 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robotic Dexterous Hand Intelligence: A Survey
May 13, 2026Robotic dexterous hands are central to contact-rich manipulation, with rapid progress driven by advances in hardware, sensing, control, simulation, and data generation. However, existing studies are often developed under different assumptions regarding hand embodiments, sensory configurations, task settings, training data, and evaluation protocols, making systematic comparison difficult and obscuring the developmental trajectory of the field. This survey provides a holistic review of dexterous hand research from four complementary aspects. First, we present a hardware-level analysis covering actuation, transmission, perception, and representative hand designs, highlighting the key trade-offs in force capability, compliance, bandwidth, integration, and system complexity. Furthermore, we review control and learning methods for dexterous manipulation from a methodological perspective, grouping representative works by major paradigms and tracing their evolution in chronological order. In addition, we consolidate datasets, modality design, and evaluation practices, which enables methodological progress to be interpreted together with the ways in which it is trained, benchmarked, and assessed. Finally, we discuss the major limitations of current dexterous hand research and summarize the corresponding future directions. By connecting hardware analysis, methodological development, data resources, and evaluation, this survey aims to provide a structured understanding of dexterous hand research and to clarify the most important open challenges for future study.
Rectified Schrödinger Bridge Matching for Few-Step Visual Navigation
Apr 07, 2026Visual navigation is a core challenge in Embodied AI, requiring autonomous agents to translate high-dimensional sensory observations into continuous, long-horizon action trajectories. While generative policies based on diffusion models and Schrödinger Bridges (SB) effectively capture multimodal action distributions, they require dozens of integration steps due to high-variance stochastic transport, posing a critical barrier for real-time robotic control. We propose Rectified Schrödinger Bridge Matching (RSBM), a framework that exploits a shared velocity-field structure between standard Schrödinger Bridges ($\varepsilon=1$, maximum-entropy transport) and deterministic Optimal Transport ($\varepsilon\to 0$, as in Conditional Flow Matching), controlled by a single entropic regularization parameter $\varepsilon$. We prove two key results: (1) the conditional velocity field's functional form is invariant across the entire $\varepsilon$-spectrum (Velocity Structure Invariance), enabling a single network to serve all regularization strengths; and (2) reducing $\varepsilon$ linearly decreases the conditional velocity variance, enabling more stable coarse-step ODE integration. Anchored to a learned conditional prior that shortens transport distance, RSBM operates at an intermediate $\varepsilon$ that balances multimodal coverage and path straightness. Empirically, while standard bridges require $\geq 10$ steps to converge, RSBM achieves over 94% cosine similarity and 92% success rate in merely 3 integration steps -- without distillation or multi-stage training -- substantially narrowing the gap between high-fidelity generative policies and the low-latency demands of Embodied AI.
SnapFlow: One-Step Action Generation for Flow-Matching VLAs via Progressive Self-Distillation
Apr 07, 2026Vision-Language-Action (VLA) models based on flow matching -- such as pi0, pi0.5, and SmolVLA -- achieve state-of-the-art generalist robotic manipulation, yet their iterative denoising, typically 10 ODE steps, introduces substantial latency: on a modern GPU, denoising alone accounts for 80% of end-to-end inference time. Naively reducing the step count is unreliable, degrading success on most tasks due to the velocity field being uncalibrated for single-step jumps. We present SnapFlow, a plug-and-play self-distillation method that compresses multi-step denoising into a single forward pass (1-NFE) for flow-matching VLAs. SnapFlow mixes standard flow-matching samples with consistency samples whose targets are two-step Euler shortcut velocities computed from the model's own marginal velocity predictions, avoiding the trajectory drift caused by conditional velocities, as we analyze theoretically. A zero-initialized target-time embedding lets the network switch between local velocity estimation and global one-step generation within a single architecture. SnapFlow requires no external teacher, no architecture changes, and trains in ~12h on a single GPU. We validate on two VLA architectures spanning a 6x parameter range, with identical hyperparameters: on pi0.5 (3B) across four LIBERO suites (40 tasks, 400 episodes), SnapFlow achieves 98.75% average success -- matching the 10-step teacher at 97.75% and slightly exceeding it -- with 9.6x denoising speedup and end-to-end latency reduced from 274ms to 83ms; on SmolVLA (500M), it reduces MSE by 8.3% with 3.56x end-to-end acceleration. An action-step sweep on long-horizon tasks reveals that SnapFlow maintains its advantage across execution horizons, achieving 93% at n_act=5 where the baseline reaches only 90%. SnapFlow is orthogonal to layer-distillation and token-pruning approaches, enabling compositional speedups.
