 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Sequential Decomposition for Complex Image Editing
May 10, 2026Recent advances in visual generative models have enabled high-fidelity image editing guided by human instructions. However, these models often struggle with complex instructions involving combinatorial editing operations or inter-step dependencies. This difficulty stems from the limitations of two canonical paradigms: (1) single-turn editing, which attempts to apply all instructed edits in one pass, often fails to parse the complex instruction accurately and causes undesired edits; and (2) sequential editing can decompose the task into simpler steps but suffers from compounding errors introduced by the sequential execution, leading to low-fidelity results. To derive a robust solution for complex image editing, we examine editing behaviors of different paradigms under a unified in-context editing framework, and study how the benefits of sequential decomposition can be balanced against its error-accumulation drawbacks. We further develop a synthetic data pipeline that constructs editing tasks of varying instruction complexity, allowing us to curate a large-scale editing dataset with high-quality decomposed sequences. By finetuning on synthetic data, we discovered that with properly designed editing paradigms, sequential decomposition yields robust improvements even as task complexity increases. Furthermore, the decomposition skills learned from synthetic tasks can transfer to real images by co-training with real-world editing data, demonstrating the promise of sim-to-real generalization for tackling complex image editing across broader domains.
MMCORE: MultiModal COnnection with Representation Aligned Latent Embeddings
Apr 21, 2026We present MMCORE, a unified framework designed for multimodal image generation and editing. MMCORE leverages a pre-trained Vision-Language Model (VLM) to predict semantic visual embeddings via learnable query tokens, which subsequently serve as conditioning signals for a diffusion model. This streamlined design effectively transfers the rich understanding and reasoning capabilities of VLMs into the visual generation process. By obviating the need for deep fusion between autoregressive and diffusion models or training from scratch, MMCORE significantly reduces computational overhead while maintaining high-fidelity synthesis. MMCORE seamlessly integrates text-to-image synthesis with interleaved image generation, demonstrating robust multimodal comprehension in complex scenarios such as spatial reasoning and visual grounding. Comprehensive evaluations indicate that MMCORE consistently outperforms state-of-the-art baselines across a broad spectrum of text-to-image and single/multi-image editing benchmarks.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025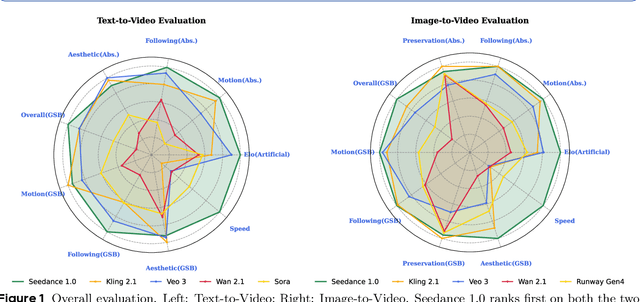
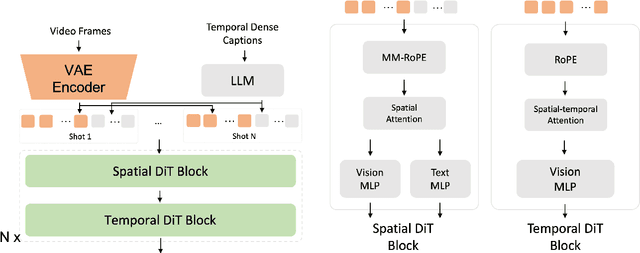
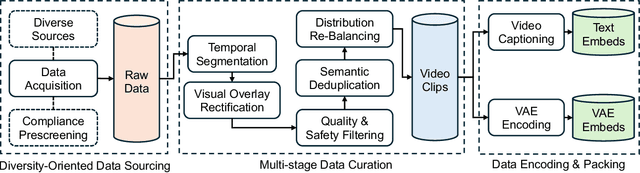
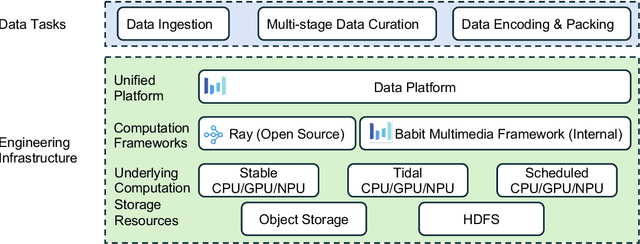
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
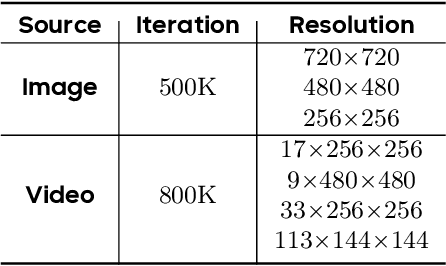
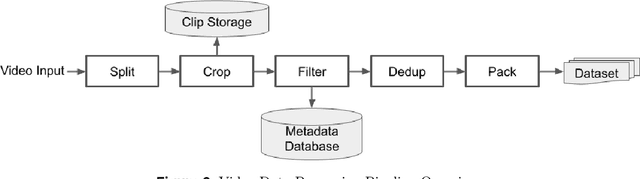

