 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Adapter for Cross-modal Similarity Representation
May 29, 2026The core of vision-language models lies in measuring cross-modal similarity within a unified representation space. However, most image-text matching or multi-class image classification datasets lack fine-grained cross-modal matching annotations, forcing the continuous similarity space into binary classification boundaries. This compression induces false negative samples and significantly impairs the generalization performance of cross-modal tasks. While prior research has attempted to mitigate this by modeling intra-modal ambiguity, it often overlooks inherent annotation flaws, leading to suboptimal uncertainty allocation. To address these challenges, we propose a Variational Adapter for Cross-modal Similarity Representation (VACSR). This approach reformulates image-text matching with fine-grained semantic scarcity as a variational inference problem. It constructs a latent space for cross-modal similarity and uses regularization techniques to mitigate overfitting to binary annotations. Experiments on image-text retrieval, domain generalization, and base-to-novel generalization demonstrate the proposed method's effectiveness and robust generalization ability.
Towards Instance-wise Personalized Federated Learning via Semi-Implicit Bayesian Prompt Tuning
Aug 27, 2025Federated learning (FL) is a privacy-preserving machine learning paradigm that enables collaborative model training across multiple distributed clients without disclosing their raw data. Personalized federated learning (pFL) has gained increasing attention for its ability to address data heterogeneity. However, most existing pFL methods assume that each client's data follows a single distribution and learn one client-level personalized model for each client. This assumption often fails in practice, where a single client may possess data from multiple sources or domains, resulting in significant intra-client heterogeneity and suboptimal performance. To tackle this challenge, we propose pFedBayesPT, a fine-grained instance-wise pFL framework based on visual prompt tuning. Specifically, we formulate instance-wise prompt generation from a Bayesian perspective and model the prompt posterior as an implicit distribution to capture diverse visual semantics. We derive a variational training objective under the semi-implicit variational inference framework. Extensive experiments on benchmark datasets demonstrate that pFedBayesPT consistently outperforms existing pFL methods under both feature and label heterogeneity settings.
ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression
Dec 13, 2024Offsite-tuning is a privacy-preserving method for tuning large language models (LLMs) by sharing a lossy compressed emulator from the LLM owners with data owners for downstream task tuning. This approach protects the privacy of both the model and data owners. However, current offsite tuning methods often suffer from adaptation degradation, high computational costs, and limited protection strength due to uniformly dropping LLM layers or relying on expensive knowledge distillation. To address these issues, we propose ScaleOT, a novel privacy-utility-scalable offsite-tuning framework that effectively balances privacy and utility. ScaleOT introduces a novel layerwise lossy compression algorithm that uses reinforcement learning to obtain the importance of each layer. It employs lightweight networks, termed harmonizers, to replace the raw LLM layers. By combining important original LLM layers and harmonizers in different ratios, ScaleOT generates emulators tailored for optimal performance with various model scales for enhanced privacy protection. Additionally, we present a rank reduction method to further compress the original LLM layers, significantly enhancing privacy with negligible impact on utility. Comprehensive experiments show that ScaleOT can achieve nearly lossless offsite tuning performance compared with full fine-tuning while obtaining better model privacy.
OPa-Ma: Text Guided Mamba for 360-degree Image Out-painting
Jul 15, 2024In this paper, we tackle the recently popular topic of generating 360-degree images given the conventional narrow field of view (NFoV) images that could be taken from a single camera or cellphone. This task aims to predict the reasonable and consistent surroundings from the NFoV images. Existing methods for feature extraction and fusion, often built with transformer-based architectures, incur substantial memory usage and computational expense. They also have limitations in maintaining visual continuity across the entire 360-degree images, which could cause inconsistent texture and style generation. To solve the aforementioned issues, we propose a novel text-guided out-painting framework equipped with a State-Space Model called Mamba to utilize its long-sequence modelling and spatial continuity. Furthermore, incorporating textual information is an effective strategy for guiding image generation, enriching the process with detailed context and increasing diversity. Efficiently extracting textual features and integrating them with image attributes presents a significant challenge for 360-degree image out-painting. To address this, we develop two modules, Visual-textual Consistency Refiner (VCR) and Global-local Mamba Adapter (GMA). VCR enhances contextual richness by fusing the modified text features with the image features, while GMA provides adaptive state-selective conditions by capturing the information flow from global to local representations. Our proposed method achieves state-of-the-art performance with extensive experiments on two broadly used 360-degree image datasets, including indoor and outdoor settings.
