 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAST: Gradient-aligned Sparse Tuning of Large Language Models with Data-layer Selection
Mar 10, 2026Parameter-Efficient Fine-Tuning (PEFT) has become a key strategy for adapting large language models, with recent advances in sparse tuning reducing overhead by selectively updating key parameters or subsets of data. Existing approaches generally focus on two distinct paradigms: layer-selective methods aiming to fine-tune critical layers to minimize computational load, and data-selective methods aiming to select effective training subsets to boost training. However, current methods typically overlook the fact that different data points contribute varying degrees to distinct model layers, and they often discard potentially valuable information from data perceived as of low quality. To address these limitations, we propose Gradient-aligned Sparse Tuning (GAST), an innovative method that simultaneously performs selective fine-tuning at both data and layer dimensions as integral components of a unified optimization strategy. GAST specifically targets redundancy in information by employing a layer-sparse strategy that adaptively selects the most impactful data points for each layer, providing a more comprehensive and sophisticated solution than approaches restricted to a single dimension. Experiments demonstrate that GAST consistently outperforms baseline methods, establishing a promising direction for future research in PEFT strategies.
Smudged Fingerprints: A Systematic Evaluation of the Robustness of AI Image Fingerprints
Dec 12, 2025Model fingerprint detection techniques have emerged as a promising approach for attributing AI-generated images to their source models, but their robustness under adversarial conditions remains largely unexplored. We present the first systematic security evaluation of these techniques, formalizing threat models that encompass both white- and black-box access and two attack goals: fingerprint removal, which erases identifying traces to evade attribution, and fingerprint forgery, which seeks to cause misattribution to a target model. We implement five attack strategies and evaluate 14 representative fingerprinting methods across RGB, frequency, and learned-feature domains on 12 state-of-the-art image generators. Our experiments reveal a pronounced gap between clean and adversarial performance. Removal attacks are highly effective, often achieving success rates above 80% in white-box settings and over 50% under constrained black-box access. While forgery is more challenging than removal, its success significantly varies across targeted models. We also identify a utility-robustness trade-off: methods with the highest attribution accuracy are often vulnerable to attacks. Although some techniques exhibit robustness in specific settings, none achieves high robustness and accuracy across all evaluated threat models. These findings highlight the need for techniques balancing robustness and accuracy, and identify the most promising approaches for advancing this goal.
Towards Instance-wise Personalized Federated Learning via Semi-Implicit Bayesian Prompt Tuning
Aug 27, 2025Federated learning (FL) is a privacy-preserving machine learning paradigm that enables collaborative model training across multiple distributed clients without disclosing their raw data. Personalized federated learning (pFL) has gained increasing attention for its ability to address data heterogeneity. However, most existing pFL methods assume that each client's data follows a single distribution and learn one client-level personalized model for each client. This assumption often fails in practice, where a single client may possess data from multiple sources or domains, resulting in significant intra-client heterogeneity and suboptimal performance. To tackle this challenge, we propose pFedBayesPT, a fine-grained instance-wise pFL framework based on visual prompt tuning. Specifically, we formulate instance-wise prompt generation from a Bayesian perspective and model the prompt posterior as an implicit distribution to capture diverse visual semantics. We derive a variational training objective under the semi-implicit variational inference framework. Extensive experiments on benchmark datasets demonstrate that pFedBayesPT consistently outperforms existing pFL methods under both feature and label heterogeneity settings.
Exploiting Layer Normalization Fine-tuning in Visual Transformer Foundation Models for Classification
Aug 11, 2025LayerNorm is pivotal in Vision Transformers (ViTs), yet its fine-tuning dynamics under data scarcity and domain shifts remain underexplored. This paper shows that shifts in LayerNorm parameters after fine-tuning (LayerNorm shifts) are indicative of the transitions between source and target domains; its efficacy is contingent upon the degree to which the target training samples accurately represent the target domain, as quantified by our proposed Fine-tuning Shift Ratio ($FSR$). Building on this, we propose a simple yet effective rescaling mechanism using a scalar $\lambda$ that is negatively correlated to $FSR$ to align learned LayerNorm shifts with those ideal shifts achieved under fully representative data, combined with a cyclic framework that further enhances the LayerNorm fine-tuning. Extensive experiments across natural and pathological images, in both in-distribution (ID) and out-of-distribution (OOD) settings, and various target training sample regimes validate our framework. Notably, OOD tasks tend to yield lower $FSR$ and higher $\lambda$ in comparison to ID cases, especially with scarce data, indicating under-represented target training samples. Moreover, ViTFs fine-tuned on pathological data behave more like ID settings, favoring conservative LayerNorm updates. Our findings illuminate the underexplored dynamics of LayerNorm in transfer learning and provide practical strategies for LayerNorm fine-tuning.
