 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptSeg-R1: Segment Any Concept via Meta-Reinforcement Learning
May 19, 2026Recent progress in promptable segmentation has shifted visual perception from object-level localization toward concept-level understanding. However, the notion of a concept remains under-specified, making it unclear whether current methods truly generalize beyond category recognition. In this work, we formalize generalized concept segmentation through a three-level taxonomy consisting of context-independent (CI), context-dependent (CD), and context-reasoning (CR) concepts, which reveals a clear capability gap across increasing levels of cognitive complexity. To address this challenge, we propose ConceptSeg-R1, a unified framework that reformulates concept segmentation as rule-induced concept grounding. At the core of our method is Meta-GRPO, a meta-reinforcement learning mechanism that learns transferable task rules from visual demonstrations and verifies them through proxy reasoning. The inferred reasoning states are then translated into segmentation-ready concept prompts via a lightweight concept translation module, enabling deductive application to target images. A shortcut routing strategy further preserves the native efficiency of segmentation models on simple cases. To systematically evaluate generalized concept segmentation, we conduct extensive experiments across diverse CI, CD, and CR concept segmentation benchmarks spanning natural, industrial, medical and reasoning-intensive domains. Without bells and whistles, ConceptSeg-R1 achieves strong performance across the full concept hierarchy while maintaining the native capability of promptable segmentation backbones. As an initial step toward segmenting any concept, we hope ConceptSeg-R1 can serve as a practical baseline for advancing segmentation from object-level prediction toward concept-level understanding.
MeDocVL: A Visual Language Model for Medical Document Understanding and Parsing
Feb 06, 2026Medical document OCR is challenging due to complex layouts, domain-specific terminology, and noisy annotations, while requiring strict field-level exact matching. Existing OCR systems and general-purpose vision-language models often fail to reliably parse such documents. We propose MeDocVL, a post-trained vision-language model for query-driven medical document parsing. Our framework combines Training-driven Label Refinement to construct high-quality supervision from noisy annotations, with a Noise-aware Hybrid Post-training strategy that integrates reinforcement learning and supervised fine-tuning to achieve robust and precise extraction. Experiments on medical invoice benchmarks show that MeDocVL consistently outperforms conventional OCR systems and strong VLM baselines, achieving state-of-the-art performance under noisy supervision.
PGOT: A Physics-Geometry Operator Transformer for Complex PDEs
Dec 29, 2025While Transformers have demonstrated remarkable potential in modeling Partial Differential Equations (PDEs), modeling large-scale unstructured meshes with complex geometries remains a significant challenge. Existing efficient architectures often employ feature dimensionality reduction strategies, which inadvertently induces Geometric Aliasing, resulting in the loss of critical physical boundary information. To address this, we propose the Physics-Geometry Operator Transformer (PGOT), designed to reconstruct physical feature learning through explicit geometry awareness. Specifically, we propose Spectrum-Preserving Geometric Attention (SpecGeo-Attention). Utilizing a ``physics slicing-geometry injection" mechanism, this module incorporates multi-scale geometric encodings to explicitly preserve multi-scale geometric features while maintaining linear computational complexity $O(N)$. Furthermore, PGOT dynamically routes computations to low-order linear paths for smooth regions and high-order non-linear paths for shock waves and discontinuities based on spatial coordinates, enabling spatially adaptive and high-precision physical field modeling. PGOT achieves consistent state-of-the-art performance across four standard benchmarks and excels in large-scale industrial tasks including airfoil and car designs.
Towards Authentic Movie Dubbing with Retrieve-Augmented Director-Actor Interaction Learning
Nov 18, 2025The automatic movie dubbing model generates vivid speech from given scripts, replicating a speaker's timbre from a brief timbre prompt while ensuring lip-sync with the silent video. Existing approaches simulate a simplified workflow where actors dub directly without preparation, overlooking the critical director-actor interaction. In contrast, authentic workflows involve a dynamic collaboration: directors actively engage with actors, guiding them to internalize the context cues, specifically emotion, before performance. To address this issue, we propose a new Retrieve-Augmented Director-Actor Interaction Learning scheme to achieve authentic movie dubbing, termed Authentic-Dubber, which contains three novel mechanisms: (1) We construct a multimodal Reference Footage library to simulate the learning footage provided by directors. Note that we integrate Large Language Models (LLMs) to achieve deep comprehension of emotional representations across multimodal signals. (2) To emulate how actors efficiently and comprehensively internalize director-provided footage during dubbing, we propose an Emotion-Similarity-based Retrieval-Augmentation strategy. This strategy retrieves the most relevant multimodal information that aligns with the target silent video. (3) We develop a Progressive Graph-based speech generation approach that incrementally incorporates the retrieved multimodal emotional knowledge, thereby simulating the actor's final dubbing process. The above mechanisms enable the Authentic-Dubber to faithfully replicate the authentic dubbing workflow, achieving comprehensive improvements in emotional expressiveness. Both subjective and objective evaluations on the V2C Animation benchmark dataset validate the effectiveness. The code and demos are available at https://github.com/AI-S2-Lab/Authentic-Dubber.
