 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Way Representation Alignment
Feb 05, 2026The Platonic Representation Hypothesis suggests that independently trained neural networks converge to increasingly similar latent spaces. However, current strategies for mapping these representations are inherently pairwise, scaling quadratically with the number of models and failing to yield a consistent global reference. In this paper, we study the alignment of $M \ge 3$ models. We first adapt Generalized Procrustes Analysis (GPA) to construct a shared orthogonal universe that preserves the internal geometry essential for tasks like model stitching. We then show that strict isometric alignment is suboptimal for retrieval, where agreement-maximizing methods like Canonical Correlation Analysis (CCA) typically prevail. To bridge this gap, we finally propose Geometry-Corrected Procrustes Alignment (GCPA), which establishes a robust GPA-based universe followed by a post-hoc correction for directional mismatch. Extensive experiments demonstrate that GCPA consistently improves any-to-any retrieval while retaining a practical shared reference space.
Demystifying Mergeability: Interpretable Properties to Predict Model Merging Success
Jan 29, 2026Model merging combines knowledge from separately fine-tuned models, yet success factors remain poorly understood. While recent work treats mergeability as an intrinsic property, we show with an architecture-agnostic framework that it fundamentally depends on both the merging method and the partner tasks. Using linear optimization over a set of interpretable pairwise metrics (e.g., gradient L2 distance), we uncover properties correlating with post-merge performance across four merging methods. We find substantial variation in success drivers (46.7% metric overlap; 55.3% sign agreement), revealing method-specific "fingerprints". Crucially, however, subspace overlap and gradient alignment metrics consistently emerge as foundational, method-agnostic prerequisites for compatibility. These findings provide a diagnostic foundation for understanding mergeability and motivate future fine-tuning strategies that explicitly encourage these properties.
EuleroDec: A Complex-Valued RVQ-VAE for Efficient and Robust Audio Coding
Jan 24, 2026Audio codecs power discrete music generative modelling, music streaming, and immersive media by shrinking PCM audio to bandwidth-friendly bitrates. Recent works have gravitated towards processing in the spectral domain; however, spectrogram domains typically struggle with phase modeling, which is naturally complex-valued. Most frequency-domain neural codecs either disregard phase information or encode it as two separate real-valued channels, limiting spatial fidelity. This entails the need to introduce adversarial discriminators at the expense of convergence speed and training stability to compensate for the inadequate representation power of the audio signal. In this work we introduce an end-to-end complex-valued RVQ-VAE audio codec that preserves magnitude-phase coupling across the entire analysis-quantization-synthesis pipeline and removes adversarial discriminators and diffusion post-filters. Without GANs or diffusion, we match or surpass much longer-trained baselines in-domain and reach SOTA out-of-domain performance on phase coherence and waveform fidelity. Compared to standard baselines that train for hundreds of thousands of steps, our model, which reduces the training budget by an order of magnitude, is markedly more compute-efficient while preserving high perceptual quality.
Membership and Dataset Inference Attacks on Large Audio Generative Models
Dec 10, 2025Generative audio models, based on diffusion and autoregressive architectures, have advanced rapidly in both quality and expressiveness. This progress, however, raises pressing copyright concerns, as such models are often trained on vast corpora of artistic and commercial works. A central question is whether one can reliably verify if an artist's material was included in training, thereby providing a means for copyright holders to protect their content. In this work, we investigate the feasibility of such verification through membership inference attacks (MIA) on open-source generative audio models, which attempt to determine whether a specific audio sample was part of the training set. Our empirical results show that membership inference alone is of limited effectiveness at scale, as the per-sample membership signal is weak for models trained on large and diverse datasets. However, artists and media owners typically hold collections of works rather than isolated samples. Building on prior work in text and vision domains, in this work we focus on dataset inference (DI), which aggregates diverse membership evidence across multiple samples. We find that DI is successful in the audio domain, offering a more practical mechanism for assessing whether an artist's works contributed to model training. Our results suggest DI as a promising direction for copyright protection and dataset accountability in the era of large audio generative models.
Model Merging Improves Zero-Shot Generalization in Bioacoustic Foundation Models
Nov 19, 2025Foundation models capable of generalizing across species and tasks represent a promising new frontier in bioacoustics, with NatureLM being one of the most prominent examples. While its domain-specific fine-tuning yields strong performance on bioacoustic benchmarks, we observe that it also introduces trade-offs in instruction-following flexibility. For instance, NatureLM achieves high accuracy when prompted for either the common or scientific name individually, but its accuracy drops significantly when both are requested in a single prompt. We address this by applying a simple model merging strategy that interpolates NatureLM with its base language model, recovering instruction-following capabilities with minimal loss of domain expertise. Finally, we show that the merged model exhibits markedly stronger zero-shot generalization, achieving over a 200% relative improvement and setting a new state-of-the-art in closed-set zero-shot classification of unseen species.