Federated Learning via Consensus Mechanism on Heterogeneous Data: A New Perspective on Convergence
Nov 21, 2023Federated learning (FL) on heterogeneous data (non-IID data) has recently received great attention. Most existing methods focus on studying the convergence guarantees for the global objective. While these methods can guarantee the decrease of the global objective in each communication round, they fail to ensure risk decrease for each client. In this paper, to address the problem,we propose FedCOME, which introduces a consensus mechanism to enforce decreased risk for each client after each training round. In particular, we allow a slight adjustment to a client's gradient on the server side, which generates an acute angle between the corrected gradient and the original ones of other clients. We theoretically show that the consensus mechanism can guarantee the convergence of the global objective. To generalize the consensus mechanism to the partial participation FL scenario, we devise a novel client sampling strategy to select the most representative clients for the global data distribution. Training on these selected clients with the consensus mechanism could empirically lead to risk decrease for clients that are not selected. Finally, we conduct extensive experiments on four benchmark datasets to show the superiority of FedCOME against other state-of-the-art methods in terms of effectiveness, efficiency and fairness. For reproducibility, we make our source code publicly available at: \url{https://github.com/fedcome/fedcome}.
You Can Backdoor Personalized Federated Learning
Jul 29, 2023Backdoor attacks pose a significant threat to the security of federated learning systems. However, existing research primarily focuses on backdoor attacks and defenses within the generic FL scenario, where all clients collaborate to train a single global model. \citet{qin2023revisiting} conduct the first study of backdoor attacks in the personalized federated learning (pFL) scenario, where each client constructs a personalized model based on its local data. Notably, the study demonstrates that pFL methods with partial model-sharing can significantly boost robustness against backdoor attacks. In this paper, we whistleblow that pFL methods with partial model-sharing are still vulnerable to backdoor attacks in the absence of any defense. We propose three backdoor attack methods: BapFL, BapFL+, and Gen-BapFL, and we empirically demonstrate that they can effectively attack the pFL methods. Specifically, the key principle of BapFL lies in maintaining clean local parameters while implanting the backdoor into the global parameters. BapFL+ generalizes the attack success to benign clients by introducing Gaussian noise to the local parameters. Furthermore, we assume the collaboration of malicious clients and propose Gen-BapFL, which leverages meta-learning techniques to further enhances attack generalization. We evaluate our proposed attack methods against two classic pFL methods with partial model-sharing, FedPer and LG-FedAvg. Extensive experiments on four FL benchmark datasets demonstrate the effectiveness of our proposed attack methods. Additionally, we assess the defense efficacy of various defense strategies against our proposed attacks and find that Gradient Norm-Clipping is particularly effective. It is crucial to note that pFL method is not always secure in the presence of backdoor attacks, and we hope to inspire further research on attack and defense in pFL scenarios.
UPFL: Unsupervised Personalized Federated Learning towards New Clients
Jul 29, 2023



Personalized federated learning has gained significant attention as a promising approach to address the challenge of data heterogeneity. In this paper, we address a relatively unexplored problem in federated learning. When a federated model has been trained and deployed, and an unlabeled new client joins, providing a personalized model for the new client becomes a highly challenging task. To address this challenge, we extend the adaptive risk minimization technique into the unsupervised personalized federated learning setting and propose our method, FedTTA. We further improve FedTTA with two simple yet effective optimization strategies: enhancing the training of the adaptation model with proxy regularization and early-stopping the adaptation through entropy. Moreover, we propose a knowledge distillation loss specifically designed for FedTTA to address the device heterogeneity. Extensive experiments on five datasets against eleven baselines demonstrate the effectiveness of our proposed FedTTA and its variants. The code is available at: https://github.com/anonymous-federated-learning/code.