Co-EPG: A Framework for Co-Evolution of Planning and Grounding in Autonomous GUI Agents
Nov 13, 2025Graphical User Interface (GUI) task automation constitutes a critical frontier in artificial intelligence research. While effective GUI agents synergistically integrate planning and grounding capabilities, current methodologies exhibit two fundamental limitations: (1) insufficient exploitation of cross-model synergies, and (2) over-reliance on synthetic data generation without sufficient utilization. To address these challenges, we propose Co-EPG, a self-iterative training framework for Co-Evolution of Planning and Grounding. Co-EPG establishes an iterative positive feedback loop: through this loop, the planning model explores superior strategies under grounding-based reward guidance via Group Relative Policy Optimization (GRPO), generating diverse data to optimize the grounding model. Concurrently, the optimized Grounding model provides more effective rewards for subsequent GRPO training of the planning model, fostering continuous improvement. Co-EPG thus enables iterative enhancement of agent capabilities through self-play optimization and training data distillation. On the Multimodal-Mind2Web and AndroidControl benchmarks, our framework outperforms existing state-of-the-art methods after just three iterations without requiring external data. The agent consistently improves with each iteration, demonstrating robust self-enhancement capabilities. This work establishes a novel training paradigm for GUI agents, shifting from isolated optimization to an integrated, self-driven co-evolution approach.
Importance-Aware Data Selection for Efficient LLM Instruction Tuning
Nov 10, 2025Instruction tuning plays a critical role in enhancing the performance and efficiency of Large Language Models (LLMs). Its success depends not only on the quality of the instruction data but also on the inherent capabilities of the LLM itself. Some studies suggest that even a small amount of high-quality data can achieve instruction fine-tuning results that are on par with, or even exceed, those from using a full-scale dataset. However, rather than focusing solely on calculating data quality scores to evaluate instruction data, there is a growing need to select high-quality data that maximally enhances the performance of instruction tuning for a given LLM. In this paper, we propose the Model Instruction Weakness Value (MIWV) as a novel metric to quantify the importance of instruction data in enhancing model's capabilities. The MIWV metric is derived from the discrepancies in the model's responses when using In-Context Learning (ICL), helping identify the most beneficial data for enhancing instruction tuning performance. Our experimental results demonstrate that selecting only the top 1\% of data based on MIWV can outperform training on the full dataset. Furthermore, this approach extends beyond existing research that focuses on data quality scoring for data selection, offering strong empirical evidence supporting the effectiveness of our proposed method.
Physics-Informed Neural Networks and Neural Operators for Parametric PDEs: A Human-AI Collaborative Analysis
Nov 06, 2025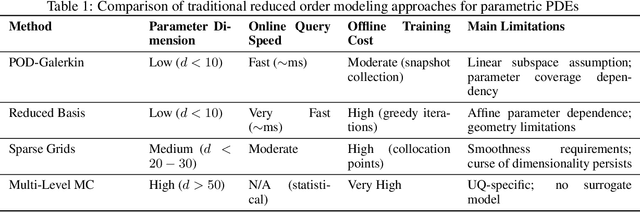
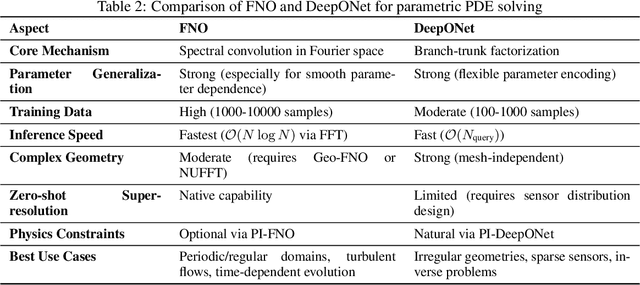
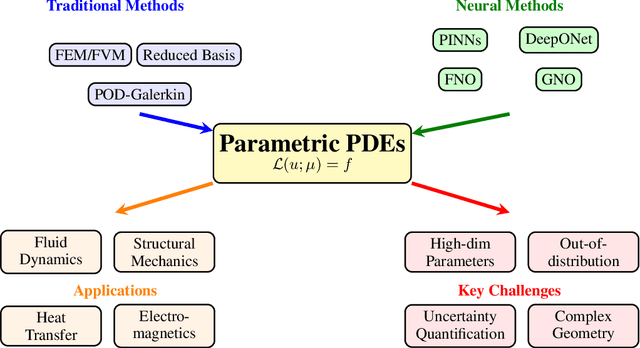
PDEs arise ubiquitously in science and engineering, where solutions depend on parameters (physical properties, boundary conditions, geometry). Traditional numerical methods require re-solving the PDE for each parameter, making parameter space exploration prohibitively expensive. Recent machine learning advances, particularly physics-informed neural networks (PINNs) and neural operators, have revolutionized parametric PDE solving by learning solution operators that generalize across parameter spaces. We critically analyze two main paradigms: (1) PINNs, which embed physical laws as soft constraints and excel at inverse problems with sparse data, and (2) neural operators (e.g., DeepONet, Fourier Neural Operator), which learn mappings between infinite-dimensional function spaces and achieve unprecedented generalization. Through comparisons across fluid dynamics, solid mechanics, heat transfer, and electromagnetics, we show neural operators can achieve computational speedups of $10^3$ to $10^5$ times faster than traditional solvers for multi-query scenarios, while maintaining comparable accuracy. We provide practical guidance for method selection, discuss theoretical foundations (universal approximation, convergence), and identify critical open challenges: high-dimensional parameters, complex geometries, and out-of-distribution generalization. This work establishes a unified framework for understanding parametric PDE solvers via operator learning, offering a comprehensive, incrementally updated resource for this rapidly evolving field
