 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cookbook of 3D Vision: Data, Learning Paradigms, and Application
Jun 02, 20263D vision has rapidly evolved, driven by increasingly diverse data representations, learning paradigms, and modeling strategies. Yet the field remains fragmented across representations and benchmarks, making it difficult to develop unified perspectives on efficiency, fidelity, and scalability. This work provides a data-centric taxonomy of 3D vision that connects geometric representations, datasets, learning frameworks, and applications within a single conceptual map. We begin by analysing the principal structural representations of 3D data--point clouds, meshes, voxels, and 3D Gaussians--along with their acquisition pipelines. We then examine how dataset design, benchmark construction, and supervision regimes shape recent advances, spanning 2D-supervised 3D learning, implicit neural representations, and 4D world modeling. Through this integrative lens, we clarify the relationships among representations, learning paradigms, and downstream tasks in reconstruction, generation, and video modeling, offering a consolidated view of emerging trends toward balancing efficiency and fidelity and toward multimodal geometric grounding.
* Accepted to the CVPR 2026 OpenSUN3D Workshop. Official version available at CVF Open Access. https://openaccess.thecvf.com/content/CVPR2026W/OpenSUN3D/html/Du_A_Cookbook_of_3D_Vision_Data_Learning_Paradigms_and_Application_CVPRW_2026_paper.html
InterSketch: An Interleaved Reasoning Model with Self-correcting Visual Sketch and Stepwise Reward
May 26, 2026While vision-language models (VLMs) have exhibited multi-turn visual reasoning capabilities, their reasoning trajectories remain relatively shallow and are dominated by a text-centric paradigm, limiting their applicability to complex visual challenges. In contrast, human-like thought typically involves long-horizon reasoning with an interleaved visual-textual chain-of-thought (VT-CoT). To bridge this gap, we introduce InterSketch, an interleaved reasoning model to enhance the VT-CoT capability via self-correcting and stepwise reward mechanisms. InterSketch dynamically generates intermediate visual sketches using external tools and interleaves them with textual reasoning, enabling effective perception and logical reasoning over long-horizon visual understanding tasks. Specifically, in the first cold-start stage, we propose a synthesized high-quality interleaved VT-CoT dataset and include a reflection mechanism to enable the model's capability in multi-turn interleaved reasoning and self-correction. In the subsequent reinforcement learning (RL) stage, we design a stepwise reward mechanism to mitigate the sparsity of reward signals inherent in end-only supervision over long-horizon reasoning. Extensive experiments on visual reasoning benchmarks demonstrate the effectiveness of InterSketch, even outperforming proprietary models such as Gemini-3-Pro.
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
VideoGPA: Distilling Geometry Priors for 3D-Consistent Video Generation
Jan 30, 2026While recent video diffusion models (VDMs) produce visually impressive results, they fundamentally struggle to maintain 3D structural consistency, often resulting in object deformation or spatial drift. We hypothesize that these failures arise because standard denoising objectives lack explicit incentives for geometric coherence. To address this, we introduce VideoGPA (Video Geometric Preference Alignment), a data-efficient self-supervised framework that leverages a geometry foundation model to automatically derive dense preference signals that guide VDMs via Direct Preference Optimization (DPO). This approach effectively steers the generative distribution toward inherent 3D consistency without requiring human annotations. VideoGPA significantly enhances temporal stability, physical plausibility, and motion coherence using minimal preference pairs, consistently outperforming state-of-the-art baselines in extensive experiments.
