 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitect-Ant: Editable Automatic Furnishing of Architectural Floor Plans
Jun 09, 2026Furnished floor plans are fundamental to real estate visualization, interior design, and architectural workflows. However, progress in automatic furniture arrangement has been limited by the lack of real, professionally designed floor-plan datasets with object-level furniture annotations. To address this gap, we introduce AntPlan-270, a curated dataset of 270 architectural floor plans with per-room furniture bounding box annotations across ten residential room categories. Building on this dataset, we present Architect-Ant, an editable automatic furnishing framework powered by a fine-tuned vision-language model. Furniture layouts are represented using a compact, coordinate-based domain-specific language (DSL) that encodes object categories and placements relative to the room geometry. To improve spatial reasoning, we generate procedural reasoning traces that capture architectural constraints such as wall alignment, door and window clearance, circulation, fixture compatibility, and room-specific furniture inventories, and use them to supervise fine-tuning of the model. We then apply preference optimization over candidate object placements to further refine layout quality. The generated DSL can be rasterized into semantic masks and used to condition a Flux-based LoRA renderer, producing realistic blueprint-style furnished floor-plan images while preserving the editable symbolic layout. Experiments on layout furnishing show that Architect-Ant produces geometrically valid and functionally plausible layouts, and suggest a scalable path for furnishing larger structure-only floor-plan datasets.
OmniAcc: Personalized Accessibility Assistant Using Generative AI
Sep 08, 2025
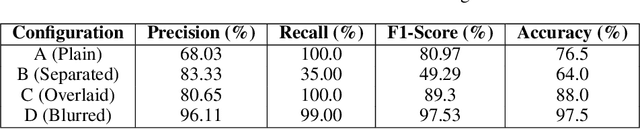
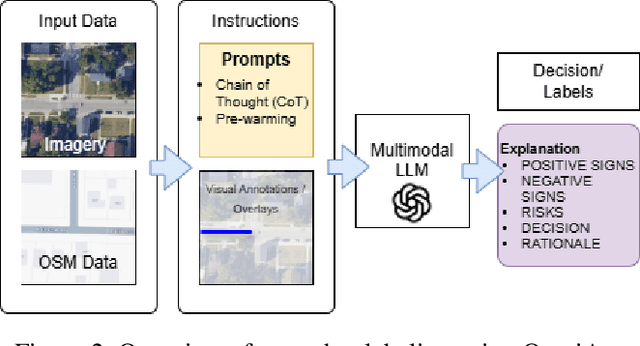

Individuals with ambulatory disabilities often encounter significant barriers when navigating urban environments due to the lack of accessible information and tools. This paper presents OmniAcc, an AI-powered interactive navigation system that utilizes GPT-4, satellite imagery, and OpenStreetMap data to identify, classify, and map wheelchair-accessible features such as ramps and crosswalks in the built environment. OmniAcc offers personalized route planning, real-time hands-free navigation, and instant query responses regarding physical accessibility. By using zero-shot learning and customized prompts, the system ensures precise detection of accessibility features, while supporting validation through structured workflows. This paper introduces OmniAcc and explores its potential to assist urban planners and mobility-aid users, demonstrated through a case study on crosswalk detection. With a crosswalk detection accuracy of 97.5%, OmniAcc highlights the transformative potential of AI in improving navigation and fostering more inclusive urban spaces.
PlanQA: A Benchmark for Spatial Reasoning in LLMs using Structured Representations
Jul 10, 2025We introduce PlanQA, a diagnostic benchmark for evaluating geometric and spatial reasoning in large-language models (LLMs). PlanQA is grounded in structured representations of indoor scenes, such as kitchens, living rooms, and bedrooms, encoded in a symbolic format (e.g., JSON, XML layouts). The benchmark includes diverse question types that test not only metric and topological reasoning (e.g., distance, visibility, shortest paths) but also interior design constraints such as affordance, clearance, balance, and usability. Our results across a variety of frontier open-source and commercial LLMs show that while models may succeed in shallow queries, they often fail to simulate physical constraints, preserve spatial coherence, or generalize under layout perturbation. PlanQA uncovers a clear blind spot in today's LLMs: they do not consistently reason about real-world layouts. We hope that this benchmark inspires new work on language models that can accurately infer and manipulate spatial and geometric properties in practical settings.
MatCLIP: Light- and Shape-Insensitive Assignment of PBR Material Models
Jan 27, 2025Assigning realistic materials to 3D models remains a significant challenge in computer graphics. We propose MatCLIP, a novel method that extracts shape- and lighting-insensitive descriptors of Physically Based Rendering (PBR) materials to assign plausible textures to 3D objects based on images, such as the output of Latent Diffusion Models (LDMs) or photographs. Matching PBR materials to static images is challenging because the PBR representation captures the dynamic appearance of materials under varying viewing angles, shapes, and lighting conditions. By extending an Alpha-CLIP-based model on material renderings across diverse shapes and lighting, and encoding multiple viewing conditions for PBR materials, our approach generates descriptors that bridge the domains of PBR representations with photographs or renderings, including LDM outputs. This enables consistent material assignments without requiring explicit knowledge of material relationships between different parts of an object. MatCLIP achieves a top-1 classification accuracy of 76.6%, outperforming state-of-the-art methods such as PhotoShape and MatAtlas by over 15 percentage points on publicly available datasets. Our method can be used to construct material assignments for 3D shape datasets such as ShapeNet, 3DCoMPaT++, and Objaverse. All code and data will be released.
WinSyn: A High Resolution Testbed for Synthetic Data
Oct 09, 2023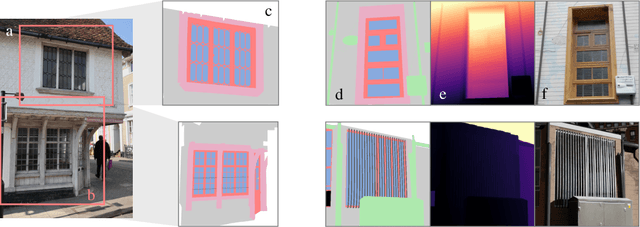



