 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearID: Identity Representation Learning via Near-identity Distractors
Apr 02, 2026When evaluating identity-focused tasks such as personalized generation and image editing, existing vision encoders entangle object identity with background context, leading to unreliable representations and metrics. We introduce the first principled framework to address this vulnerability using Near-identity (NearID) distractors, where semantically similar but distinct instances are placed on the exact same background as a reference image, eliminating contextual shortcuts and isolating identity as the sole discriminative signal. Based on this principle, we present the NearID dataset (19K identities, 316K matched-context distractors) together with a strict margin-based evaluation protocol. Under this setting, pre-trained encoders perform poorly, achieving Sample Success Rates (SSR), a strict margin-based identity discrimination metric, as low as 30.7% and often ranking distractors above true cross-view matches. We address this by learning identity-aware representations on a frozen backbone using a two-tier contrastive objective enforcing the hierarchy: same identity > NearID distractor > random negative. This improves SSR to 99.2%, enhances part-level discrimination by 28.0%, and yields stronger alignment with human judgments on DreamBench++, a human-aligned benchmark for personalization. Project page: https://gorluxor.github.io/NearID/
Out-of-Distribution Segmentation via Wasserstein-Based Evidential Uncertainty
Dec 12, 2025Deep neural networks achieve superior performance in semantic segmentation, but are limited to a predefined set of classes, which leads to failures when they encounter unknown objects in open-world scenarios. Recognizing and segmenting these out-of-distribution (OOD) objects is crucial for safety-critical applications such as automated driving. In this work, we present an evidence segmentation framework using a Wasserstein loss, which captures distributional distances while respecting the probability simplex geometry. Combined with Kullback-Leibler regularization and Dice structural consistency terms, our approach leads to improved OOD segmentation performance compared to uncertainty-based approaches.
Mind-the-Glitch: Visual Correspondence for Detecting Inconsistencies in Subject-Driven Generation
Sep 26, 2025We propose a novel approach for disentangling visual and semantic features from the backbones of pre-trained diffusion models, enabling visual correspondence in a manner analogous to the well-established semantic correspondence. While diffusion model backbones are known to encode semantically rich features, they must also contain visual features to support their image synthesis capabilities. However, isolating these visual features is challenging due to the absence of annotated datasets. To address this, we introduce an automated pipeline that constructs image pairs with annotated semantic and visual correspondences based on existing subject-driven image generation datasets, and design a contrastive architecture to separate the two feature types. Leveraging the disentangled representations, we propose a new metric, Visual Semantic Matching (VSM), that quantifies visual inconsistencies in subject-driven image generation. Empirical results show that our approach outperforms global feature-based metrics such as CLIP, DINO, and vision--language models in quantifying visual inconsistencies while also enabling spatial localization of inconsistent regions. To our knowledge, this is the first method that supports both quantification and localization of inconsistencies in subject-driven generation, offering a valuable tool for advancing this task. Project Page:https://abdo-eldesokey.github.io/mind-the-glitch/
PlanQA: A Benchmark for Spatial Reasoning in LLMs using Structured Representations
Jul 10, 2025We introduce PlanQA, a diagnostic benchmark for evaluating geometric and spatial reasoning in large-language models (LLMs). PlanQA is grounded in structured representations of indoor scenes, such as kitchens, living rooms, and bedrooms, encoded in a symbolic format (e.g., JSON, XML layouts). The benchmark includes diverse question types that test not only metric and topological reasoning (e.g., distance, visibility, shortest paths) but also interior design constraints such as affordance, clearance, balance, and usability. Our results across a variety of frontier open-source and commercial LLMs show that while models may succeed in shallow queries, they often fail to simulate physical constraints, preserve spatial coherence, or generalize under layout perturbation. PlanQA uncovers a clear blind spot in today's LLMs: they do not consistently reason about real-world layouts. We hope that this benchmark inspires new work on language models that can accurately infer and manipulate spatial and geometric properties in practical settings.
