 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHOW3D: Capturing Scenes of 3D Hands and Objects in the Wild
Mar 30, 2026Accurate 3D understanding of human hands and objects during manipulation remains a significant challenge for egocentric computer vision. Existing hand-object interaction datasets are predominantly captured in controlled studio settings, which limits both environmental diversity and the ability of models trained on such data to generalize to real-world scenarios. To address this challenge, we introduce a novel marker-less multi-camera system that allows for nearly unconstrained mobility in genuinely in-the-wild conditions, while still having the ability to generate precise 3D annotations of hands and objects. The capture system consists of a lightweight, back-mounted, multi-camera rig that is synchronized and calibrated with a user-worn VR headset. For 3D ground-truth annotation of hands and objects, we develop an ego-exo tracking pipeline and rigorously evaluate its quality. Finally, we present SHOW3D, the first large-scale dataset with 3D annotations that show hands interacting with objects in diverse real-world environments, including outdoor settings. Our approach significantly reduces the fundamental trade-off between environmental realism and accuracy of 3D annotations, which we validate with experiments on several downstream tasks. show3d-dataset.github.io
Extending Foundational Monocular Depth Estimators to Fisheye Cameras with Calibration Tokens
Aug 06, 2025We propose a method to extend foundational monocular depth estimators (FMDEs), trained on perspective images, to fisheye images. Despite being trained on tens of millions of images, FMDEs are susceptible to the covariate shift introduced by changes in camera calibration (intrinsic, distortion) parameters, leading to erroneous depth estimates. Our method aligns the distribution of latent embeddings encoding fisheye images to those of perspective images, enabling the reuse of FMDEs for fisheye cameras without retraining or finetuning. To this end, we introduce a set of Calibration Tokens as a light-weight adaptation mechanism that modulates the latent embeddings for alignment. By exploiting the already expressive latent space of FMDEs, we posit that modulating their embeddings avoids the negative impact of artifacts and loss introduced in conventional recalibration or map projection to a canonical reference frame in the image space. Our method is self-supervised and does not require fisheye images but leverages publicly available large-scale perspective image datasets. This is done by recalibrating perspective images to fisheye images, and enforcing consistency between their estimates during training. We evaluate our approach with several FMDEs, on both indoors and outdoors, where we consistently improve over state-of-the-art methods using a single set of tokens for both. Code available at: https://github.com/JungHeeKim29/calibration-token.
ODE-GS: Latent ODEs for Dynamic Scene Extrapolation with 3D Gaussian Splatting
Jun 05, 2025We present ODE-GS, a novel method that unifies 3D Gaussian Splatting with latent neural ordinary differential equations (ODEs) to forecast dynamic 3D scenes far beyond the time span seen during training. Existing neural rendering systems - whether NeRF- or 3DGS-based - embed time directly in a deformation network and therefore excel at interpolation but collapse when asked to predict the future, where timestamps are strictly out-of-distribution. ODE-GS eliminates this dependency: after learning a high-fidelity, time-conditioned deformation model for the training window, we freeze it and train a Transformer encoder that summarizes past Gaussian trajectories into a latent state whose continuous evolution is governed by a neural ODE. Numerical integration of this latent flow yields smooth, physically plausible Gaussian trajectories that can be queried at any future instant and rendered in real time. Coupled with a variational objective and a lightweight second-derivative regularizer, ODE-GS attains state-of-the-art extrapolation on D-NeRF and NVFI benchmarks, improving PSNR by up to 10 dB and halving perceptual error (LPIPS) relative to the strongest baselines. Our results demonstrate that continuous-time latent dynamics are a powerful, practical route to photorealistic prediction of complex 3D scenes.
Radar-Guided Polynomial Fitting for Metric Depth Estimation
Mar 21, 2025



We propose PolyRad, a novel radar-guided depth estimation method that introduces polynomial fitting to transform scaleless depth predictions from pretrained monocular depth estimation (MDE) models into metric depth maps. Unlike existing approaches that rely on complex architectures or expensive sensors, our method is grounded in a simple yet fundamental insight: using polynomial coefficients predicted from cheap, ubiquitous radar data to adaptively adjust depth predictions non-uniformly across depth ranges. Although MDE models often infer reasonably accurate local depth structure within each object or local region, they may misalign these regions relative to one another, making a linear scale-and-shift transformation insufficient given three or more of these regions. In contrast, PolyRad generalizes beyond linear transformations and is able to correct such misalignments by introducing inflection points. Importantly, our polynomial fitting framework preserves structural consistency through a novel training objective that enforces monotonicity via first-derivative regularization. PolyRad achieves state-of-the-art performance on the nuScenes, ZJU-4DRadarCam, and View-of-Delft datasets, outperforming existing methods by 30.3% in MAE and 37.2% in RMSE.
