 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions
Paper and Code
Dec 09, 2021

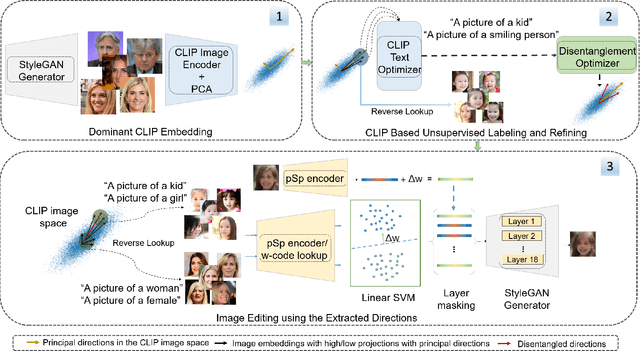

The success of StyleGAN has enabled unprecedented semantic editing capabilities, on both synthesized and real images. However, such editing operations are either trained with semantic supervision or described using human guidance. In another development, the CLIP architecture has been trained with internet-scale image and text pairings and has been shown to be useful in several zero-shot learning settings. In this work, we investigate how to effectively link the pretrained latent spaces of StyleGAN and CLIP, which in turn allows us to automatically extract semantically labeled edit directions from StyleGAN, finding and naming meaningful edit operations without any additional human guidance. Technically, we propose two novel building blocks; one for finding interesting CLIP directions and one for labeling arbitrary directions in CLIP latent space. The setup does not assume any pre-determined labels and hence we do not require any additional supervised text/attributes to build the editing framework. We evaluate the effectiveness of the proposed method and demonstrate that extraction of disentangled labeled StyleGAN edit directions is indeed possible, and reveals interesting and non-trivial edit directions.