 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping Plato's Cave: Towards the Alignment of 3D and Text Latent Spaces
Mar 07, 2025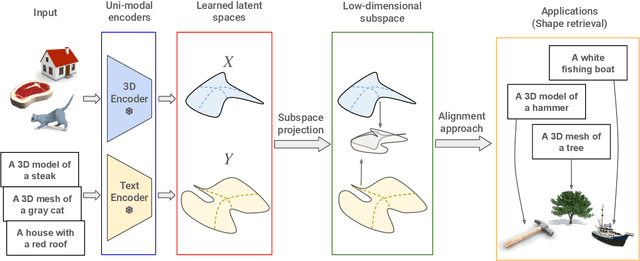
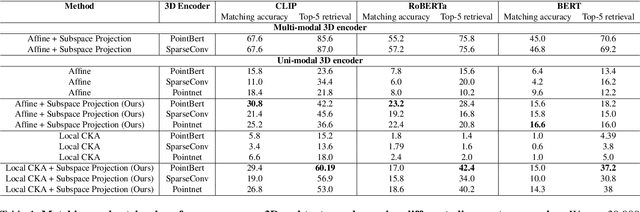
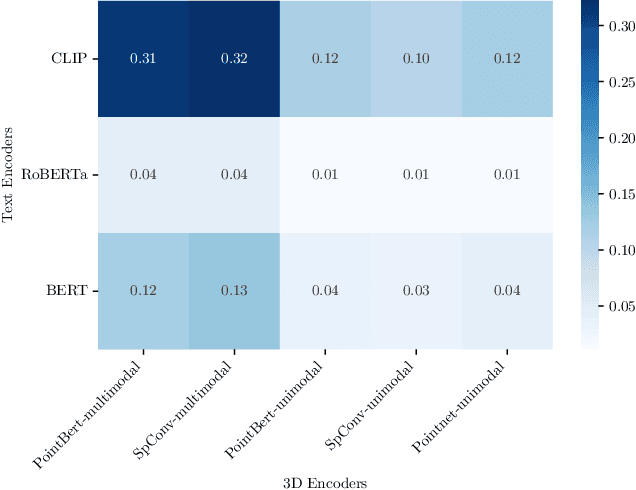
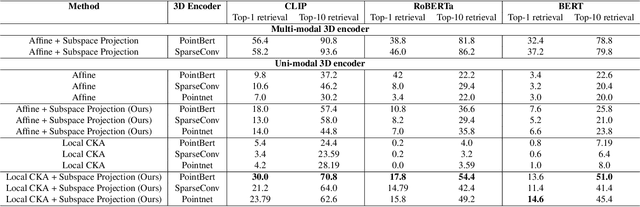
Recent works have shown that, when trained at scale, uni-modal 2D vision and text encoders converge to learned features that share remarkable structural properties, despite arising from different representations. However, the role of 3D encoders with respect to other modalities remains unexplored. Furthermore, existing 3D foundation models that leverage large datasets are typically trained with explicit alignment objectives with respect to frozen encoders from other representations. In this work, we investigate the possibility of a posteriori alignment of representations obtained from uni-modal 3D encoders compared to text-based feature spaces. We show that naive post-training feature alignment of uni-modal text and 3D encoders results in limited performance. We then focus on extracting subspaces of the corresponding feature spaces and discover that by projecting learned representations onto well-chosen lower-dimensional subspaces the quality of alignment becomes significantly higher, leading to improved accuracy on matching and retrieval tasks. Our analysis further sheds light on the nature of these shared subspaces, which roughly separate between semantic and geometric data representations. Overall, ours is the first work that helps to establish a baseline for post-training alignment of 3D uni-modal and text feature spaces, and helps to highlight both the shared and unique properties of 3D data compared to other representations.
FourieRF: Few-Shot NeRFs via Progressive Fourier Frequency Control
Feb 03, 2025In this work, we introduce FourieRF, a novel approach for achieving fast and high-quality reconstruction in the few-shot setting. Our method effectively parameterizes features through an explicit curriculum training procedure, incrementally increasing scene complexity during optimization. Experimental results show that the prior induced by our approach is both robust and adaptable across a wide variety of scenes, establishing FourieRF as a strong and versatile baseline for the few-shot rendering problem. While our approach significantly reduces artifacts, it may still lead to reconstruction errors in severely under-constrained scenarios, particularly where view occlusion leaves parts of the shape uncovered. In the future, our method could be enhanced by integrating foundation models to complete missing parts using large data-driven priors.
ZeroKey: Point-Level Reasoning and Zero-Shot 3D Keypoint Detection from Large Language Models
Dec 09, 2024