PlaceIt3D: Language-Guided Object Placement in Real 3D Scenes
May 08, 2025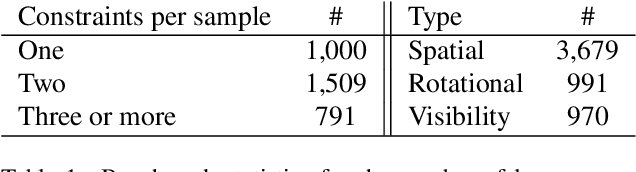
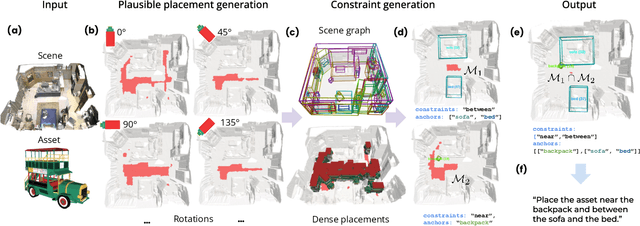
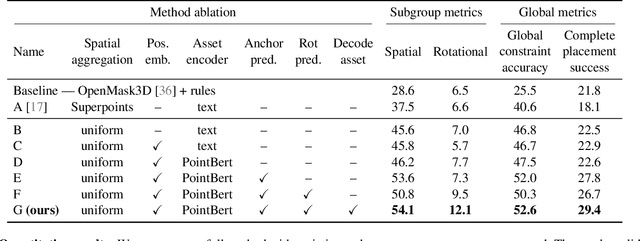
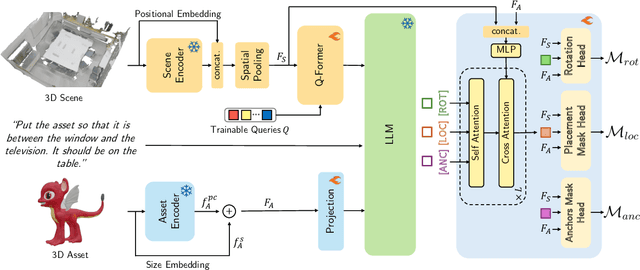
We introduce the novel task of Language-Guided Object Placement in Real 3D Scenes. Our model is given a 3D scene's point cloud, a 3D asset, and a textual prompt broadly describing where the 3D asset should be placed. The task here is to find a valid placement for the 3D asset that respects the prompt. Compared with other language-guided localization tasks in 3D scenes such as grounding, this task has specific challenges: it is ambiguous because it has multiple valid solutions, and it requires reasoning about 3D geometric relationships and free space. We inaugurate this task by proposing a new benchmark and evaluation protocol. We also introduce a new dataset for training 3D LLMs on this task, as well as the first method to serve as a non-trivial baseline. We believe that this challenging task and our new benchmark could become part of the suite of benchmarks used to evaluate and compare generalist 3D LLM models.
EditCLIP: Representation Learning for Image Editing
Mar 26, 2025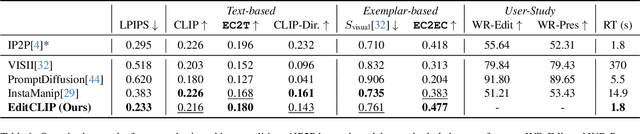
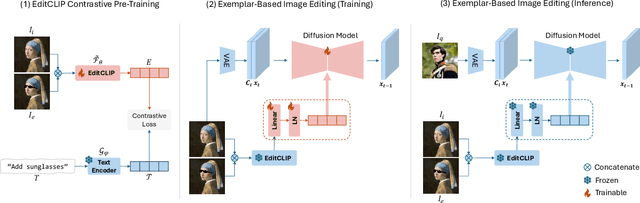

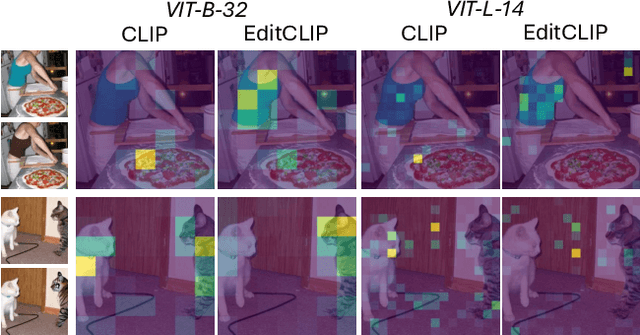
We introduce EditCLIP, a novel representation-learning approach for image editing. Our method learns a unified representation of edits by jointly encoding an input image and its edited counterpart, effectively capturing their transformation. To evaluate its effectiveness, we employ EditCLIP to solve two tasks: exemplar-based image editing and automated edit evaluation. In exemplar-based image editing, we replace text-based instructions in InstructPix2Pix with EditCLIP embeddings computed from a reference exemplar image pair. Experiments demonstrate that our approach outperforms state-of-the-art methods while being more efficient and versatile. For automated evaluation, EditCLIP assesses image edits by measuring the similarity between the EditCLIP embedding of a given image pair and either a textual editing instruction or the EditCLIP embedding of another reference image pair. Experiments show that EditCLIP aligns more closely with human judgments than existing CLIP-based metrics, providing a reliable measure of edit quality and structural preservation.