Coffee: Controllable Diffusion Fine-tuning
Nov 18, 2025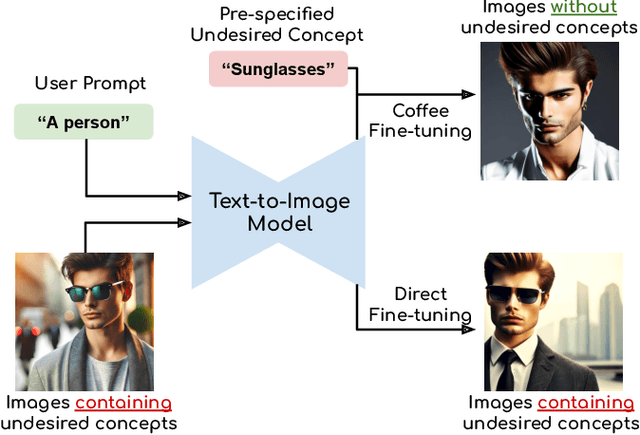
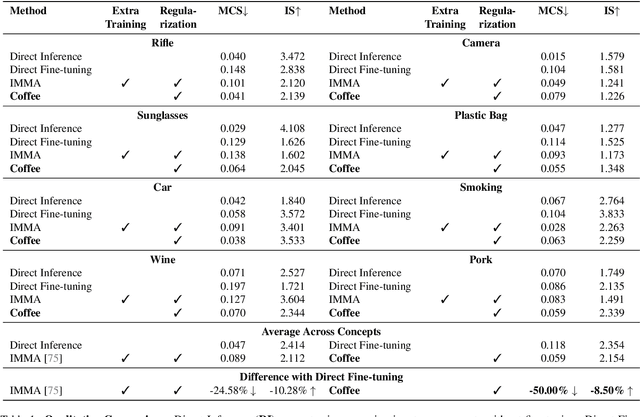

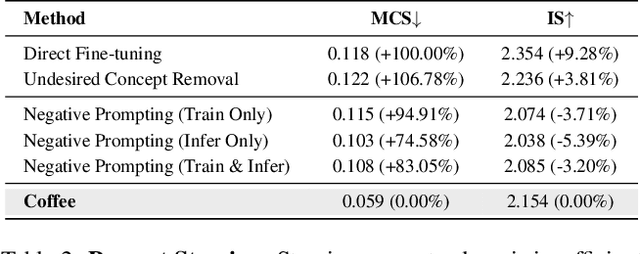
Text-to-image diffusion models can generate diverse content with flexible prompts, which makes them well-suited for customization through fine-tuning with a small amount of user-provided data. However, controllable fine-tuning that prevents models from learning undesired concepts present in the fine-tuning data, and from entangling those concepts with user prompts, remains an open challenge. It is crucial for downstream tasks like bias mitigation, preventing malicious adaptation, attribute disentanglement, and generalizable fine-tuning of diffusion policy. We propose Coffee that allows using language to specify undesired concepts to regularize the adaptation process. The crux of our method lies in keeping the embeddings of the user prompt from aligning with undesired concepts. Crucially, Coffee requires no additional training and enables flexible modification of undesired concepts by modifying textual descriptions. We evaluate Coffee by fine-tuning on images associated with user prompts paired with undesired concepts. Experimental results demonstrate that Coffee can prevent text-to-image models from learning specified undesired concepts during fine-tuning and outperforms existing methods. Code will be released upon acceptance.
CVD-STORM: Cross-View Video Diffusion with Spatial-Temporal Reconstruction Model for Autonomous Driving
Oct 09, 2025Generative models have been widely applied to world modeling for environment simulation and future state prediction. With advancements in autonomous driving, there is a growing demand not only for high-fidelity video generation under various controls, but also for producing diverse and meaningful information such as depth estimation. To address this, we propose CVD-STORM, a cross-view video diffusion model utilizing a spatial-temporal reconstruction Variational Autoencoder (VAE) that generates long-term, multi-view videos with 4D reconstruction capabilities under various control inputs. Our approach first fine-tunes the VAE with an auxiliary 4D reconstruction task, enhancing its ability to encode 3D structures and temporal dynamics. Subsequently, we integrate this VAE into the video diffusion process to significantly improve generation quality. Experimental results demonstrate that our model achieves substantial improvements in both FID and FVD metrics. Additionally, the jointly-trained Gaussian Splatting Decoder effectively reconstructs dynamic scenes, providing valuable geometric information for comprehensive scene understanding.
MaskGWM: A Generalizable Driving World Model with Video Mask Reconstruction
Feb 17, 2025World models that forecast environmental changes from actions are vital for autonomous driving models with strong generalization. The prevailing driving world model mainly build on video prediction model. Although these models can produce high-fidelity video sequences with advanced diffusion-based generator, they are constrained by their predictive duration and overall generalization capabilities. In this paper, we explore to solve this problem by combining generation loss with MAE-style feature-level context learning. In particular, we instantiate this target with three key design: (1) A more scalable Diffusion Transformer (DiT) structure trained with extra mask construction task. (2) we devise diffusion-related mask tokens to deal with the fuzzy relations between mask reconstruction and generative diffusion process. (3) we extend mask construction task to spatial-temporal domain by utilizing row-wise mask for shifted self-attention rather than masked self-attention in MAE. Then, we adopt a row-wise cross-view module to align with this mask design. Based on above improvement, we propose MaskGWM: a Generalizable driving World Model embodied with Video Mask reconstruction. Our model contains two variants: MaskGWM-long, focusing on long-horizon prediction, and MaskGWM-mview, dedicated to multi-view generation. Comprehensive experiments on standard benchmarks validate the effectiveness of the proposed method, which contain normal validation of Nuscene dataset, long-horizon rollout of OpenDV-2K dataset and zero-shot validation of Waymo dataset. Quantitative metrics on these datasets show our method notably improving state-of-the-art driving world model.
