 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelix4D: Complex 4D Mesh Generation
May 25, 2026Current video-to-4D methods struggle with complex topology changes, transparent materials, thin structures, and inner surfaces. We present Helix4D, a dynamic mesh generation framework by inheriting the expressive representation of Trellis2, adapting it from image-to-3D to video-conditioned 4D generation. Our design arises from two key questions: (a) how to enable Trellis2's frame-local attention to share information across frames while preserving its pretrained quality on rare cases such as transparent objects and inner surfaces, and (b) how to inject temporal information into a purely 3D positional encoding without breaking pretrained capabilities. We address (a) with a sliding-window cross-frame attention and anchor on the first frame. The first frame is generated by the base Trellis2 model and injected into our model, letting it inherit Trellis2's quality in rare cases through cross-frame attention. We address (b) with a 4D temporal encoding that repurposes redundant low-frequency spatial RoPE bands for time, extending the encoding from 3D with no additional parameters. Extensive experiments show the effectiveness of Helix4D for high-quality dynamic mesh generation on ActionBench and our own challenging complex dynamics set.
NearID: Identity Representation Learning via Near-identity Distractors
Apr 02, 2026When evaluating identity-focused tasks such as personalized generation and image editing, existing vision encoders entangle object identity with background context, leading to unreliable representations and metrics. We introduce the first principled framework to address this vulnerability using Near-identity (NearID) distractors, where semantically similar but distinct instances are placed on the exact same background as a reference image, eliminating contextual shortcuts and isolating identity as the sole discriminative signal. Based on this principle, we present the NearID dataset (19K identities, 316K matched-context distractors) together with a strict margin-based evaluation protocol. Under this setting, pre-trained encoders perform poorly, achieving Sample Success Rates (SSR), a strict margin-based identity discrimination metric, as low as 30.7% and often ranking distractors above true cross-view matches. We address this by learning identity-aware representations on a frozen backbone using a two-tier contrastive objective enforcing the hierarchy: same identity > NearID distractor > random negative. This improves SSR to 99.2%, enhances part-level discrimination by 28.0%, and yields stronger alignment with human judgments on DreamBench++, a human-aligned benchmark for personalization. Project page: https://gorluxor.github.io/NearID/
ArtifactLens: Hundreds of Labels Are Enough for Artifact Detection with VLMs
Feb 10, 2026Modern image generators produce strikingly realistic images, where only artifacts like distorted hands or warped objects reveal their synthetic origin. Detecting these artifacts is essential: without detection, we cannot benchmark generators or train reward models to improve them. Current detectors fine-tune VLMs on tens of thousands of labeled images, but this is expensive to repeat whenever generators evolve or new artifact types emerge. We show that pretrained VLMs already encode the knowledge needed to detect artifacts - with the right scaffolding, this capability can be unlocked using only a few hundred labeled examples per artifact category. Our system, ArtifactLens, achieves state-of-the-art on five human artifact benchmarks (the first evaluation across multiple datasets) while requiring orders of magnitude less labeled data. The scaffolding consists of a multi-component architecture with in-context learning and text instruction optimization, with novel improvements to each. Our methods generalize to other artifact types - object morphology, animal anatomy, and entity interactions - and to the distinct task of AIGC detection.
Visual Personalization Turing Test
Jan 30, 2026We introduce the Visual Personalization Turing Test (VPTT), a new paradigm for evaluating contextual visual personalization based on perceptual indistinguishability, rather than identity replication. A model passes the VPTT if its output (image, video, 3D asset, etc.) is indistinguishable to a human or calibrated VLM judge from content a given person might plausibly create or share. To operationalize VPTT, we present the VPTT Framework, integrating a 10k-persona benchmark (VPTT-Bench), a visual retrieval-augmented generator (VPRAG), and the VPTT Score, a text-only metric calibrated against human and VLM judgments. We show high correlation across human, VLM, and VPTT evaluations, validating the VPTT Score as a reliable perceptual proxy. Experiments demonstrate that VPRAG achieves the best alignment-originality balance, offering a scalable and privacy-safe foundation for personalized generative AI.