We propose a novel zero-shot approach for keypoint detection on 3D shapes. Point-level reasoning on visual data is challenging as it requires precise localization capability, posing problems even for powerful models like DINO or CLIP. Traditional methods for 3D keypoint detection rely heavily on annotated 3D datasets and extensive supervised training, limiting their scalability and applicability to new categories or domains. In contrast, our method utilizes the rich knowledge embedded within Multi-Modal Large Language Models (MLLMs). Specifically, we demonstrate, for the first time, that pixel-level annotations used to train recent MLLMs can be exploited for both extracting and naming salient keypoints on 3D models without any ground truth labels or supervision. Experimental evaluations demonstrate that our approach achieves competitive performance on standard benchmarks compared to supervised methods, despite not requiring any 3D keypoint annotations during training. Our results highlight the potential of integrating language models for localized 3D shape understanding. This work opens new avenues for cross-modal learning and underscores the effectiveness of MLLMs in contributing to 3D computer vision challenges.
RRM: Relightable assets using Radiance guided Material extraction
Jul 08, 2024Synthesizing NeRFs under arbitrary lighting has become a seminal problem in the last few years. Recent efforts tackle the problem via the extraction of physically-based parameters that can then be rendered under arbitrary lighting, but they are limited in the range of scenes they can handle, usually mishandling glossy scenes. We propose RRM, a method that can extract the materials, geometry, and environment lighting of a scene even in the presence of highly reflective objects. Our method consists of a physically-aware radiance field representation that informs physically-based parameters, and an expressive environment light structure based on a Laplacian Pyramid. We demonstrate that our contributions outperform the state-of-the-art on parameter retrieval tasks, leading to high-fidelity relighting and novel view synthesis on surfacic scenes.
Proper Laplacian Representation Learning
Oct 16, 2023



The ability to learn good representations of states is essential for solving large reinforcement learning problems, where exploration, generalization, and transfer are particularly challenging. The Laplacian representation is a promising approach to address these problems by inducing intrinsic rewards for temporally-extended action discovery and reward shaping, and informative state encoding. To obtain the Laplacian representation one needs to compute the eigensystem of the graph Laplacian, which is often approximated through optimization objectives compatible with deep learning approaches. These approximations, however, depend on hyperparameters that are impossible to tune efficiently, converge to arbitrary rotations of the desired eigenvectors, and are unable to accurately recover the corresponding eigenvalues. In this paper we introduce a theoretically sound objective and corresponding optimization algorithm for approximating the Laplacian representation. Our approach naturally recovers both the true eigenvectors and eigenvalues while eliminating the hyperparameter dependence of previous approximations. We provide theoretical guarantees for our method and we show that those results translate empirically into robust learning across multiple environments.
Concept Learning in Deep Reinforcement Learning
May 19, 2020


Deep reinforcement learning techniques have shown to be a promising path to solve very complex tasks that once were thought to be out of the realm of machines. However, while humans and animals learn incrementally during their lifetimes and exploit their experience to solve new tasks, standard deep learning methods specialize to solve only one task at a time and whatever information they acquire is hardly reusable in new situations. Given that any artificial agent would need such a generalization ability to deal with the complexities of the world, it is critical to understand what mechanisms give rise to this ability. We argue that one of the mechanisms humans rely on is the use of discrete conceptual representations to encode their sensory inputs. These representations group similar inputs in such a way that combined they provide a level of abstraction that is transverse to a wide variety of tasks, filtering out irrelevant information for their solution. Here, we show that it is possible to learn such concept-like representations by self-supervision, following an information-bottleneck approach, and that these representations accelerate the transference of skills by providing a prior that guides the policy optimization process. Our method is able to learn useful concepts in locomotive tasks that significantly reduce the number of optimization steps required, opening a new path to endow artificial agents with generalization abilities.