing in NLP and we conduct an extensive benchmarking of existing approaches across 18 datasets and 4 embedding strategies spanning 4 different NLP tasks. The experiments show annotation reductions of up to 95%, with performance estimation accuracy difference from the full test set within 1%. Our analysis reveals variations in method effectiveness across different data characteristics and task types, with no single approach emerging as universally superior. Lastly, to address the limitation of requiring a predefined annotation budget in existing sample selection strategies, we introduce an adaptive stopping criterion that automatically determines the optimal number of samples.
Same Answer, Different Representations: Hidden instability in VLMs
Feb 06, 2026The robustness of Vision Language Models (VLMs) is commonly assessed through output-level invariance, implicitly assuming that stable predictions reflect stable multimodal processing. In this work, we argue that this assumption is insufficient. We introduce a representation-aware and frequency-aware evaluation framework that measures internal embedding drift, spectral sensitivity, and structural smoothness (spatial consistency of vision tokens), alongside standard label-based metrics. Applying this framework to modern VLMs across the SEEDBench, MMMU, and POPE datasets reveals three distinct failure modes. First, models frequently preserve predicted answers while undergoing substantial internal representation drift; for perturbations such as text overlays, this drift approaches the magnitude of inter-image variability, indicating that representations move to regions typically occupied by unrelated inputs despite unchanged outputs. Second, robustness does not improve with scale; larger models achieve higher accuracy but exhibit equal or greater sensitivity, consistent with sharper yet more fragile decision boundaries. Third, we find that perturbations affect tasks differently: they harm reasoning when they disrupt how models combine coarse and fine visual cues, but on the hallucination benchmarks, they can reduce false positives by making models generate more conservative answers.
Early-Exit Graph Neural Networks
May 23, 2025Early-exit mechanisms allow deep neural networks to halt inference as soon as classification confidence is high enough, adaptively trading depth for confidence, and thereby cutting latency and energy on easy inputs while retaining full-depth accuracy for harder ones. Similarly, adding early exit mechanisms to Graph Neural Networks (GNNs), the go-to models for graph-structured data, allows for dynamic trading depth for confidence on simple graphs while maintaining full-depth accuracy on harder and more complex graphs to capture intricate relationships. Although early exits have proven effective across various deep learning domains, their potential within GNNs in scenarios that require deep architectures while resisting over-smoothing and over-squashing remains largely unexplored. We unlock that potential by first introducing Symmetric-Anti-Symmetric Graph Neural Networks (SAS-GNN), whose symmetry-based inductive biases mitigate these issues and yield stable intermediate representations that can be useful to allow early exiting in GNNs. Building on this backbone, we present Early-Exit Graph Neural Networks (EEGNNs), which append confidence-aware exit heads that allow on-the-fly termination of propagation based on each node or the entire graph. Experiments show that EEGNNs preserve robust performance as depth grows and deliver competitive accuracy on heterophilic and long-range benchmarks, matching attention-based and asynchronous message-passing models while substantially reducing computation and latency. We plan to release the code to reproduce our experiments.
MASS: MoErging through Adaptive Subspace Selection
Apr 06, 2025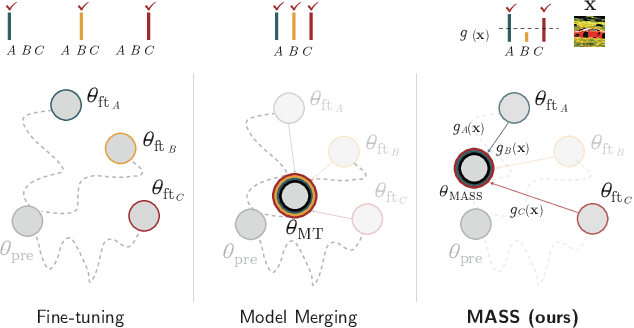
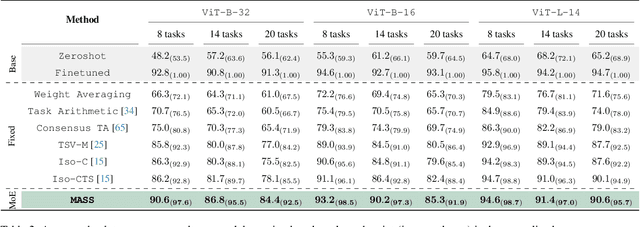