Tele-Catch: Adaptive Teleoperation for Dexterous Dynamic 3D Object Catching
Mar 30, 2026Teleoperation is a key paradigm for transferring human dexterity to robots, yet most prior work targets objects that are initially static, such as grasping or manipulation. Dynamic object catch, where objects move before contact, remains underexplored. Pure teleoperation in this task often fails due to timing, pose, and force errors, highlighting the need for shared autonomy that combines human input with autonomous policies. To this end, we present Tele-Catch, a systematic framework for dexterous hand teleoperation in dynamic object catching. At its core, we design DAIM, a dynamics-aware adaptive integration mechanism that realizes shared autonomy by fusing glove-based teleoperation signals into the diffusion policy denoising process. It adaptively modulates control based on the interaction object state. To improve policy robustness, we introduce DP-U3R, which integrates unsupervised geometric representations from point cloud observations into diffusion policy learning, enabling geometry-aware decision making. Extensive experiments demonstrate that Tele-Catch significantly improves accuracy and robustness in dynamic catching tasks, while also exhibiting consistent gains across distinct dexterous hand embodiments and previously unseen object categories.
TrajVG: 3D Trajectory-Coupled Visual Geometry Learning
Feb 05, 2026Feed-forward multi-frame 3D reconstruction models often degrade on videos with object motion. Global-reference becomes ambiguous under multiple motions, while the local pointmap relies heavily on estimated relative poses and can drift, causing cross-frame misalignment and duplicated structures. We propose TrajVG, a reconstruction framework that makes cross-frame 3D correspondence an explicit prediction by estimating camera-coordinate 3D trajectories. We couple sparse trajectories, per-frame local point maps, and relative camera poses with geometric consistency objectives: (i) bidirectional trajectory-pointmap consistency with controlled gradient flow, and (ii) a pose consistency objective driven by static track anchors that suppresses gradients from dynamic regions. To scale training to in-the-wild videos where 3D trajectory labels are scarce, we reformulate the same coupling constraints into self-supervised objectives using only pseudo 2D tracks, enabling unified training with mixed supervision. Extensive experiments across 3D tracking, pose estimation, pointmap reconstruction, and video depth show that TrajVG surpasses the current feedforward performance baseline.
SynthVerse: A Large-Scale Diverse Synthetic Dataset for Point Tracking
Feb 04, 2026Point tracking aims to follow visual points through complex motion, occlusion, and viewpoint changes, and has advanced rapidly with modern foundation models. Yet progress toward general point tracking remains constrained by limited high-quality data, as existing datasets often provide insufficient diversity and imperfect trajectory annotations. To this end, we introduce SynthVerse, a large-scale, diverse synthetic dataset specifically designed for point tracking. SynthVerse includes several new domains and object types missing from existing synthetic datasets, such as animated-film-style content, embodied manipulation, scene navigation, and articulated objects. SynthVerse substantially expands dataset diversity by covering a broader range of object categories and providing high-quality dynamic motions and interactions, enabling more robust training and evaluation for general point tracking. In addition, we establish a highly diverse point tracking benchmark to systematically evaluate state-of-the-art methods under broader domain shifts. Extensive experiments and analyses demonstrate that training with SynthVerse yields consistent improvements in generalization and reveal limitations of existing trackers under diverse settings.
Unlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Mar 17, 2025Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.