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Learning Feature-Preserving Portrait Editing from Generated Pairs
Jul 29, 2024Portrait editing is challenging for existing techniques due to difficulties in preserving subject features like identity. In this paper, we propose a training-based method leveraging auto-generated paired data to learn desired editing while ensuring the preservation of unchanged subject features. Specifically, we design a data generation process to create reasonably good training pairs for desired editing at low cost. Based on these pairs, we introduce a Multi-Conditioned Diffusion Model to effectively learn the editing direction and preserve subject features. During inference, our model produces accurate editing mask that can guide the inference process to further preserve detailed subject features. Experiments on costume editing and cartoon expression editing show that our method achieves state-of-the-art quality, quantitatively and qualitatively.
3DAvatarGAN: Bridging Domains for Personalized Editable Avatars
Jan 06, 2023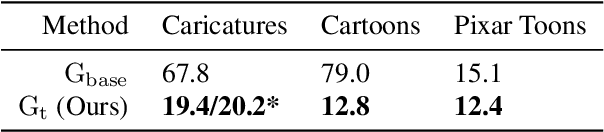

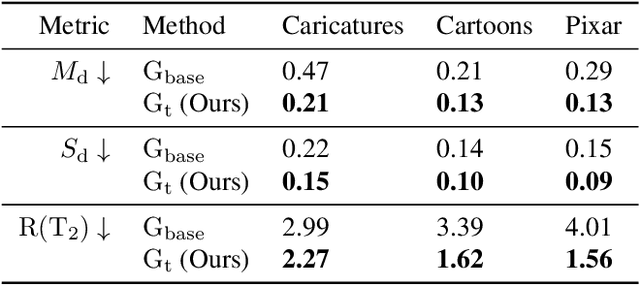
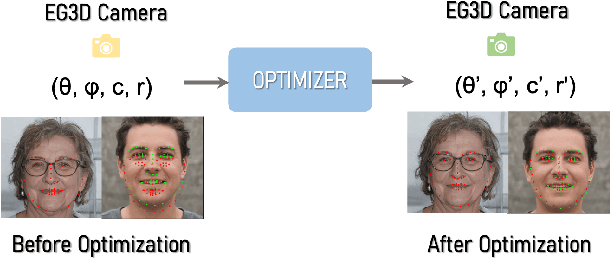
Modern 3D-GANs synthesize geometry and texture by training on large-scale datasets with a consistent structure. Training such models on stylized, artistic data, with often unknown, highly variable geometry, and camera information has not yet been shown possible. Can we train a 3D GAN on such artistic data, while maintaining multi-view consistency and texture quality? To this end, we propose an adaptation framework, where the source domain is a pre-trained 3D-GAN, while the target domain is a 2D-GAN trained on artistic datasets. We then distill the knowledge from a 2D generator to the source 3D generator. To do that, we first propose an optimization-based method to align the distributions of camera parameters