 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Intelligence for Multidisciplinary Decision-Making in Gastrointestinal Oncology
Dec 23, 2025Multimodal clinical reasoning in the field of gastrointestinal (GI) oncology necessitates the integrated interpretation of endoscopic imagery, radiological data, and biochemical markers. Despite the evident potential exhibited by Multimodal Large Language Models (MLLMs), they frequently encounter challenges such as context dilution and hallucination when confronted with intricate, heterogeneous medical histories. In order to address these limitations, a hierarchical Multi-Agent Framework is proposed, which emulates the collaborative workflow of a human Multidisciplinary Team (MDT). The system attained a composite expert evaluation score of 4.60/5.00, thereby demonstrating a substantial improvement over the monolithic baseline. It is noteworthy that the agent-based architecture yielded the most substantial enhancements in reasoning logic and medical accuracy. The findings indicate that mimetic, agent-based collaboration provides a scalable, interpretable, and clinically robust paradigm for automated decision support in oncology.
MedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents
Nov 19, 2025Recent advances in medical large language models (LLMs), multimodal models, and agents demand evaluation frameworks that reflect real clinical workflows and safety constraints. We present MedBench v4, a nationwide, cloud-based benchmarking infrastructure comprising over 700,000 expert-curated tasks spanning 24 primary and 91 secondary specialties, with dedicated tracks for LLMs, multimodal models, and agents. Items undergo multi-stage refinement and multi-round review by clinicians from more than 500 institutions, and open-ended responses are scored by an LLM-as-a-judge calibrated to human ratings. We evaluate 15 frontier models. Base LLMs reach a mean overall score of 54.1/100 (best: Claude Sonnet 4.5, 62.5/100), but safety and ethics remain low (18.4/100). Multimodal models perform worse overall (mean 47.5/100; best: GPT-5, 54.9/100), with solid perception yet weaker cross-modal reasoning. Agents built on the same backbones substantially improve end-to-end performance (mean 79.8/100), with Claude Sonnet 4.5-based agents achieving up to 85.3/100 overall and 88.9/100 on safety tasks. MedBench v4 thus reveals persisting gaps in multimodal reasoning and safety for base models, while showing that governance-aware agentic orchestration can markedly enhance benchmarked clinical readiness without sacrificing capability. By aligning tasks with Chinese clinical guidelines and regulatory priorities, the platform offers a practical reference for hospitals, developers, and policymakers auditing medical AI.
Can Large Language Models Function as Qualified Pediatricians? A Systematic Evaluation in Real-World Clinical Contexts
Nov 17, 2025With the rapid rise of large language models (LLMs) in medicine, a key question is whether they can function as competent pediatricians in real-world clinical settings. We developed PEDIASBench, a systematic evaluation framework centered on a knowledge-system framework and tailored to realistic clinical environments. PEDIASBench assesses LLMs across three dimensions: application of basic knowledge, dynamic diagnosis and treatment capability, and pediatric medical safety and medical ethics. We evaluated 12 representative models released over the past two years, including GPT-4o, Qwen3-235B-A22B, and DeepSeek-V3, covering 19 pediatric subspecialties and 211 prototypical diseases. State-of-the-art models performed well on foundational knowledge, with Qwen3-235B-A22B achieving over 90% accuracy on licensing-level questions, but performance declined ~15% as task complexity increased, revealing limitations in complex reasoning. Multiple-choice assessments highlighted weaknesses in integrative reasoning and knowledge recall. In dynamic diagnosis and treatment scenarios, DeepSeek-R1 scored highest in case reasoning (mean 0.58), yet most models struggled to adapt to real-time patient changes. On pediatric medical ethics and safety tasks, Qwen2.5-72B performed best (accuracy 92.05%), though humanistic sensitivity remained limited. These findings indicate that pediatric LLMs are constrained by limited dynamic decision-making and underdeveloped humanistic care. Future development should focus on multimodal integration and a clinical feedback-model iteration loop to enhance safety, interpretability, and human-AI collaboration. While current LLMs cannot independently perform pediatric care, they hold promise for decision support, medical education, and patient communication, laying the groundwork for a safe, trustworthy, and collaborative intelligent pediatric healthcare system.
