 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution (OOD) Detectors for Open-Set RF Fingerprinting
Jun 10, 2026Radio-frequency (RF) fingerprinting systems must operate in open-world environments where signals from unknown transmitters and temporal drift introduce distribution shift at test time. Out-of-distribution (OOD) detection provides a natural framework for this problem, yet its application to RF fingerprinting (RFF) remains limited. A key barrier to their adoption is that most OOD detectors require auxiliary OOD data for parameter tuning, an assumption that is difficult to satisfy in RF environments where representative OOD data is impractical to collect. In this work, we introduce a promising set of OOD detection methods from the machine learning literature to open-set RFF domain. We present these methods within a unified mathematical framework based on information theory, which is a natural framework for communication systems. Our framework allows for the systematic analysis of methods and development of new methods. We further demonstrate the applicability of recent work on tuning OOD detectors without given OOD tuning data for open-set RFF. We evaluate on the POWDER RF fingerprinting dataset, showing that detectors tuned without any given OOD data achieve performance comparable to baselines with access to true OOD tuning data and greatly out-perform baseline approaches without access to true OOD tuning data, showcasing the practical viability for the RFF problem.
Tuning Out-of-Distribution (OOD) Detectors Without Given OOD Data
Feb 05, 2026Existing out-of-distribution (OOD) detectors are often tuned by a separate dataset deemed OOD with respect to the training distribution of a neural network (NN). OOD detectors process the activations of NN layers and score the output, where parameters of the detectors are determined by fitting to an in-distribution (training) set and the aforementioned dataset chosen adhocly. At detector training time, this adhoc dataset may not be available or difficult to obtain, and even when it's available, it may not be representative of actual OOD data, which is often ''unknown unknowns." Current benchmarks may specify some left-out set from test OOD sets. We show that there can be significant variance in performance of detectors based on the adhoc dataset chosen in current literature, and thus even if such a dataset can be collected, the performance of the detector may be highly dependent on the choice. In this paper, we introduce and formalize the often neglected problem of tuning OOD detectors without a given ``OOD'' dataset. To this end, we present strong baselines as an attempt to approach this problem. Furthermore, we propose a new generic approach to OOD detector tuning that does not require any extra data other than those used to train the NN. We show that our approach improves over baseline methods consistently across higher-parameter OOD detector families, while being comparable across lower-parameter families.
A Variational Information Theoretic Approach to Out-of-Distribution Detection
Jun 17, 2025We present a theory for the construction of out-of-distribution (OOD) detection features for neural networks. We introduce random features for OOD through a novel information-theoretic loss functional consisting of two terms, the first based on the KL divergence separates resulting in-distribution (ID) and OOD feature distributions and the second term is the Information Bottleneck, which favors compressed features that retain the OOD information. We formulate a variational procedure to optimize the loss and obtain OOD features. Based on assumptions on OOD distributions, one can recover properties of existing OOD features, i.e., shaping functions. Furthermore, we show that our theory can predict a new shaping function that out-performs existing ones on OOD benchmarks. Our theory provides a general framework for constructing a variety of new features with clear explainability.
ODE-GS: Latent ODEs for Dynamic Scene Extrapolation with 3D Gaussian Splatting
Jun 05, 2025We present ODE-GS, a novel method that unifies 3D Gaussian Splatting with latent neural ordinary differential equations (ODEs) to forecast dynamic 3D scenes far beyond the time span seen during training. Existing neural rendering systems - whether NeRF- or 3DGS-based - embed time directly in a deformation network and therefore excel at interpolation but collapse when asked to predict the future, where timestamps are strictly out-of-distribution. ODE-GS eliminates this dependency: after learning a high-fidelity, time-conditioned deformation model for the training window, we freeze it and train a Transformer encoder that summarizes past Gaussian trajectories into a latent state whose continuous evolution is governed by a neural ODE. Numerical integration of this latent flow yields smooth, physically plausible Gaussian trajectories that can be queried at any future instant and rendered in real time. Coupled with a variational objective and a lightweight second-derivative regularizer, ODE-GS attains state-of-the-art extrapolation on D-NeRF and NVFI benchmarks, improving PSNR by up to 10 dB and halving perceptual error (LPIPS) relative to the strongest baselines. Our results demonstrate that continuous-time latent dynamics are a powerful, practical route to photorealistic prediction of complex 3D scenes.
HAct: Out-of-Distribution Detection with Neural Net Activation Histograms
Sep 09, 2023