We present WinSyn, a dataset consisting of high-resolution photographs and renderings of 3D models as a testbed for synthetic-to-real research. The dataset consists of 75,739 high-resolution photographs of building windows, including traditional and modern designs, captured globally. These include 89,318 cropped subimages of windows, of which 9,002 are semantically labeled. Further, we present our domain-matched photorealistic procedural model which enables experimentation over a variety of parameter distributions and engineering approaches. Our procedural model provides a second corresponding dataset of 21,290 synthetic images. This jointly developed dataset is designed to facilitate research in the field of synthetic-to-real learning and synthetic data generation. WinSyn allows experimentation into the factors that make it challenging for synthetic data to compete with real-world data. We perform ablations using our synthetic model to identify the salient rendering, materials, and geometric factors pertinent to accuracy within the labeling task. We chose windows as a benchmark because they exhibit a large variability of geometry and materials in their design, making them ideal to study synthetic data generation in a constrained setting. We argue that the dataset is a crucial step to enable future research in synthetic data generation for deep learning.
CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions
Dec 09, 2021

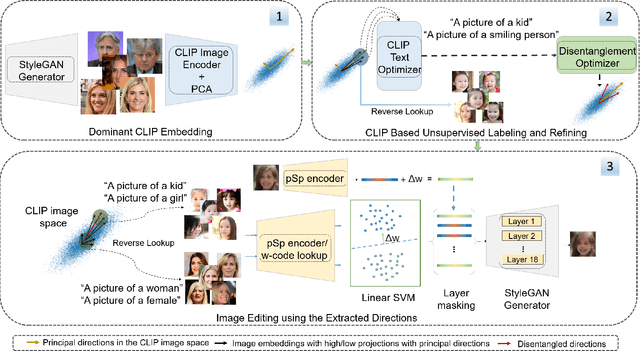

The success of StyleGAN has enabled unprecedented semantic editing capabilities, on both synthesized and real images. However, such editing operations are either trained with semantic supervision or described using human guidance. In another development, the CLIP architecture has been trained with internet-scale image and text pairings and has been shown to be useful in several zero-shot learning settings. In this work, we investigate how to effectively link the pretrained latent spaces of StyleGAN and CLIP, which in turn allows us to automatically extract semantically labeled edit directions from StyleGAN, finding and naming meaningful edit operations without any additional human guidance. Technically, we propose two novel building blocks; one for finding interesting CLIP directions and one for labeling arbitrary directions in CLIP latent space. The setup does not assume any pre-determined labels and hence we do not require any additional supervised text/attributes to build the editing framework. We evaluate the effectiveness of the proposed method and demonstrate that extraction of disentangled labeled StyleGAN edit directions is indeed possible, and reveals interesting and non-trivial edit directions.
Mind the Gap: Domain Gap Control for Single Shot Domain Adaptation for Generative Adversarial Networks
Oct 15, 2021