across domains. Second, we propose regularizations necessary to learn high-quality texture, while avoiding degenerate geometric solutions, such as flat shapes. Third, we show a deformation-based technique for modeling exaggerated geometry of artistic domains, enabling -- as a byproduct -- personalized geometric editing. Finally, we propose a novel inversion method for 3D-GANs linking the latent spaces of the source and the target domains. Our contributions -- for the first time -- allow for the generation, editing, and animation of personalized artistic 3D avatars on artistic datasets.
Video2StyleGAN: Disentangling Local and Global Variations in a Video
May 30, 2022
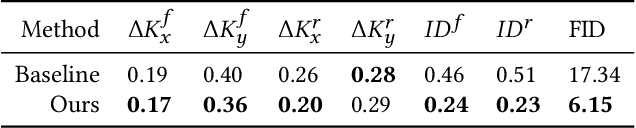
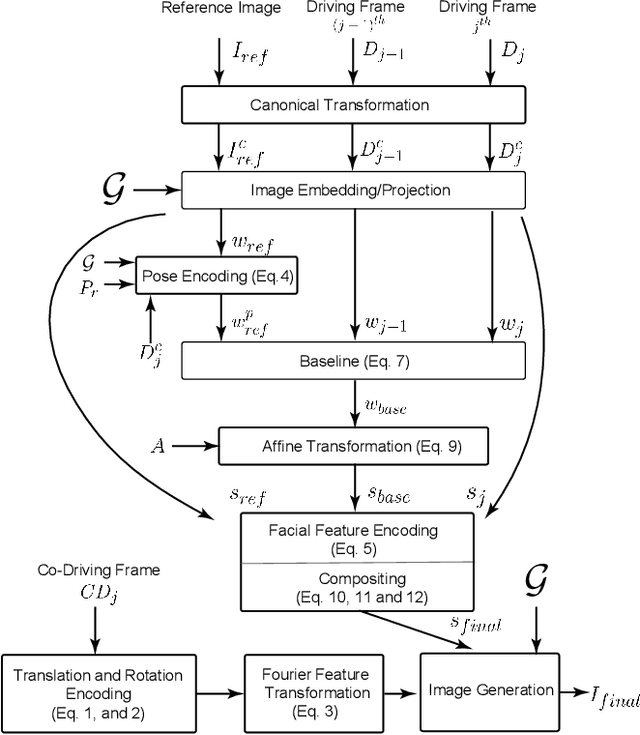

Image editing using a pretrained StyleGAN generator has emerged as a powerful paradigm for facial editing, providing disentangled controls over age, expression, illumination, etc. However, the approach cannot be directly adopted for video manipulations. We hypothesize that the main missing ingredient is the lack of fine-grained and disentangled control over face location, face pose, and local facial expressions. In this work, we demonstrate that such a fine-grained control is indeed achievable using pretrained StyleGAN by working across multiple (latent) spaces (namely, the positional space, the W+ space, and the S space) and combining the optimization results across the multiple spaces. Building on this enabling component, we introduce Video2StyleGAN that takes a target image and driving video(s) to reenact the local and global locations and expressions from the driving video in the identity of the target image. We evaluate the effectiveness of our method over multiple challenging scenarios and demonstrate clear improvements over alternative approaches.
CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions
Dec 09, 2021