Tuning-free Visual Effect Transfer across Videos
Jan 13, 2026We present RefVFX, a new framework that transfers complex temporal effects from a reference video onto a target video or image in a feed-forward manner. While existing methods excel at prompt-based or keyframe-conditioned editing, they struggle with dynamic temporal effects such as dynamic lighting changes or character transformations, which are difficult to describe via text or static conditions. Transferring a video effect is challenging, as the model must integrate the new temporal dynamics with the input video's existing motion and appearance. % To address this, we introduce a large-scale dataset of triplets, where each triplet consists of a reference effect video, an input image or video, and a corresponding output video depicting the transferred effect. Creating this data is non-trivial, especially the video-to-video effect triplets, which do not exist naturally. To generate these, we propose a scalable automated pipeline that creates high-quality paired videos designed to preserve the input's motion and structure while transforming it based on some fixed, repeatable effect. We then augment this data with image-to-video effects derived from LoRA adapters and code-based temporal effects generated through programmatic composition. Building on our new dataset, we train our reference-conditioned model using recent text-to-video backbones. Experimental results demonstrate that RefVFX produces visually consistent and temporally coherent edits, generalizes across unseen effect categories, and outperforms prompt-only baselines in both quantitative metrics and human preference. See our website https://tuningfreevisualeffects-maker.github.io/Tuning-free-Visual-Effect-Transfer-across-Videos-Project-Page/
Zero-Shot Dynamic Concept Personalization with Grid-Based LoRA
Jul 23, 2025
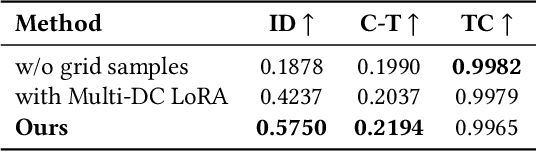
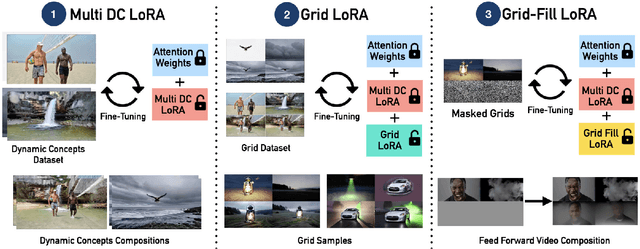
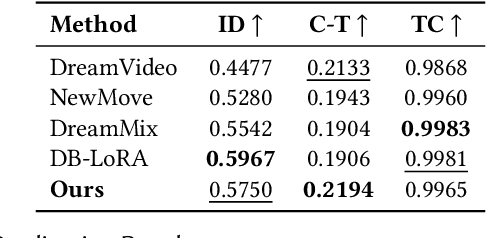
Recent advances in text-to-video generation have enabled high-quality synthesis from text and image prompts. While the personalization of dynamic concepts, which capture subject-specific appearance and motion from a single video, is now feasible, most existing methods require per-instance fine-tuning, limiting scalability. We introduce a fully zero-shot framework for dynamic concept personalization in text-to-video models. Our method leverages structured 2x2 video grids that spatially organize input and output pairs, enabling the training of lightweight Grid-LoRA adapters for editing and composition within these grids. At inference, a dedicated Grid Fill module completes partially observed layouts, producing temporally coherent and identity preserving outputs. Once trained, the entire system operates in a single forward pass, generalizing to previously unseen dynamic concepts without any test-time optimization. Extensive experiments demonstrate high-quality and consistent results across a wide range of subjects beyond trained concepts and editing scenarios.
Improving the Diffusability of Autoencoders
Feb 20, 2025Latent diffusion models have emerged as the leading approach for generating high-quality images and videos, utilizing compressed latent representations to reduce the computational burden of the diffusion process. While recent advancements have primarily focused on scaling diffusion backbones and improving autoencoder reconstruction quality, the interaction between these components has received comparatively less attention. In this work, we perform a spectral analysis of modern autoencoders and identify inordinate high-frequency components in their latent spaces, which are especially pronounced in the autoencoders with a large bottleneck channel size. We hypothesize that this high-frequency component interferes with the coarse-to-fine nature of the diffusion synthesis process and hinders the generation quality. To mitigate the issue, we propose scale equivariance: a simple regularization strategy that aligns latent and RGB spaces across frequencies by enforcing scale equivariance in the decoder. It requires minimal code changes and only up to 20K autoencoder fine-tuning steps, yet significantly improves generation quality, reducing FID by 19% for image generation on ImageNet-1K 256x256 and FVD by at least 44% for video generation on Kinetics-700 17x256x256.