Video Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
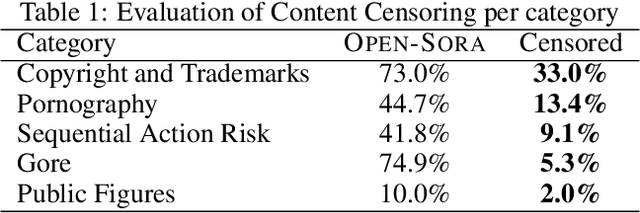
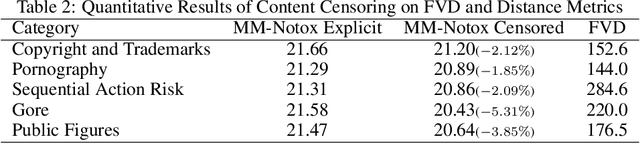

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
Implicit Inversion turns CLIP into a Decoder
May 29, 2025CLIP is a discriminative model trained to align images and text in a shared embedding space. Due to its multimodal structure, it serves as the backbone of many generative pipelines, where a decoder is trained to map from the shared space back to images. In this work, we show that image synthesis is nevertheless possible using CLIP alone -- without any decoder, training, or fine-tuning. Our approach optimizes a frequency-aware implicit neural representation that encourages coarse-to-fine generation by stratifying frequencies across network layers. To stabilize this inverse mapping, we introduce adversarially robust initialization, a lightweight Orthogonal Procrustes projection to align local text and image embeddings, and a blending loss that anchors outputs to natural image statistics. Without altering CLIP's weights, this framework unlocks capabilities such as text-to-image generation, style transfer, and image reconstruction. These findings suggest that discriminative models may hold untapped generative potential, hidden in plain sight.
Navigating the Latent Space Dynamics of Neural Models
May 28, 2025Neural networks transform high-dimensional data into compact, structured representations, often modeled as elements of a lower dimensional latent space. In this paper, we present an alternative interpretation of neural models as dynamical systems acting on the latent manifold. Specifically, we show that autoencoder models implicitly define a latent vector field on the manifold, derived by iteratively applying the encoding-decoding map, without any additional training. We observe that standard training procedures introduce inductive biases that lead to the emergence of attractor points within this vector field. Drawing on this insight, we propose to leverage the vector field as a representation for the network, providing a novel tool to analyze the properties of the model and the data. This representation enables to: (i) analyze the generalization and memorization regimes of neural models, even throughout training; (ii) extract prior knowledge encoded in the network's parameters from the attractors, without requiring any input data; (iii) identify out-of-distribution samples from their trajectories in the vector field. We further validate our approach on vision foundation models, showcasing the applicability and effectiveness of our method in real-world scenarios.
Update Your Transformer to the Latest Release: Re-Basin of Task Vectors
May 28, 2025Foundation models serve as the backbone for numerous specialized models developed through fine-tuning. However, when the underlying pretrained model is updated or retrained (e.g., on larger and more curated datasets), the fine-tuned model becomes obsolete, losing its utility and requiring retraining. This raises the question: is it possible to transfer fine-tuning to a new release of the model? In this work, we investigate how to transfer fine-tuning to a new checkpoint without having to re-train, in a data-free manner. To do so, we draw principles from model re-basin and provide a recipe based on weight permutations to re-base the modifications made to the original base model, often called task vector. In particular, our approach tailors model re-basin for Transformer models, taking into account the challenges of residual connections and multi-head attention layers. Specifically, we propose a two-level method rooted in spectral theory, initially permuting the attention heads and subsequently adjusting parameters within select pairs of heads. Through extensive experiments on visual and textual tasks, we achieve the seamless transfer of fine-tuned knowledge to new pre-trained backbones without relying on a single training step or datapoint. Code is available at https://github.com/aimagelab/TransFusion.
Mergenetic: a Simple Evolutionary Model Merging Library
May 16, 2025Model merging allows combining the capabilities of existing models into a new one - post hoc, without additional training. This has made it increasingly popular thanks to its low cost and the availability of libraries that support merging on consumer GPUs. Recent work shows that pairing merging with evolutionary algorithms can boost performance, but no framework currently supports flexible experimentation with such strategies in language models. We introduce Mergenetic, an open-source library for evolutionary model merging. Mergenetic enables easy composition of merging methods and evolutionary algorithms while incorporating lightweight fitness estimators to reduce evaluation costs. We describe its design and demonstrate that Mergenetic produces competitive results across tasks and languages using modest hardware.