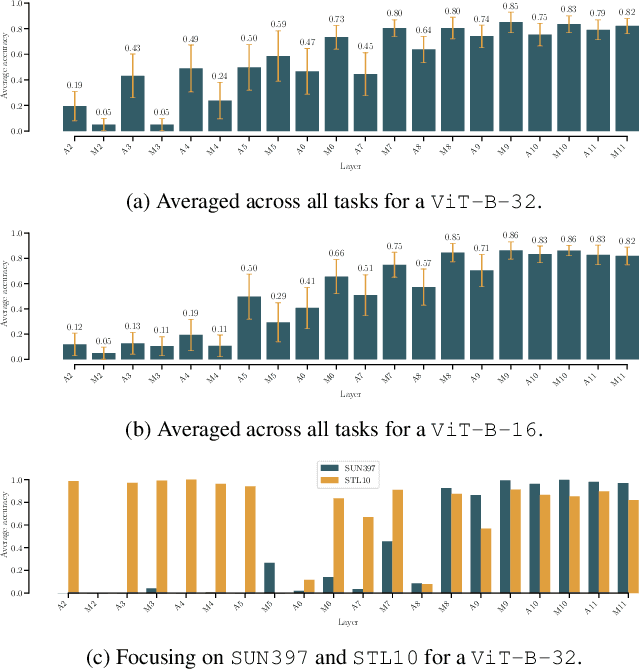
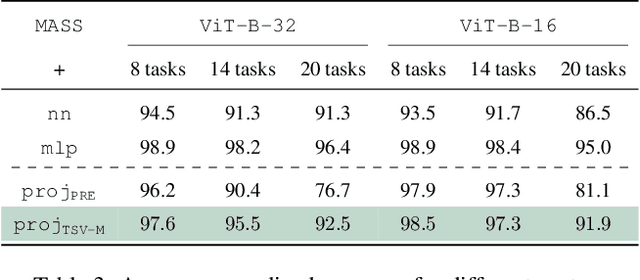
Model merging has recently emerged as a lightweight alternative to ensembling, combining multiple fine-tuned models into a single set of parameters with no additional training overhead. Yet, existing merging methods fall short of matching the full accuracy of separately fine-tuned endpoints. We present MASS (MoErging through Adaptive Subspace Selection), a new approach that closes this gap by unifying multiple fine-tuned models while retaining near state-of-the-art performance across tasks. Building on the low-rank decomposition of per-task updates, MASS stores only the most salient singular components for each task and merges them into a shared model. At inference time, a non-parametric, data-free router identifies which subspace (or combination thereof) best explains an input's intermediate features and activates the corresponding task-specific block. This procedure is fully training-free and introduces only a two-pass inference overhead plus a ~2 storage factor compared to a single pretrained model, irrespective of the number of tasks. We evaluate MASS on CLIP-based image classification using ViT-B-16, ViT-B-32 and ViT-L-14 for benchmarks of 8, 14 and 20 tasks respectively, establishing a new state-of-the-art. Most notably, MASS recovers up to ~98% of the average accuracy of individual fine-tuned models, making it a practical alternative to ensembling at a fraction of the storage cost.
The Majority Vote Paradigm Shift: When Popular Meets Optimal
Feb 19, 2025



Reliably labelling data typically requires annotations from multiple human workers. However, humans are far from being perfect. Hence, it is a common practice to aggregate labels gathered from multiple annotators to make a more confident estimate of the true label. Among many aggregation methods, the simple and well known Majority Vote (MV) selects the class label polling the highest number of votes. However, despite its importance, the optimality of MV's label aggregation has not been extensively studied. We address this gap in our work by characterising the conditions under which MV achieves the theoretically optimal lower bound on label estimation error. Our results capture the tolerable limits on annotation noise under which MV can optimally recover labels for a given class distribution. This certificate of optimality provides a more principled approach to model selection for label aggregation as an alternative to otherwise inefficient practices that sometimes include higher experts, gold labels, etc., that are all marred by the same human uncertainty despite huge time and monetary costs. Experiments on both synthetic and real world data corroborate our theoretical findings.
Robustness of Graph Classification: failure modes, causes, and noise-resistant loss in Graph Neural Networks
Dec 11, 2024Graph Neural Networks (GNNs) are powerful at solving graph classification tasks, yet applied problems often contain noisy labels. In this work, we study GNN robustness to label noise, demonstrate GNN failure modes when models struggle to generalise on low-order graphs, low label coverage, or when a model is over-parameterized. We establish both empirical and theoretical links between GNN robustness and the reduction of the total Dirichlet Energy of learned node representations, which encapsulates the hypothesized GNN smoothness inductive bias. Finally, we introduce two training strategies to enhance GNN robustness: (1) by incorporating a novel inductive bias in the weight matrices through the removal of negative eigenvalues, connected to Dirichlet Energy minimization; (2) by extending to GNNs a loss penalty that promotes learned smoothness. Importantly, neither approach negatively impacts performance in noise-free settings, supporting our hypothesis that the source of GNNs robustness is their smoothness inductive bias.