BFANet: Revisiting 3D Semantic Segmentation with Boundary Feature Analysis
Mar 16, 2025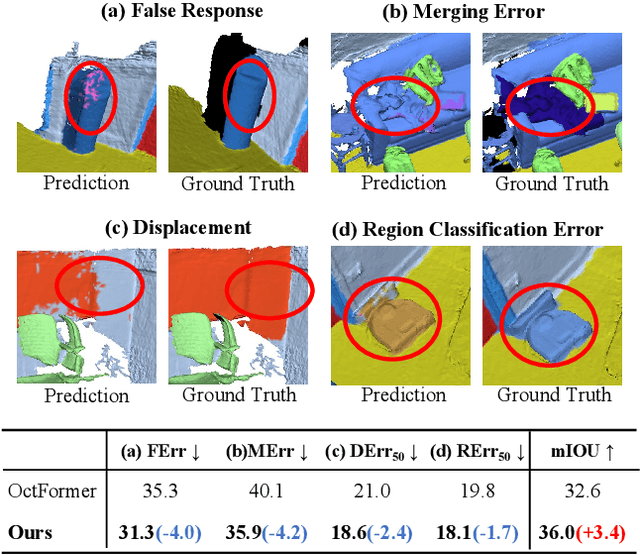


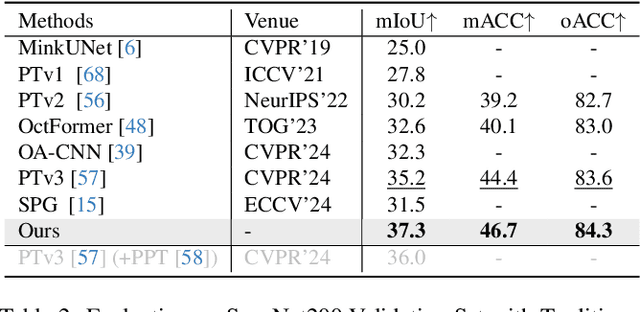
3D semantic segmentation plays a fundamental and crucial role to understand 3D scenes. While contemporary state-of-the-art techniques predominantly concentrate on elevating the overall performance of 3D semantic segmentation based on general metrics (e.g. mIoU, mAcc, and oAcc), they unfortunately leave the exploration of challenging regions for segmentation mostly neglected. In this paper, we revisit 3D semantic segmentation through a more granular lens, shedding light on subtle complexities that are typically overshadowed by broader performance metrics. Concretely, we have delineated 3D semantic segmentation errors into four comprehensive categories as well as corresponding evaluation metrics tailored to each. Building upon this categorical framework, we introduce an innovative 3D semantic segmentation network called BFANet that incorporates detailed analysis of semantic boundary features. First, we design the boundary-semantic module to decouple point cloud features into semantic and boundary features, and fuse their query queue to enhance semantic features with attention. Second, we introduce a more concise and accelerated boundary pseudo-label calculation algorithm, which is 3.9 times faster than the state-of-the-art, offering compatibility with data augmentation and enabling efficient computation in training. Extensive experiments on benchmark data indicate the superiority of our BFANet model, confirming the significance of emphasizing the four uniquely designed metrics. Code is available at https://github.com/weiguangzhao/BFANet.
Efficient Interactive 3D Multi-Object Removal
Jan 30, 2025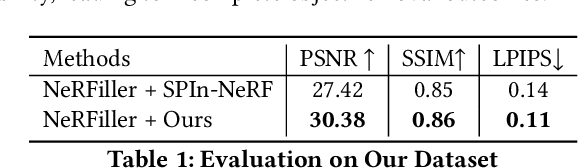
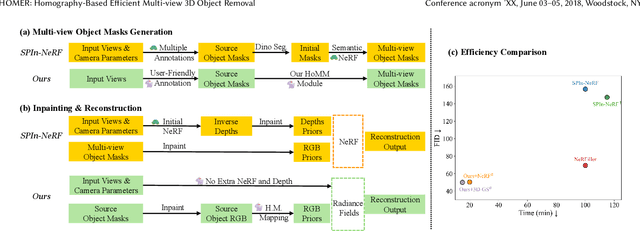
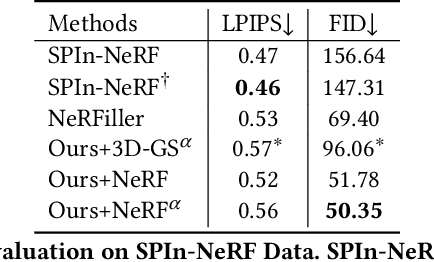
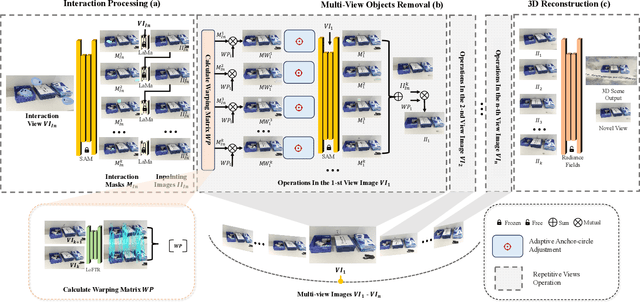
Object removal is of great significance to 3D scene understanding, essential for applications in content filtering and scene editing. Current mainstream methods primarily focus on removing individual objects, with a few methods dedicated to eliminating an entire area or all objects of a certain category. They however confront the challenge of insufficient granularity and flexibility for real-world applications, where users demand tailored excision and preservation of objects within defined zones. In addition, most of the current methods require kinds of priors when addressing multi-view inpainting, which is time-consuming. To address these limitations, we propose an efficient and user-friendly pipeline for 3D multi-object removal, enabling users to flexibly select areas and define objects for removal or preservation. Concretely, to ensure object consistency and correspondence across multiple views, we propose a novel mask matching and refinement module, which integrates homography-based warping with high-confidence anchor points for segmentation. By leveraging the IoU joint shape context distance loss, we enhance the accuracy of warped masks and improve subsequent inpainting processes. Considering the current immaturity of 3D multi-object removal, we provide a new evaluation dataset to bridge the developmental void. Experimental results demonstrate that our method significantly reduces computational costs, achieving processing speeds more than 80% faster than state-of-the-art methods while maintaining equivalent or higher reconstruction quality.