MedCalc-Eval and MedCalc-Env: Advancing Medical Calculation Capabilities of Large Language Models
Oct 31, 2025As large language models (LLMs) enter the medical domain, most benchmarks evaluate them on question answering or descriptive reasoning, overlooking quantitative reasoning critical to clinical decision-making. Existing datasets like MedCalc-Bench cover few calculation tasks and fail to reflect real-world computational scenarios. We introduce MedCalc-Eval, the largest benchmark for assessing LLMs' medical calculation abilities, comprising 700+ tasks across two types: equation-based (e.g., Cockcroft-Gault, BMI, BSA) and rule-based scoring systems (e.g., Apgar, Glasgow Coma Scale). These tasks span diverse specialties including internal medicine, surgery, pediatrics, and cardiology, offering a broader and more challenging evaluation setting. To improve performance, we further develop MedCalc-Env, a reinforcement learning environment built on the InternBootcamp framework, enabling multi-step clinical reasoning and planning. Fine-tuning a Qwen2.5-32B model within this environment achieves state-of-the-art results on MedCalc-Eval, with notable gains in numerical sensitivity, formula selection, and reasoning robustness. Remaining challenges include unit conversion, multi-condition logic, and contextual understanding. Code and datasets are available at https://github.com/maokangkun/MedCalc-Eval.
Benchmarking Ethical and Safety Risks of Healthcare LLMs in China-Toward Systemic Governance under Healthy China 2030
May 12, 2025
Large Language Models (LLMs) are poised to transform healthcare under China's Healthy China 2030 initiative, yet they introduce new ethical and patient-safety challenges. We present a novel 12,000-item Q&A benchmark covering 11 ethics and 9 safety dimensions in medical contexts, to quantitatively evaluate these risks. Using this dataset, we assess state-of-the-art Chinese medical LLMs (e.g., Qwen 2.5-32B, DeepSeek), revealing moderate baseline performance (accuracy 42.7% for Qwen 2.5-32B) and significant improvements after fine-tuning on our data (up to 50.8% accuracy). Results show notable gaps in LLM decision-making on ethics and safety scenarios, reflecting insufficient institutional oversight. We then identify systemic governance shortfalls-including the lack of fine-grained ethical audit protocols, slow adaptation by hospital IRBs, and insufficient evaluation tools-that currently hinder safe LLM deployment. Finally, we propose a practical governance framework for healthcare institutions (embedding LLM auditing teams, enacting data ethics guidelines, and implementing safety simulation pipelines) to proactively manage LLM risks. Our study highlights the urgent need for robust LLM governance in Chinese healthcare, aligning AI innovation with patient safety and ethical standards.
Building a Human-Verified Clinical Reasoning Dataset via a Human LLM Hybrid Pipeline for Trustworthy Medical AI
May 11, 2025Despite strong performance in medical question-answering, the clinical adoption of Large Language Models (LLMs) is critically hampered by their opaque 'black-box' reasoning, limiting clinician trust. This challenge is compounded by the predominant reliance of current medical LLMs on corpora from scientific literature or synthetic data, which often lack the granular expert validation and high clinical relevance essential for advancing their specialized medical capabilities. To address these critical gaps, we introduce a highly clinically relevant dataset with 31,247 medical question-answer pairs, each accompanied by expert-validated chain-of-thought (CoT) explanations. This resource, spanning multiple clinical domains, was curated via a scalable human-LLM hybrid pipeline: LLM-generated rationales were iteratively reviewed, scored, and refined by medical experts against a structured rubric, with substandard outputs revised through human effort or guided LLM regeneration until expert consensus. This publicly available dataset provides a vital source for the development of medical LLMs that capable of transparent and verifiable reasoning, thereby advancing safer and more interpretable AI in medicine.