ProtoDepth: Unsupervised Continual Depth Completion with Prototypes
Mar 17, 2025



We present ProtoDepth, a novel prototype-based approach for continual learning of unsupervised depth completion, the multimodal 3D reconstruction task of predicting dense depth maps from RGB images and sparse point clouds. The unsupervised learning paradigm is well-suited for continual learning, as ground truth is not needed. However, when training on new non-stationary distributions, depth completion models will catastrophically forget previously learned information. We address forgetting by learning prototype sets that adapt the latent features of a frozen pretrained model to new domains. Since the original weights are not modified, ProtoDepth does not forget when test-time domain identity is known. To extend ProtoDepth to the challenging setting where the test-time domain identity is withheld, we propose to learn domain descriptors that enable the model to select the appropriate prototype set for inference. We evaluate ProtoDepth on benchmark dataset sequences, where we reduce forgetting compared to baselines by 52.2% for indoor and 53.2% for outdoor to achieve the state of the art.
PriorDiffusion: Leverage Language Prior in Diffusion Models for Monocular Depth Estimation
Nov 24, 2024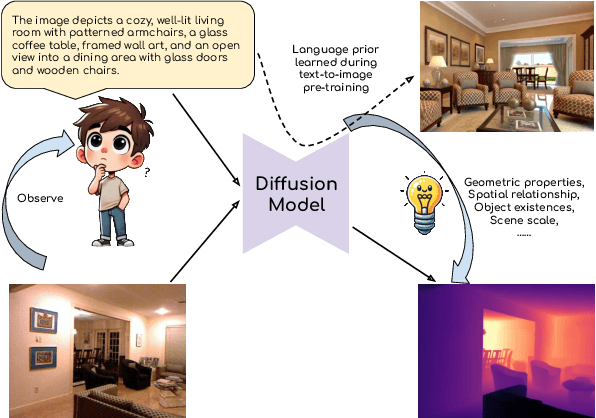
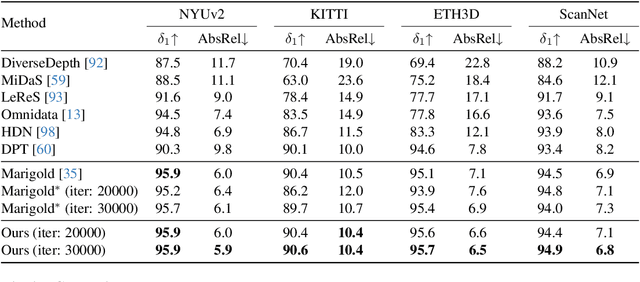
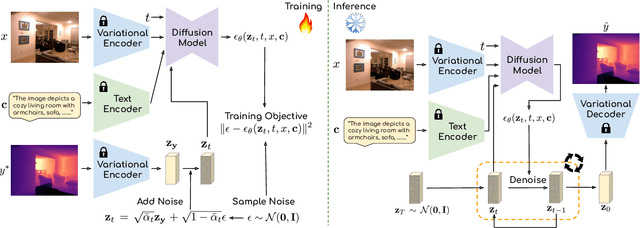
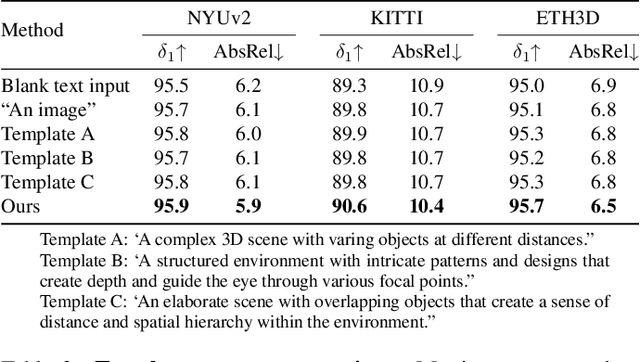
This paper explores the potential of leveraging language priors learned by text-to-image diffusion models to address ambiguity and visual nuisance in monocular depth estimation. Particularly, traditional monocular depth estimation suffers from inherent ambiguity due to the absence of stereo or multi-view depth cues, and nuisance due to lack of robustness of vision. We argue that language prior in diffusion models can enhance monocular depth estimation by leveraging the geometric prior aligned with the language description, which is learned during text-to-image pre-training. To generate images that reflect the text properly, the model must comprehend the size and shape of specified objects, their spatial relationship, and the scale of the scene. Thus, we propose PriorDiffusion, using a pre-trained text-to-image diffusion model that takes both image and text description that aligned with the scene to infer affine-invariant depth through a denoising process. We also show that language priors can guide the model's attention to specific regions and help it perceive the 3D scene in alignment with user intent. Simultaneously, it acts as a constraint to accelerate the convergence of the diffusion trajectory, since learning 3D properties from a condensed, low-dimensional language feature is more efficient compared with learning from a redundant, high-dimensional image feature. By training on HyperSim and Virtual KITTI, we achieve state-of-the-art zero-shot performance and a faster convergence speed, compared with other diffusion-based depth estimators, across NYUv2, KITTI, ETH3D, and ScanNet.