Towards Training-Free Open-World Classification with 3D Generative Models
Jan 29, 2025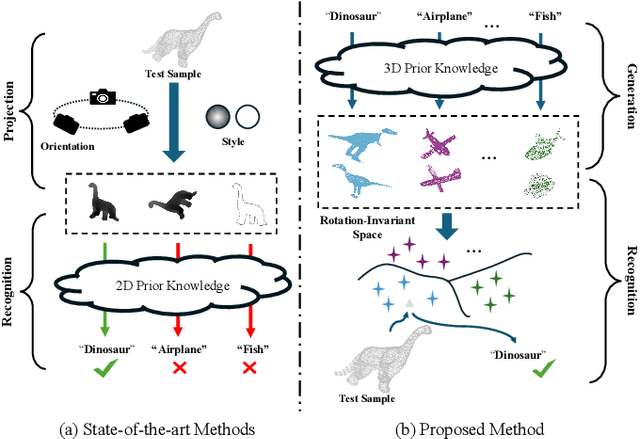
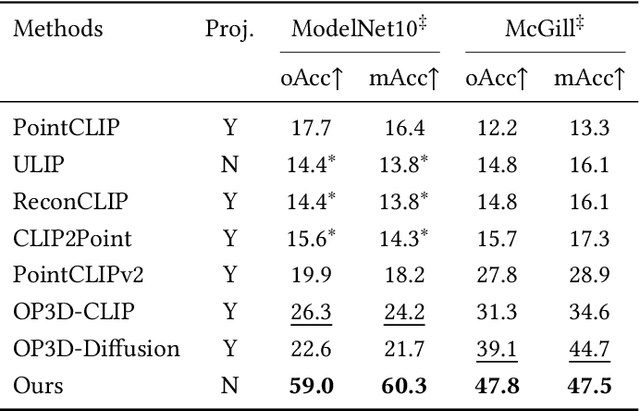
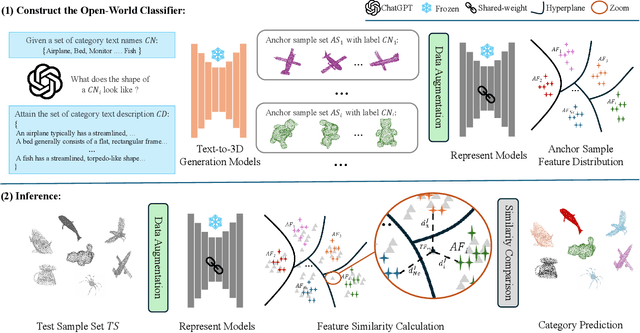

3D open-world classification is a challenging yet essential task in dynamic and unstructured real-world scenarios, requiring both open-category and open-pose recognition. To address these challenges, recent wisdom often takes sophisticated 2D pre-trained models to provide enriched and stable representations. However, these methods largely rely on how 3D objects can be projected into 2D space, which is unfortunately not well solved, and thus significantly limits their performance. Unlike these present efforts, in this paper we make a pioneering exploration of 3D generative models for 3D open-world classification. Drawing on abundant prior knowledge from 3D generative models, we additionally craft a rotation-invariant feature extractor. This innovative synergy endows our pipeline with the advantages of being training-free, open-category, and pose-invariant, thus well suited to 3D open-world classification. Extensive experiments on benchmark datasets demonstrate the potential of generative models in 3D open-world classification, achieving state-of-the-art performance on ModelNet10 and McGill with 32.0% and 8.7% overall accuracy improvement, respectively.