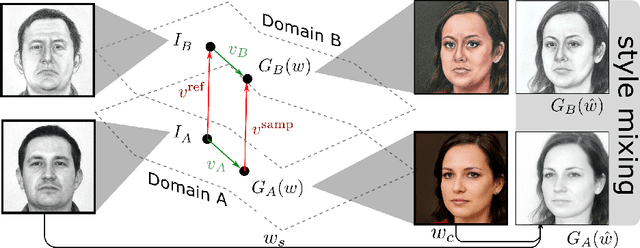
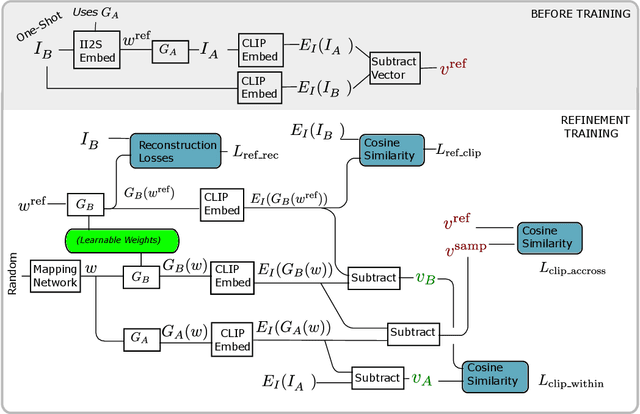
We present a new method for one shot domain adaptation. The input to our method is trained GAN that can produce images in domain A and a single reference image I_B from domain B. The proposed algorithm can translate any output of the trained GAN from domain A to domain B. There are two main advantages of our method compared to the current state of the art: First, our solution achieves higher visual quality, e.g. by noticeably reducing overfitting. Second, our solution allows for more degrees of freedom to control the domain gap, i.e. what aspects of image I_B are used to define the domain B. Technically, we realize the new method by building on a pre-trained StyleGAN generator as GAN and a pre-trained CLIP model for representing the domain gap. We propose several new regularizers for controlling the domain gap to optimize the weights of the pre-trained StyleGAN generator to output images in domain B instead of domain A. The regularizers prevent the optimization from taking on too many attributes of the single reference image. Our results show significant visual improvements over the state of the art as well as multiple applications that highlight improved control.
Barbershop: GAN-based Image Compositing using Segmentation Masks
Jun 02, 2021
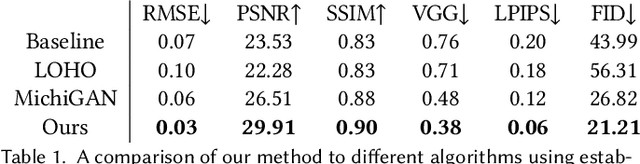
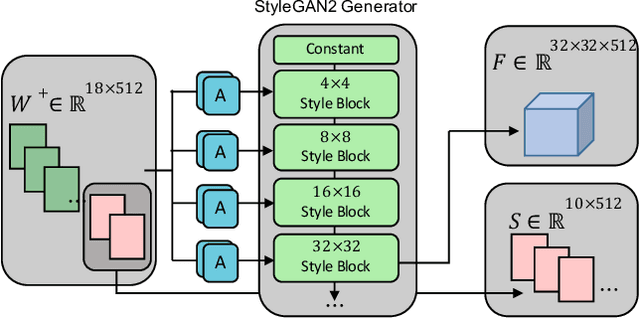

Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains difficult to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending which is better at preserving detail and encoding spatial information, and propose a new GAN-embedding algorithm which is able to slightly modify images to conform to a common segmentation mask. Our novel representation enables the transfer of the visual properties from multiple reference images including specific details such as moles and wrinkles, and because we do image blending in a latent-space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present in other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
Facade Segmentation in the Wild
May 09, 2018



Urban facade segmentation from automatically acquired imagery, in contrast to traditional image segmentation, poses several unique challenges. 360-degree photospheres captured from vehicles are an effective way to capture a large number of images, but this data presents difficult-to-model warping and stitching artifacts. In addition, each pixel can belong to multiple facade elements, and different facade elements (e.g., window, balcony, sill, etc.) are correlated and vary wildly in their characteristics. In this paper, we propose three network architectures of varying complexity to achieve multilabel semantic segmentation of facade images while exploiting their unique characteristics. Specifically, we propose a MULTIFACSEGNET architecture to assign multiple labels to each pixel, a SEPARABLE architecture as a low-rank formulation that encourages extraction of rectangular elements, and a COMPATIBILITY network that simultaneously seeks segmentation across facade element types allowing the network to 'see' intermediate output probabilities of the various facade element classes. Our results on benchmark datasets show significant improvements over existing facade segmentation approaches for the typical facade elements. For example, on one commonly used dataset, the accuracy scores for window(the most important architectural element) increases from 0.91 to 0.97 percent compared to the best competing method, and comparable improvements on other element types.