Efficient Interactive 3D Multi-Object Removal
Jan 30, 2025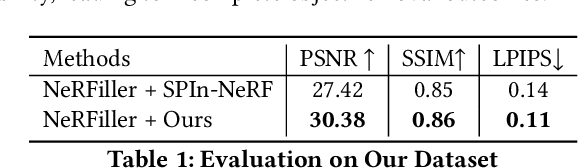
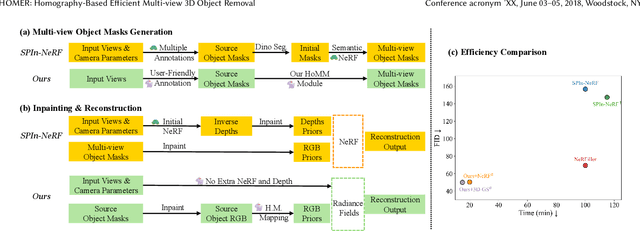
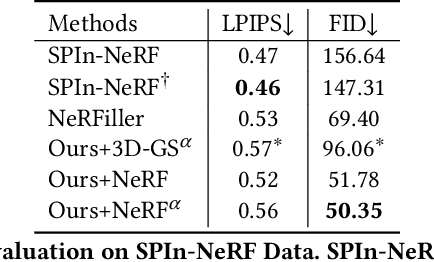
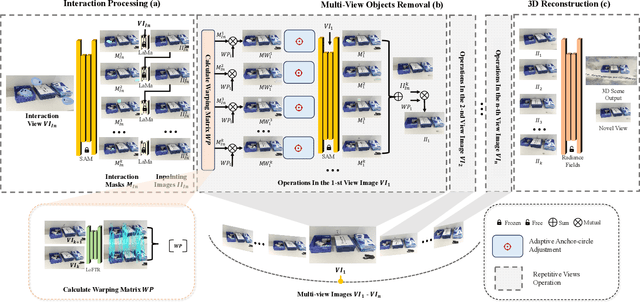
Object removal is of great significance to 3D scene understanding, essential for applications in content filtering and scene editing. Current mainstream methods primarily focus on removing individual objects, with a few methods dedicated to eliminating an entire area or all objects of a certain category. They however confront the challenge of insufficient granularity and flexibility for real-world applications, where users demand tailored excision and preservation of objects within defined zones. In addition, most of the current methods require kinds of priors when addressing multi-view inpainting, which is time-consuming. To address these limitations, we propose an efficient and user-friendly pipeline for 3D multi-object removal, enabling users to flexibly select areas and define objects for removal or preservation. Concretely, to ensure object consistency and correspondence across multiple views, we propose a novel mask matching and refinement module, which integrates homography-based warping with high-confidence anchor points for segmentation. By leveraging the IoU joint shape context distance loss, we enhance the accuracy of warped masks and improve subsequent inpainting processes. Considering the current immaturity of 3D multi-object removal, we provide a new evaluation dataset to bridge the developmental void. Experimental results demonstrate that our method significantly reduces computational costs, achieving processing speeds more than 80% faster than state-of-the-art methods while maintaining equivalent or higher reconstruction quality.
UniMLVG: Unified Framework for Multi-view Long Video Generation with Comprehensive Control Capabilities for Autonomous Driving
Dec 06, 2024The creation of diverse and realistic driving scenarios has become essential to enhance perception and planning capabilities of the autonomous driving system. However, generating long-duration, surround-view consistent driving videos remains a significant challenge. To address this, we present UniMLVG, a unified framework designed to generate extended street multi-perspective videos under precise control. By integrating single- and multi-view driving videos into the training data, our approach updates cross-frame and cross-view modules across three stages with different training objectives, substantially boosting the diversity and quality of generated visual content. Additionally, we employ the explicit viewpoint modeling in multi-view video generation to effectively improve motion transition consistency. Capable of handling various input reference formats (e.g., text, images, or video), our UniMLVG generates high-quality multi-view videos according to the corresponding condition constraints such as 3D bounding boxes or frame-level text descriptions. Compared to the best models with similar capabilities, our framework achieves improvements of 21.4% in FID and 36.5% in FVD.
HoloDrive: Holistic 2D-3D Multi-Modal Street Scene Generation for Autonomous Driving
Dec 03, 2024



Generative models have significantly improved the generation and prediction quality on either camera images or LiDAR point clouds for autonomous driving. However, a real-world autonomous driving system uses multiple kinds of input modality, usually cameras and LiDARs, where they contain complementary information for generation, while existing generation methods ignore this crucial feature, resulting in the generated results only covering separate 2D or 3D information. In order to fill the gap in 2D-3D multi-modal joint generation for autonomous driving, in this paper, we propose our framework, \emph{HoloDrive}, to jointly generate the camera images and LiDAR point clouds. We employ BEV-to-Camera and Camera-to-BEV transform modules between heterogeneous generative models, and introduce a depth prediction branch in the 2D generative model to disambiguate the un-projecting from image space to BEV space, then extend the method to predict the future by adding temporal structure and carefully designed progressive training. Further, we conduct experiments on single frame generation and world model benchmarks, and demonstrate our method leads to significant performance gains over SOTA methods in terms of generation metrics.