UnCLe: Unsupervised Continual Learning of Depth Completion
Oct 23, 2024



We propose UnCLe, a standardized benchmark for Unsupervised Continual Learning of a multimodal depth estimation task: Depth completion aims to infer a dense depth map from a pair of synchronized RGB image and sparse depth map. We benchmark depth completion models under the practical scenario of unsupervised learning over continuous streams of data. Existing methods are typically trained on a static, or stationary, dataset. However, when adapting to novel non-stationary distributions, they "catastrophically forget" previously learned information. UnCLe simulates these non-stationary distributions by adapting depth completion models to sequences of datasets containing diverse scenes captured from distinct domains using different visual and range sensors. We adopt representative methods from continual learning paradigms and translate them to enable unsupervised continual learning of depth completion. We benchmark these models for indoor and outdoor and investigate the degree of catastrophic forgetting through standard quantitative metrics. Furthermore, we introduce model inversion quality as an additional measure of forgetting. We find that unsupervised continual learning of depth completion is an open problem, and we invite researchers to leverage UnCLe as a development platform.
Quadric Representations for LiDAR Odometry, Mapping and Localization
Apr 27, 2023



Current LiDAR odometry, mapping and localization methods leverage point-wise representations of 3D scenes and achieve high accuracy in autonomous driving tasks. However, the space-inefficiency of methods that use point-wise representations limits their development and usage in practical applications. In particular, scan-submap matching and global map representation methods are restricted by the inefficiency of nearest neighbor searching (NNS) for large-volume point clouds. To improve space-time efficiency, we propose a novel method of describing scenes using quadric surfaces, which are far more compact representations of 3D objects than conventional point clouds. In contrast to point cloud-based methods, our quadric representation-based method decomposes a 3D scene into a collection of sparse quadric patches, which improves storage efficiency and avoids the slow point-wise NNS process. Our method first segments a given point cloud into patches and fits each of them to a quadric implicit function. Each function is then coupled with other geometric descriptors of the patch, such as its center position and covariance matrix. Collectively, these patch representations fully describe a 3D scene, which can be used in place of the original point cloud and employed in LiDAR odometry, mapping and localization algorithms. We further design a novel incremental growing method for quadric representations, which eliminates the need to repeatedly re-fit quadric surfaces from the original point cloud. Extensive odometry, mapping and localization experiments on large-volume point clouds in the KITTI and UrbanLoco datasets demonstrate that our method maintains low latency and memory utility while achieving competitive, and even superior, accuracy.
SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection
Apr 27, 2023By identifying four important components of existing LiDAR-camera 3D object detection methods (LiDAR and camera candidates, transformation, and fusion outputs), we observe that all existing methods either find dense candidates or yield dense representations of scenes. However, given that objects occupy only a small part of a scene, finding dense candidates and generating dense representations is noisy and inefficient. We propose SparseFusion, a novel multi-sensor 3D detection method that exclusively uses sparse candidates and sparse representations. Specifically, SparseFusion utilizes the outputs of parallel detectors in the LiDAR and camera modalities as sparse candidates for fusion. We transform the camera candidates into the LiDAR coordinate space by disentangling the object representations. Then, we can fuse the multi-modality candidates in a unified 3D space by a lightweight self-attention module. To mitigate negative transfer between modalities, we propose novel semantic and geometric cross-modality transfer modules that are applied prior to the modality-specific detectors. SparseFusion achieves state-of-the-art performance on the nuScenes benchmark while also running at the fastest speed, even outperforming methods with stronger backbones. We perform extensive experiments to demonstrate the effectiveness and efficiency of our modules and overall method pipeline. Our code will be made publicly available at https://github.com/yichen928/SparseFusion.