We propose a simple, efficient, and accurate method for detecting out-of-distribution (OOD) data for trained neural networks, a potential first step in methods for OOD generalization. We propose a novel descriptor, HAct - activation histograms, for OOD detection, that is, probability distributions (approximated by histograms) of output values of neural network layers under the influence of incoming data. We demonstrate that HAct is significantly more accurate than state-of-the-art on multiple OOD image classification benchmarks. For instance, our approach achieves a true positive rate (TPR) of 95% with only 0.05% false-positives using Resnet-50 on standard OOD benchmarks, outperforming previous state-of-the-art by 20.66% in the false positive rate (at the same TPR of 95%). The low computational complexity and the ease of implementation make HAct suitable for online implementation in monitoring deployed neural networks in practice at scale.
StEik: Stabilizing the Optimization of Neural Signed Distance Functions and Finer Shape Representation
May 28, 2023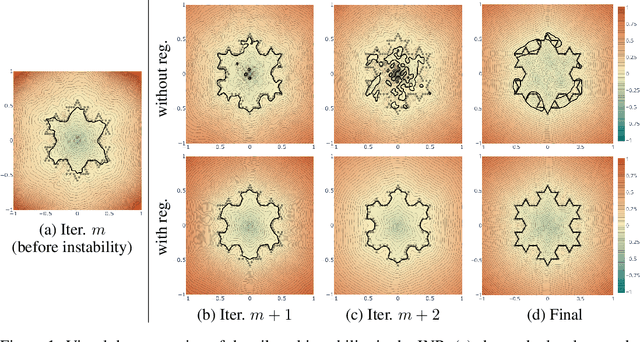

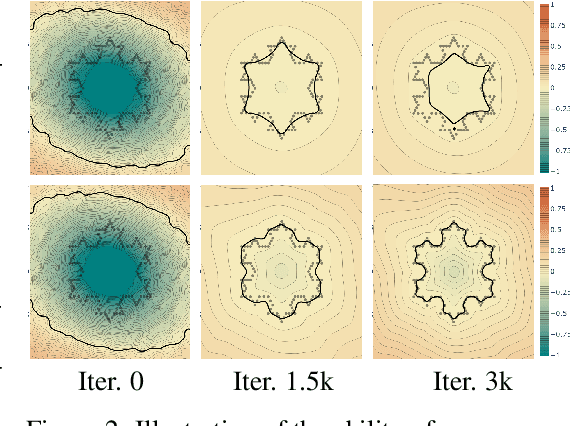

We present new insights and a novel paradigm (StEik) for learning implicit neural representations (INR) of shapes. In particular, we shed light on the popular eikonal loss used for imposing a signed distance function constraint in INR. We show analytically that as the representation power of the network increases, the optimization approaches a partial differential equation (PDE) in the continuum limit that is unstable. We show that this instability can manifest in existing network optimization, leading to irregularities in the reconstructed surface and/or convergence to sub-optimal local minima, and thus fails to capture fine geometric and topological structure. We show analytically how other terms added to the loss, currently used in the literature for other purposes, can actually eliminate these instabilities. However, such terms can over-regularize the surface, preventing the representation of fine shape detail. Based on a similar PDE theory for the continuum limit, we introduce a new regularization term that still counteracts the eikonal instability but without over-regularizing. Furthermore, since stability is now guaranteed in the continuum limit, this stabilization also allows for considering new network structures that are able to represent finer shape detail. We introduce such a structure based on quadratic layers. Experiments on multiple benchmark data sets show that our new regularization and network are able to capture more precise shape details and more accurate topology than existing state-of-the-art.
Flow-Guided Video Inpainting with Scene Templates
Aug 29, 2021

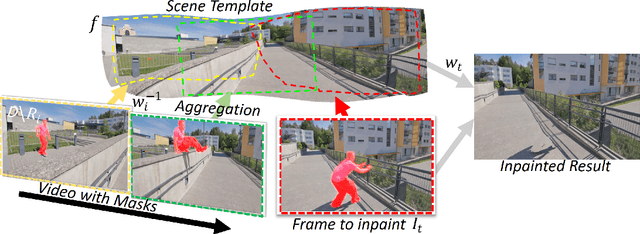

We consider the problem of filling in missing spatio-temporal regions of a video. We provide a novel flow-based solution by introducing a generative model of images in relation to the scene (without missing regions) and mappings from the scene to images. We use the model to jointly infer the scene template, a 2D representation of the scene, and the mappings. This ensures consistency of the frame-to-frame flows generated to the underlying scene, reducing geometric distortions in flow based inpainting. The template is mapped to the missing regions in the video by a new L2-L1 interpolation scheme, creating crisp inpaintings and reducing common blur and distortion artifacts. We show on two benchmark datasets that our approach out-performs state-of-the-art quantitatively and in user studies.
Class-Agnostic Segmentation Loss and Its Application to Salient Object Detection and Segmentation
Jul 16, 2021
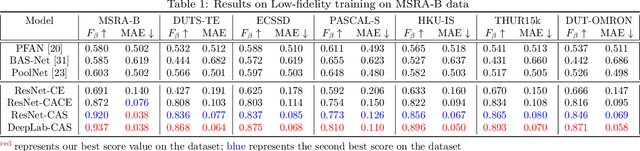