Dynamic Concepts Personalization from Single Videos
Feb 20, 2025
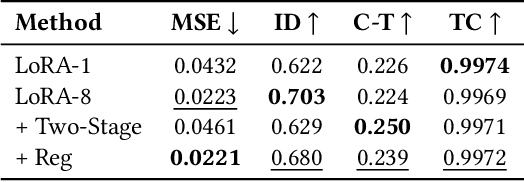
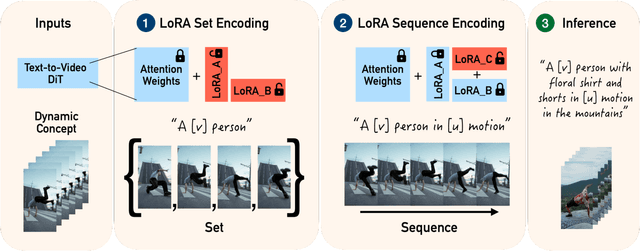
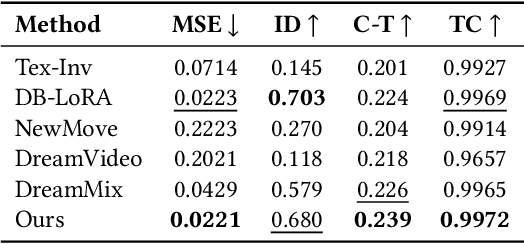
Personalizing generative text-to-image models has seen remarkable progress, but extending this personalization to text-to-video models presents unique challenges. Unlike static concepts, personalizing text-to-video models has the potential to capture dynamic concepts, i.e., entities defined not only by their appearance but also by their motion. In this paper, we introduce Set-and-Sequence, a novel framework for personalizing Diffusion Transformers (DiTs)-based generative video models with dynamic concepts. Our approach imposes a spatio-temporal weight space within an architecture that does not explicitly separate spatial and temporal features. This is achieved in two key stages. First, we fine-tune Low-Rank Adaptation (LoRA) layers using an unordered set of frames from the video to learn an identity LoRA basis that represents the appearance, free from temporal interference. In the second stage, with the identity LoRAs frozen, we augment their coefficients with Motion Residuals and fine-tune them on the full video sequence, capturing motion dynamics. Our Set-and-Sequence framework results in a spatio-temporal weight space that effectively embeds dynamic concepts into the video model's output domain, enabling unprecedented editability and compositionality while setting a new benchmark for personalizing dynamic concepts.
Interpreting the Weight Space of Customized Diffusion Models
Jun 13, 2024


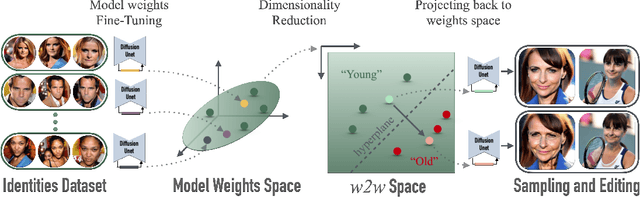
We investigate the space of weights spanned by a large collection of customized diffusion models. We populate this space by creating a dataset of over 60,000 models, each of which is a base model fine-tuned to insert a different person's visual identity. We model the underlying manifold of these weights as a subspace, which we term weights2weights. We demonstrate three immediate applications of this space -- sampling, editing, and inversion. First, as each point in the space corresponds to an identity, sampling a set of weights from it results in a model encoding a novel identity. Next, we find linear directions in this space corresponding to semantic edits of the identity (e.g., adding a beard). These edits persist in appearance across generated samples. Finally, we show that inverting a single image into this space reconstructs a realistic identity, even if the input image is out of distribution (e.g., a painting). Our results indicate that the weight space of fine-tuned diffusion models behaves as an interpretable latent space of identities.
Gaussian Shell Maps for Efficient 3D Human Generation
Nov 29, 2023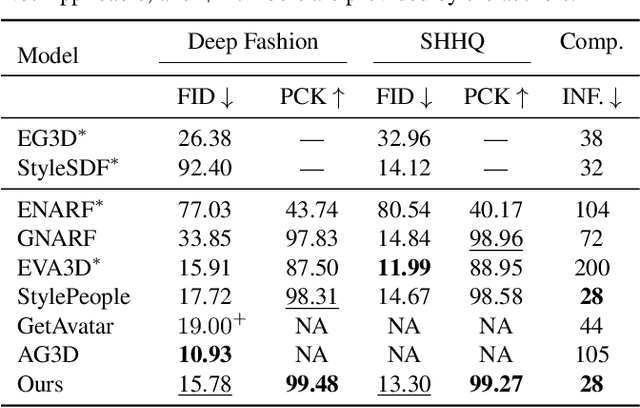



Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell--based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of $512 \times 512$ pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.