SeeGera: Self-supervised Semi-implicit Graph Variational Auto-encoders with Masking
Feb 07, 2023



Generative graph self-supervised learning (SSL) aims to learn node representations by reconstructing the input graph data. However, most existing methods focus on unsupervised learning tasks only and very few work has shown its superiority over the state-of-the-art graph contrastive learning (GCL) models, especially on the classification task. While a very recent model has been proposed to bridge the gap, its performance on unsupervised learning tasks is still unknown. In this paper, to comprehensively enhance the performance of generative graph SSL against other GCL models on both unsupervised and supervised learning tasks, we propose the SeeGera model, which is based on the family of self-supervised variational graph auto-encoder (VGAE). Specifically, SeeGera adopts the semi-implicit variational inference framework, a hierarchical variational framework, and mainly focuses on feature reconstruction and structure/feature masking. On the one hand, SeeGera co-embeds both nodes and features in the encoder and reconstructs both links and features in the decoder. Since feature embeddings contain rich semantic information on features, they can be combined with node embeddings to provide fine-grained knowledge for feature reconstruction. On the other hand, SeeGera adds an additional layer for structure/feature masking to the hierarchical variational framework, which boosts the model generalizability. We conduct extensive experiments comparing SeeGera with 9 other state-of-the-art competitors. Our results show that SeeGera can compare favorably against other state-of-the-art GCL methods in a variety of unsupervised and supervised learning tasks.
Practical and Light-weight Secure Aggregation for Federated Submodel Learning
Nov 02, 2021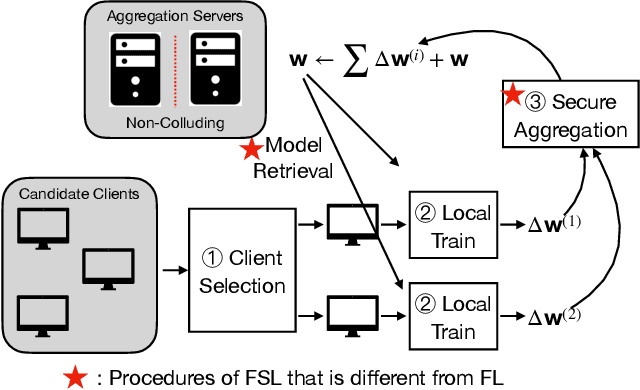
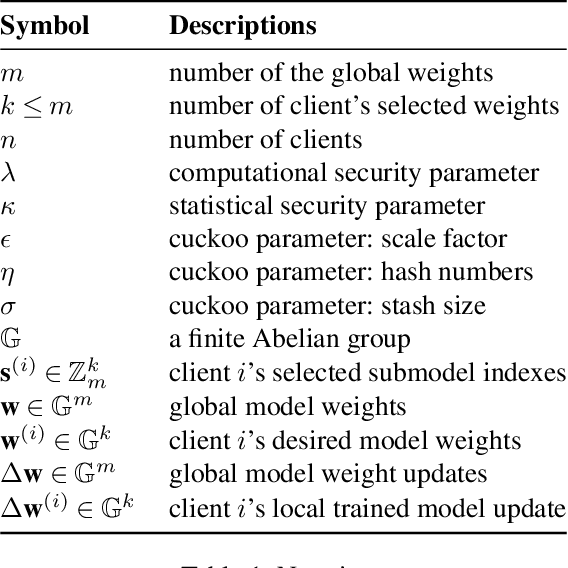
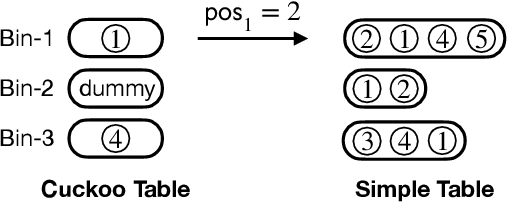

Recently, Niu, et. al. introduced a new variant of Federated Learning (FL), called Federated Submodel Learning (FSL). Different from traditional FL, each client locally trains the submodel (e.g., retrieved from the servers) based on its private data and uploads a submodel at its choice to the servers. Then all clients aggregate all their submodels and finish the iteration. Inevitably, FSL introduces two privacy-preserving computation tasks, i.e., Private Submodel Retrieval (PSR) and Secure Submodel Aggregation (SSA). Existing work fails to provide a loss-less scheme, or has impractical efficiency. In this work, we leverage Distributed Point Function (DPF) and cuckoo hashing to construct a practical and light-weight secure FSL scheme in the two-server setting. More specifically, we propose two basic protocols with few optimisation techniques, which ensures our protocol practicality on specific real-world FSL tasks. Our experiments show that our proposed protocols can finish in less than 1 minute when weight sizes $\leq 2^{15}$, we also demonstrate protocol efficiency by comparing with existing work and by handling a real-world FSL task.