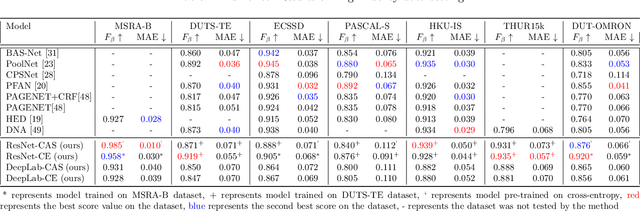
In this paper we present a novel loss function, called class-agnostic segmentation (CAS) loss. With CAS loss the class descriptors are learned during training of the network. We don't require to define the label of a class a-priori, rather the CAS loss clusters regions with similar appearance together in a weakly-supervised manner. Furthermore, we show that the CAS loss function is sparse, bounded, and robust to class-imbalance. We first apply our CAS loss function with fully-convolutional ResNet101 and DeepLab-v3 architectures to the binary segmentation problem of salient object detection. We investigate the performance against the state-of-the-art methods in two settings of low and high-fidelity training data on seven salient object detection datasets. For low-fidelity training data (incorrect class label) class-agnostic segmentation loss outperforms the state-of-the-art methods on salient object detection datasets by staggering margins of around 50%. For high-fidelity training data (correct class labels) class-agnostic segmentation models perform as good as the state-of-the-art approaches while beating the state-of-the-art methods on most datasets. In order to show the utility of the loss function across different domains we then also test on general segmentation dataset, where class-agnostic segmentation loss outperforms competing losses by huge margins.
Shape-Tailored Deep Neural Networks
Feb 16, 2021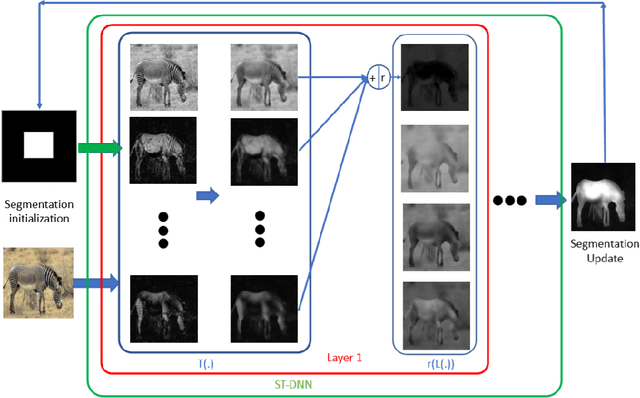
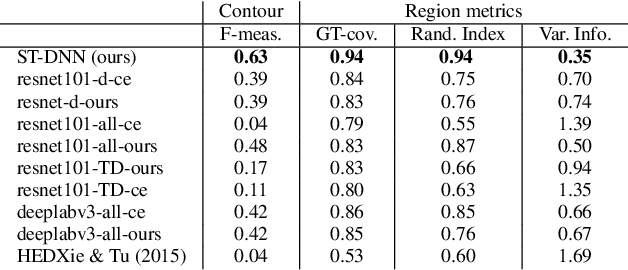
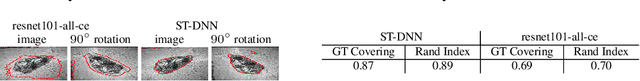

We present Shape-Tailored Deep Neural Networks (ST-DNN). ST-DNN extend convolutional networks (CNN), which aggregate data from fixed shape (square) neighborhoods, to compute descriptors defined on arbitrarily shaped regions. This is natural for segmentation, where descriptors should describe regions (e.g., of objects) that have diverse shape. We formulate these descriptors through the Poisson partial differential equation (PDE), which can be used to generalize convolution to arbitrary regions. We stack multiple PDE layers to generalize a deep CNN to arbitrary regions, and apply it to segmentation. We show that ST-DNN are covariant to translations and rotations and robust to domain deformations, natural for segmentation, which existing CNN based methods lack. ST-DNN are 3-4 orders of magnitude smaller then CNNs used for segmentation. We show that they exceed segmentation performance compared to state-of-the-art CNN-based descriptors using 2-3 orders smaller training sets on the texture segmentation problem.