MEPG:Multi-Expert Planning and Generation for Compositionally-Rich Image Generation
Sep 04, 2025Text-to-image diffusion models have achieved remarkable image quality, but they still struggle with complex, multiele ment prompts, and limited stylistic diversity. To address these limitations, we propose a Multi-Expert Planning and Gen eration Framework (MEPG) that synergistically integrates position- and style-aware large language models (LLMs) with spatial-semantic expert modules. The framework comprises two core components: (1) a Position-Style-Aware (PSA) module that utilizes a supervised fine-tuned LLM to decom pose input prompts into precise spatial coordinates and style encoded semantic instructions; and (2) a Multi-Expert Dif fusion (MED) module that implements cross-region genera tion through dynamic expert routing across both local regions and global areas. During the generation process for each lo cal region, specialized models (e.g., realism experts, styliza tion specialists) are selectively activated for each spatial par tition via attention-based gating mechanisms. The architec ture supports lightweight integration and replacement of ex pert models, providing strong extensibility. Additionally, an interactive interface enables real-time spatial layout editing and per-region style selection from a portfolio of experts. Ex periments show that MEPG significantly outperforms base line models with the same backbone in both image quality and style diversity.
Multimodal Human-AI Synergy for Medical Imaging Quality Control: A Hybrid Intelligence Framework with Adaptive Dataset Curation and Closed-Loop Evaluation
Mar 10, 2025Medical imaging quality control (QC) is essential for accurate diagnosis, yet traditional QC methods remain labor-intensive and subjective. To address this challenge, in this study, we establish a standardized dataset and evaluation framework for medical imaging QC, systematically assessing large language models (LLMs) in image quality assessment and report standardization. Specifically, we first constructed and anonymized a dataset of 161 chest X-ray (CXR) radiographs and 219 CT reports for evaluation. Then, multiple LLMs, including Gemini 2.0-Flash, GPT-4o, and DeepSeek-R1, were evaluated based on recall, precision, and F1 score to detect technical errors and inconsistencies. Experimental results show that Gemini 2.0-Flash achieved a Macro F1 score of 90 in CXR tasks, demonstrating strong generalization but limited fine-grained performance. DeepSeek-R1 excelled in CT report auditing with a 62.23\% recall rate, outperforming other models. However, its distilled variants performed poorly, while InternLM2.5-7B-chat exhibited the highest additional discovery rate, indicating broader but less precise error detection. These findings highlight the potential of LLMs in medical imaging QC, with DeepSeek-R1 and Gemini 2.0-Flash demonstrating superior performance.
Towards Expressive Video Dubbing with Multiscale Multimodal Context Interaction
Dec 25, 2024


Automatic Video Dubbing (AVD) generates speech aligned with lip motion and facial emotion from scripts. Recent research focuses on modeling multimodal context to enhance prosody expressiveness but overlooks two key issues: 1) Multiscale prosody expression attributes in the context influence the current sentence's prosody. 2) Prosody cues in context interact with the current sentence, impacting the final prosody expressiveness. To tackle these challenges, we propose M2CI-Dubber, a Multiscale Multimodal Context Interaction scheme for AVD. This scheme includes two shared M2CI encoders to model the multiscale multimodal context and facilitate its deep interaction with the current sentence. By extracting global and local features for each modality in the context, utilizing attention-based mechanisms for aggregation and interaction, and employing an interaction-based graph attention network for fusion, the proposed approach enhances the prosody expressiveness of synthesized speech for the current sentence. Experiments on the Chem dataset show our model outperforms baselines in dubbing expressiveness. The code and demos are available at \textcolor[rgb]{0.93,0.0,0.47}{https://github.com/AI-S2-Lab/M2CI-Dubber}.