Multimodal Human-AI Synergy for Medical Imaging Quality Control: A Hybrid Intelligence Framework with Adaptive Dataset Curation and Closed-Loop Evaluation
Mar 10, 2025Medical imaging quality control (QC) is essential for accurate diagnosis, yet traditional QC methods remain labor-intensive and subjective. To address this challenge, in this study, we establish a standardized dataset and evaluation framework for medical imaging QC, systematically assessing large language models (LLMs) in image quality assessment and report standardization. Specifically, we first constructed and anonymized a dataset of 161 chest X-ray (CXR) radiographs and 219 CT reports for evaluation. Then, multiple LLMs, including Gemini 2.0-Flash, GPT-4o, and DeepSeek-R1, were evaluated based on recall, precision, and F1 score to detect technical errors and inconsistencies. Experimental results show that Gemini 2.0-Flash achieved a Macro F1 score of 90 in CXR tasks, demonstrating strong generalization but limited fine-grained performance. DeepSeek-R1 excelled in CT report auditing with a 62.23\% recall rate, outperforming other models. However, its distilled variants performed poorly, while InternLM2.5-7B-chat exhibited the highest additional discovery rate, indicating broader but less precise error detection. These findings highlight the potential of LLMs in medical imaging QC, with DeepSeek-R1 and Gemini 2.0-Flash demonstrating superior performance.
A Novel Ophthalmic Benchmark for Evaluating Multimodal Large Language Models with Fundus Photographs and OCT Images
Mar 10, 2025
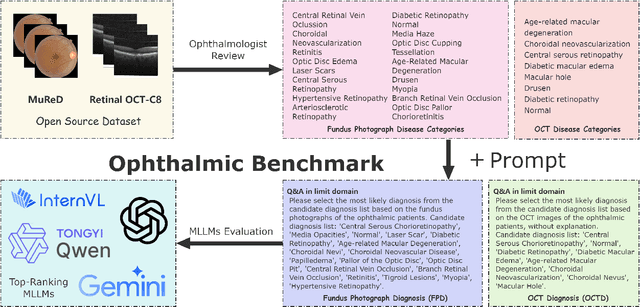

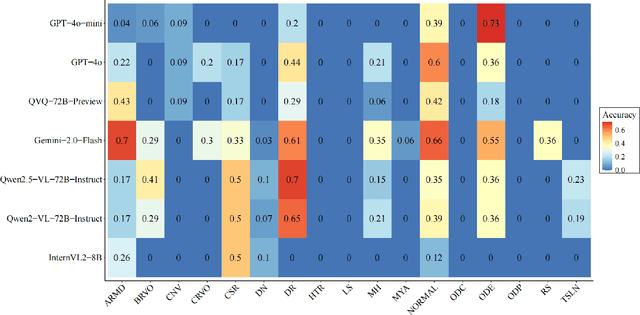
In recent years, large language models (LLMs) have demonstrated remarkable potential across various medical applications. Building on this foundation, multimodal large language models (MLLMs) integrate LLMs with visual models to process diverse inputs, including clinical data and medical images. In ophthalmology, LLMs have been explored for analyzing optical coherence tomography (OCT) reports, assisting in disease classification, and even predicting treatment outcomes. However, existing MLLM benchmarks often fail to capture the complexities of real-world clinical practice, particularly in the analysis of OCT images. Many suffer from limitations such as small sample sizes, a lack of diverse OCT datasets, and insufficient expert validation. These shortcomings hinder the accurate assessment of MLLMs' ability to interpret OCT scans and their broader applicability in ophthalmology. Our dataset, curated through rigorous quality control and expert annotation, consists of 439 fundus images and 75 OCT images. Using a standardized API-based framework, we assessed seven mainstream MLLMs and observed significant variability in diagnostic accuracy across different diseases. While some models performed well in diagnosing conditions such as diabetic retinopathy and age-related macular degeneration, they struggled with others, including choroidal neovascularization and myopia, highlighting inconsistencies in performance and the need for further refinement. Our findings emphasize the importance of developing clinically relevant benchmarks to provide a more accurate assessment of MLLMs' capabilities. By refining these models and expanding their scope, we can enhance their potential to transform ophthalmic diagnosis and treatment.