PartEdit: Fine-Grained Image Editing using Pre-Trained Diffusion Models
Feb 06, 2025



We present the first text-based image editing approach for object parts based on pre-trained diffusion models. Diffusion-based image editing approaches capitalized on the deep understanding of diffusion models of image semantics to perform a variety of edits. However, existing diffusion models lack sufficient understanding of many object parts, hindering fine-grained edits requested by users. To address this, we propose to expand the knowledge of pre-trained diffusion models to allow them to understand various object parts, enabling them to perform fine-grained edits. We achieve this by learning special textual tokens that correspond to different object parts through an efficient token optimization process. These tokens are optimized to produce reliable localization masks at each inference step to localize the editing region. Leveraging these masks, we design feature-blending and adaptive thresholding strategies to execute the edits seamlessly. To evaluate our approach, we establish a benchmark and an evaluation protocol for part editing. Experiments show that our approach outperforms existing editing methods on all metrics and is preferred by users 77-90% of the time in conducted user studies.
ZeroKey: Point-Level Reasoning and Zero-Shot 3D Keypoint Detection from Large Language Models
Dec 09, 2024



We propose a novel zero-shot approach for keypoint detection on 3D shapes. Point-level reasoning on visual data is challenging as it requires precise localization capability, posing problems even for powerful models like DINO or CLIP. Traditional methods for 3D keypoint detection rely heavily on annotated 3D datasets and extensive supervised training, limiting their scalability and applicability to new categories or domains. In contrast, our method utilizes the rich knowledge embedded within Multi-Modal Large Language Models (MLLMs). Specifically, we demonstrate, for the first time, that pixel-level annotations used to train recent MLLMs can be exploited for both extracting and naming salient keypoints on 3D models without any ground truth labels or supervision. Experimental evaluations demonstrate that our approach achieves competitive performance on standard benchmarks compared to supervised methods, despite not requiring any 3D keypoint annotations during training. Our results highlight the potential of integrating language models for localized 3D shape understanding. This work opens new avenues for cross-modal learning and underscores the effectiveness of MLLMs in contributing to 3D computer vision challenges.
Build-A-Scene: Interactive 3D Layout Control for Diffusion-Based Image Generation
Aug 27, 2024We propose a diffusion-based approach for Text-to-Image (T2I) generation with interactive 3D layout control. Layout control has been widely studied to alleviate the shortcomings of T2I diffusion models in understanding objects' placement and relationships from text descriptions. Nevertheless, existing approaches for layout control are limited to 2D layouts, require the user to provide a static layout beforehand, and fail to preserve generated images under layout changes. This makes these approaches unsuitable for applications that require 3D object-wise control and iterative refinements, e.g., interior design and complex scene generation. To this end, we leverage the recent advancements in depth-conditioned T2I models and propose a novel approach for interactive 3D layout control. We replace the traditional 2D boxes used in layout control with 3D boxes. Furthermore, we revamp the T2I task as a multi-stage generation process, where at each stage, the user can insert, change, and move an object in 3D while preserving objects from earlier stages. We achieve this through our proposed Dynamic Self-Attention (DSA) module and the consistent 3D object translation strategy. Experiments show that our approach can generate complicated scenes based on 3D layouts, boosting the object generation success rate over the standard depth-conditioned T2I methods by 2x. Moreover, it outperforms other methods in comparison in preserving objects under layout changes. Project Page: \url{https://abdo-eldesokey.github.io/build-a-scene/}
Zero-Shot Video Semantic Segmentation based on Pre-Trained Diffusion Models
May 27, 2024We introduce the first zero-shot approach for Video Semantic Segmentation (VSS) based on pre-trained diffusion models. A growing research direction attempts to employ diffusion models to perform downstream vision tasks by exploiting their deep understanding of image semantics. Yet, the majority of these approaches have focused on image-related tasks like semantic correspondence and segmentation, with less emphasis on video tasks such as VSS. Ideally, diffusion-based image semantic segmentation approaches can be applied to videos in a frame-by-frame manner. However, we find their performance on videos to be subpar due to the absence of any modeling of temporal information inherent in the video data. To this end, we tackle this problem and introduce a framework tailored for VSS based on pre-trained image and video diffusion models. We propose building a scene context model based on the diffusion features, where the model is autoregressively updated to adapt to scene changes. This context model predicts per-frame coarse segmentation maps that are temporally consistent. To refine these maps further, we propose a correspondence-based refinement strategy that aggregates predictions temporally, resulting in more confident predictions. Finally, we introduce a masked modulation approach to upsample the coarse maps to the full resolution at a high quality. Experiments show that our proposed approach outperforms existing zero-shot image semantic segmentation approaches significantly on various VSS benchmarks without any training or fine-tuning. Moreover, it rivals supervised VSS approaches on the VSPW dataset despite not being explicitly trained for VSS.