Unlock Pose Diversity: Accurate and Efficient Implicit Keypoint-based Spatiotemporal Diffusion for Audio-driven Talking Portrait
Mar 17, 2025Audio-driven single-image talking portrait generation plays a crucial role in virtual reality, digital human creation, and filmmaking. Existing approaches are generally categorized into keypoint-based and image-based methods. Keypoint-based methods effectively preserve character identity but struggle to capture fine facial details due to the fixed points limitation of the 3D Morphable Model. Moreover, traditional generative networks face challenges in establishing causality between audio and keypoints on limited datasets, resulting in low pose diversity. In contrast, image-based approaches produce high-quality portraits with diverse details using the diffusion network but incur identity distortion and expensive computational costs. In this work, we propose KDTalker, the first framework to combine unsupervised implicit 3D keypoint with a spatiotemporal diffusion model. Leveraging unsupervised implicit 3D keypoints, KDTalker adapts facial information densities, allowing the diffusion process to model diverse head poses and capture fine facial details flexibly. The custom-designed spatiotemporal attention mechanism ensures accurate lip synchronization, producing temporally consistent, high-quality animations while enhancing computational efficiency. Experimental results demonstrate that KDTalker achieves state-of-the-art performance regarding lip synchronization accuracy, head pose diversity, and execution efficiency.Our codes are available at https://github.com/chaolongy/KDTalker.
SoK: What Makes Private Learning Unfair?
Jan 24, 2025Differential privacy has emerged as the most studied framework for privacy-preserving machine learning. However, recent studies show that enforcing differential privacy guarantees can not only significantly degrade the utility of the model, but also amplify existing disparities in its predictive performance across demographic groups. Although there is extensive research on the identification of factors that contribute to this phenomenon, we still lack a complete understanding of the mechanisms through which differential privacy exacerbates disparities. The literature on this problem is muddled by varying definitions of fairness, differential privacy mechanisms, and inconsistent experimental settings, often leading to seemingly contradictory results. This survey provides the first comprehensive overview of the factors that contribute to the disparate effect of training models with differential privacy guarantees. We discuss their impact and analyze their causal role in such a disparate effect. Our analysis is guided by a taxonomy that categorizes these factors by their position within the machine learning pipeline, allowing us to draw conclusions about their interaction and the feasibility of potential mitigation strategies. We find that factors related to the training dataset and the underlying distribution play a decisive role in the occurrence of disparate impact, highlighting the need for research on these factors to address the issue.
ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression
Dec 13, 2024Offsite-tuning is a privacy-preserving method for tuning large language models (LLMs) by sharing a lossy compressed emulator from the LLM owners with data owners for downstream task tuning. This approach protects the privacy of both the model and data owners. However, current offsite tuning methods often suffer from adaptation degradation, high computational costs, and limited protection strength due to uniformly dropping LLM layers or relying on expensive knowledge distillation. To address these issues, we propose ScaleOT, a novel privacy-utility-scalable offsite-tuning framework that effectively balances privacy and utility. ScaleOT introduces a novel layerwise lossy compression algorithm that uses reinforcement learning to obtain the importance of each layer. It employs lightweight networks, termed harmonizers, to replace the raw LLM layers. By combining important original LLM layers and harmonizers in different ratios, ScaleOT generates emulators tailored for optimal performance with various model scales for enhanced privacy protection. Additionally, we present a rank reduction method to further compress the original LLM layers, significantly enhancing privacy with negligible impact on utility. Comprehensive experiments show that ScaleOT can achieve nearly lossless offsite tuning performance compared with full fine-tuning while obtaining better model privacy.
Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models
Oct 15, 2024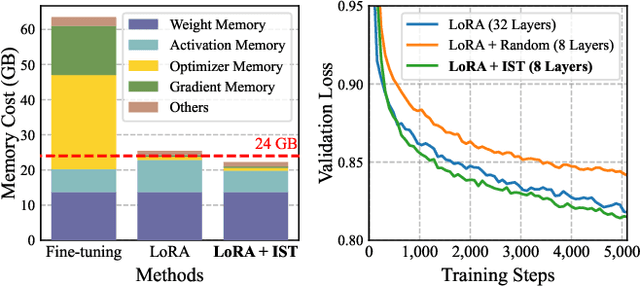
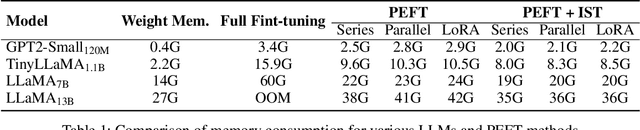
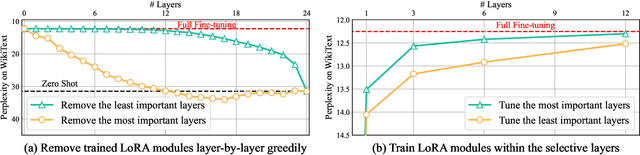
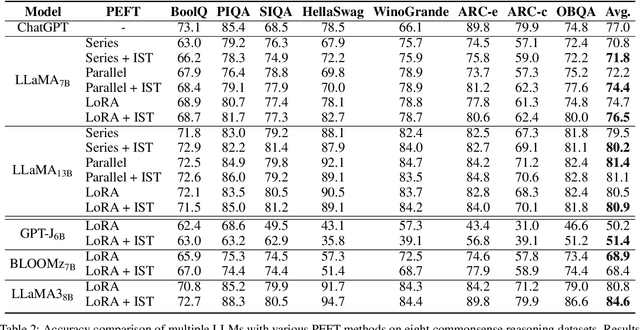
Parameter-Efficient Fine-Tuning (PEFT) methods have gained significant popularity for adapting pre-trained Large Language Models (LLMs) to downstream tasks, primarily due to their potential to significantly reduce memory and computational overheads. However, a common limitation in most PEFT approaches is their application of a uniform architectural design across all layers. This uniformity involves identical trainable modules and ignores the varying importance of each layer, leading to sub-optimal fine-tuning results. To overcome the above limitation and obtain better performance, we develop a novel approach, Importance-aware Sparse Tuning (IST), to fully utilize the inherent sparsity and select the most important subset of full layers with effective layer-wise importance scoring. The proposed IST is a versatile and plug-and-play technique compatible with various PEFT methods that operate on a per-layer basis. By leveraging the estimated importance scores, IST dynamically updates these selected layers in PEFT modules, leading to reduced memory demands. We further provide theoretical proof of convergence and empirical evidence of superior performance to demonstrate the advantages of IST over uniform updating strategies. Extensive experiments on a range of LLMs, PEFTs, and downstream tasks substantiate the effectiveness of our proposed method, showcasing IST's capacity to enhance existing layer-based PEFT methods. Our code is available at https://github.com/Kaiseem/IST.
OPa-Ma: Text Guided Mamba for 360-degree Image Out-painting
Jul 15, 2024In this paper, we tackle the recently popular topic of generating 360-degree images given the conventional narrow field of view (NFoV) images that could be taken from a single camera or cellphone. This task aims to predict the reasonable and consistent surroundings from the NFoV images. Existing methods for feature extraction and fusion, often built with transformer-based architectures, incur substantial memory usage and computational expense. They also have limitations in maintaining visual continuity across the entire 360-degree images, which could cause inconsistent texture and style generation. To solve the aforementioned issues, we propose a novel text-guided out-painting framework equipped with a State-Space Model called Mamba to utilize its long-sequence modelling and spatial continuity. Furthermore, incorporating textual information is an effective strategy for guiding image generation, enriching the process with detailed context and increasing diversity. Efficiently extracting textual features and integrating them with image attributes presents a significant challenge for 360-degree image out-painting. To address this, we develop two modules, Visual-textual Consistency Refiner (VCR) and Global-local Mamba Adapter (GMA). VCR enhances contextual richness by fusing the modified text features with the image features, while GMA provides adaptive state-selective conditions by capturing the information flow from global to local representations. Our proposed method achieves state-of-the-art performance with extensive experiments on two broadly used 360-degree image datasets, including indoor and outdoor settings.
SCMix: Stochastic Compound Mixing for Open Compound Domain Adaptation in Semantic Segmentation
May 23, 2024Open compound domain adaptation (OCDA) aims to transfer knowledge from a labeled source domain to a mix of unlabeled homogeneous compound target domains while generalizing to open unseen domains. Existing OCDA methods solve the intra-domain gaps by a divide-and-conquer strategy, which divides the problem into several individual and parallel domain adaptation (DA) tasks. Such approaches often contain multiple sub-networks or stages, which may constrain the model's performance. In this work, starting from the general DA theory, we establish the generalization bound for the setting of OCDA. Built upon this, we argue that conventional OCDA approaches may substantially underestimate the inherent variance inside the compound target domains for model generalization. We subsequently present Stochastic Compound Mixing (SCMix), an augmentation strategy with the primary objective of mitigating the divergence between source and mixed target distributions. We provide theoretical analysis to substantiate the superiority of SCMix and prove that the previous methods are sub-groups of our methods. Extensive experiments show that our method attains a lower empirical risk on OCDA semantic segmentation tasks, thus supporting our theories. Combining the transformer architecture, SCMix achieves a notable performance boost compared to the SoTA results.