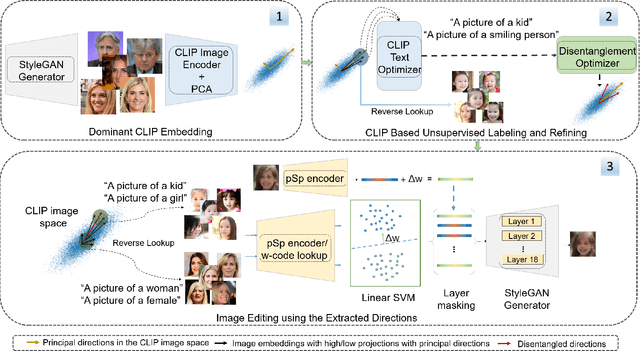

The success of StyleGAN has enabled unprecedented semantic editing capabilities, on both synthesized and real images. However, such editing operations are either trained with semantic supervision or described using human guidance. In another development, the CLIP architecture has been trained with internet-scale image and text pairings and has been shown to be useful in several zero-shot learning settings. In this work, we investigate how to effectively link the pretrained latent spaces of StyleGAN and CLIP, which in turn allows us to automatically extract semantically labeled edit directions from StyleGAN, finding and naming meaningful edit operations without any additional human guidance. Technically, we propose two novel building blocks; one for finding interesting CLIP directions and one for labeling arbitrary directions in CLIP latent space. The setup does not assume any pre-determined labels and hence we do not require any additional supervised text/attributes to build the editing framework. We evaluate the effectiveness of the proposed method and demonstrate that extraction of disentangled labeled StyleGAN edit directions is indeed possible, and reveals interesting and non-trivial edit directions.
Mind the Gap: Domain Gap Control for Single Shot Domain Adaptation for Generative Adversarial Networks
Oct 15, 2021

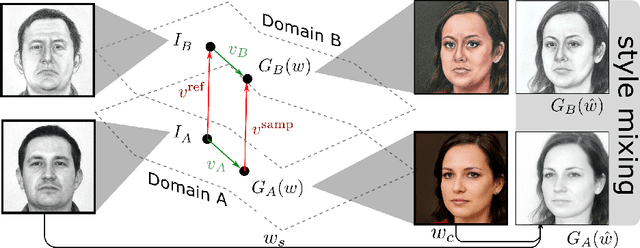
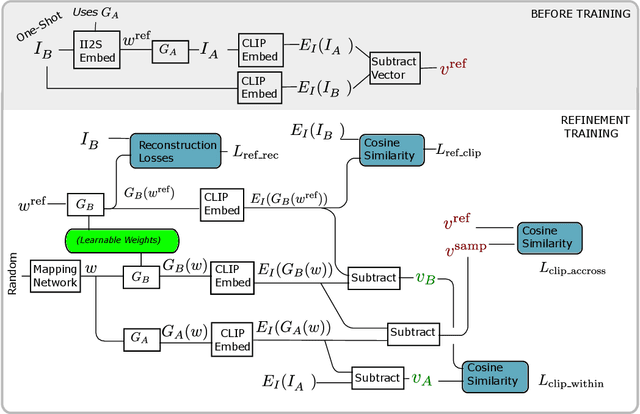
We present a new method for one shot domain adaptation. The input to our method is trained GAN that can produce images in domain A and a single reference image I_B from domain B. The proposed algorithm can translate any output of the trained GAN from domain A to domain B. There are two main advantages of our method compared to the current state of the art: First, our solution achieves higher visual quality, e.g. by noticeably reducing overfitting. Second, our solution allows for more degrees of freedom to control the domain gap, i.e. what aspects of image I_B are used to define the domain B. Technically, we realize the new method by building on a pre-trained StyleGAN generator as GAN and a pre-trained CLIP model for representing the domain gap. We propose several new regularizers for controlling the domain gap to optimize the weights of the pre-trained StyleGAN generator to output images in domain B instead of domain A. The regularizers prevent the optimization from taking on too many attributes of the single reference image. Our results show significant visual improvements over the state of the art as well as multiple applications that highlight improved control.
Flow-Guided Video Inpainting with Scene Templates
Aug 29, 2021

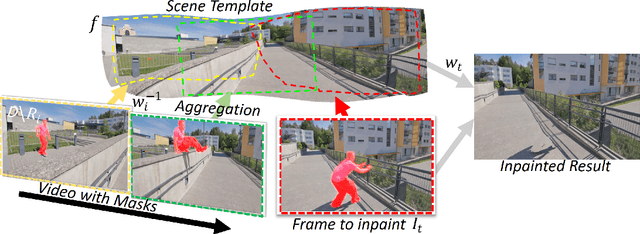

We consider the problem of filling in missing spatio-temporal regions of a video. We provide a novel flow-based solution by introducing a generative model of images in relation to the scene (without missing regions) and mappings from the scene to images. We use the model to jointly infer the scene template, a 2D representation of the scene, and the mappings. This ensures consistency of the frame-to-frame flows generated to the underlying scene, reducing geometric distortions in flow based inpainting. The template is mapped to the missing regions in the video by a new L2-L1 interpolation scheme, creating crisp inpaintings and reducing common blur and distortion artifacts. We show on two benchmark datasets that our approach out-performs state-of-the-art quantitatively and in user studies.