Task Singular Vectors: Reducing Task Interference in Model Merging
Nov 26, 2024



Task Arithmetic has emerged as a simple yet effective method to merge models without additional training. However, by treating entire networks as flat parameter vectors, it overlooks key structural information and is susceptible to task interference. In this paper, we study task vectors at the layer level, focusing on task layer matrices and their singular value decomposition. In particular, we concentrate on the resulting singular vectors, which we refer to as Task Singular Vectors (TSV). Recognizing that layer task matrices are often low-rank, we propose TSV-Compress (TSV-C), a simple procedure that compresses them to 10% of their original size while retaining 99% of accuracy. We further leverage this low-rank space to define a new measure of task interference based on the interaction of singular vectors from different tasks. Building on these findings, we introduce TSV-Merge (TSV-M), a novel model merging approach that combines compression with interference reduction, significantly outperforming existing methods.
ATM: Improving Model Merging by Alternating Tuning and Merging
Nov 05, 2024


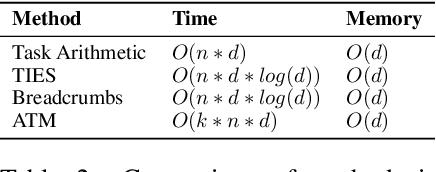
Model merging has recently emerged as a cost-efficient paradigm for multi-task learning. Among current approaches, task arithmetic stands out for its simplicity and effectiveness. In this paper, we motivate the effectiveness of task vectors by linking them to multi-task gradients. We show that in a single-epoch scenario, task vectors are mathematically equivalent to the gradients obtained via gradient descent in a multi-task setting, and still approximate these gradients in subsequent epochs. Furthermore, we show that task vectors perform optimally when equality is maintained, and their effectiveness is largely driven by the first epoch's gradient. Building on this insight, we propose viewing model merging as a single step in an iterative process that Alternates between Tuning and Merging (ATM). This method acts as a bridge between model merging and multi-task gradient descent, achieving state-of-the-art results with the same data and computational requirements. We extensively evaluate ATM across diverse settings, achieving up to 20% higher accuracy in computer vision and NLP tasks, compared to the best baselines.Finally, we provide both empirical and theoretical support for its effectiveness, demonstrating increased orthogonality between task vectors and proving that ATM minimizes an upper bound on the loss obtained by jointly finetuning all tasks.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024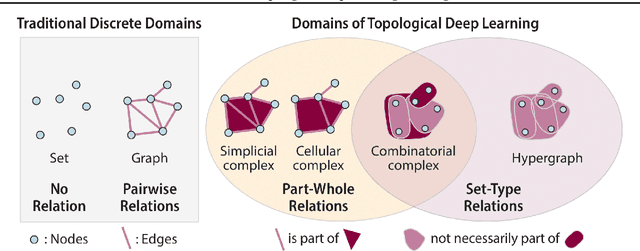
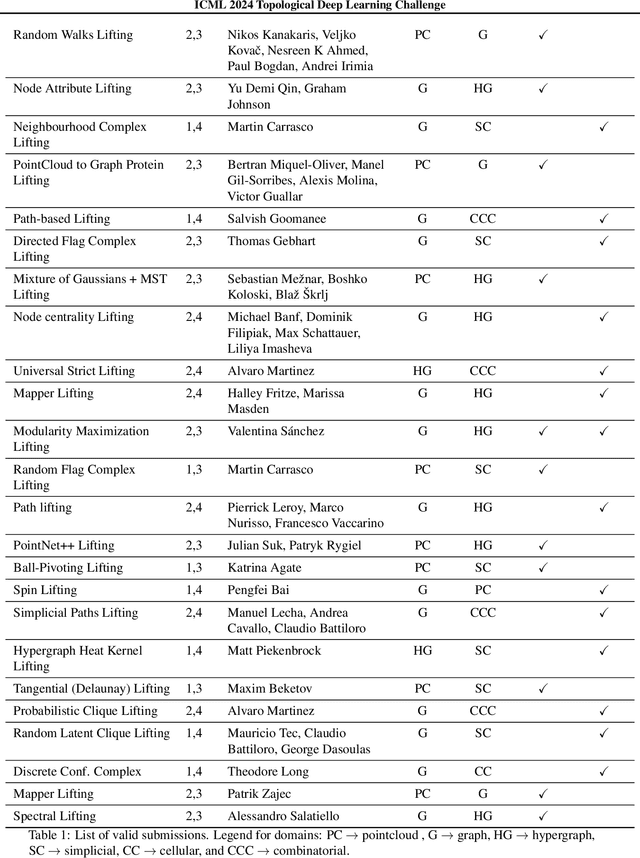
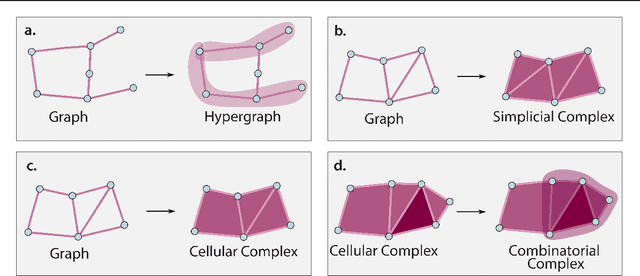
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.