 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Human-AI Synergy for Medical Imaging Quality Control: A Hybrid Intelligence Framework with Adaptive Dataset Curation and Closed-Loop Evaluation
Mar 10, 2025Medical imaging quality control (QC) is essential for accurate diagnosis, yet traditional QC methods remain labor-intensive and subjective. To address this challenge, in this study, we establish a standardized dataset and evaluation framework for medical imaging QC, systematically assessing large language models (LLMs) in image quality assessment and report standardization. Specifically, we first constructed and anonymized a dataset of 161 chest X-ray (CXR) radiographs and 219 CT reports for evaluation. Then, multiple LLMs, including Gemini 2.0-Flash, GPT-4o, and DeepSeek-R1, were evaluated based on recall, precision, and F1 score to detect technical errors and inconsistencies. Experimental results show that Gemini 2.0-Flash achieved a Macro F1 score of 90 in CXR tasks, demonstrating strong generalization but limited fine-grained performance. DeepSeek-R1 excelled in CT report auditing with a 62.23\% recall rate, outperforming other models. However, its distilled variants performed poorly, while InternLM2.5-7B-chat exhibited the highest additional discovery rate, indicating broader but less precise error detection. These findings highlight the potential of LLMs in medical imaging QC, with DeepSeek-R1 and Gemini 2.0-Flash demonstrating superior performance.
AAVDiff: Experimental Validation of Enhanced Viability and Diversity in Recombinant Adeno-Associated Virus (AAV) Capsids through Diffusion Generation
Apr 17, 2024Recombinant adeno-associated virus (rAAV) vectors have revolutionized gene therapy, but their broad tropism and suboptimal transduction efficiency limit their clinical applications. To overcome these limitations, researchers have focused on designing and screening capsid libraries to identify improved vectors. However, the large sequence space and limited resources present challenges in identifying viable capsid variants. In this study, we propose an end-to-end diffusion model to generate capsid sequences with enhanced viability. Using publicly available AAV2 data, we generated 38,000 diverse AAV2 viral protein (VP) sequences, and evaluated 8,000 for viral selection. The results attested the superiority of our model compared to traditional methods. Additionally, in the absence of AAV9 capsid data, apart from one wild-type sequence, we used the same model to directly generate a number of viable sequences with up to 9 mutations. we transferred the remaining 30,000 samples to the AAV9 domain. Furthermore, we conducted mutagenesis on AAV9 VP hypervariable regions VI and V, contributing to the continuous improvement of the AAV9 VP sequence. This research represents a significant advancement in the design and functional validation of rAAV vectors, offering innovative solutions to enhance specificity and transduction efficiency in gene therapy applications.
Batch-less stochastic gradient descent for compressive learning of deep regularization for image denoising
Oct 02, 2023We consider the problem of denoising with the help of prior information taken from a database of clean signals or images. Denoising with variational methods is very efficient if a regularizer well adapted to the nature of the data is available. Thanks to the maximum a posteriori Bayesian framework, such regularizer can be systematically linked with the distribution of the data. With deep neural networks (DNN), complex distributions can be recovered from a large training database.To reduce the computational burden of this task, we adapt the compressive learning framework to the learning of regularizers parametrized by DNN. We propose two variants of stochastic gradient descent (SGD) for the recovery of deep regularization parameters from a heavily compressed database. These algorithms outperform the initially proposed method that was limited to low-dimensional signals, each iteration using information from the whole database. They also benefit from classical SGD convergence guarantees. Thanks to these improvements we show that this method can be applied for patch based image denoising.}
Contrastive Learning with Bidirectional Transformers for Sequential Recommendation
Aug 14, 2022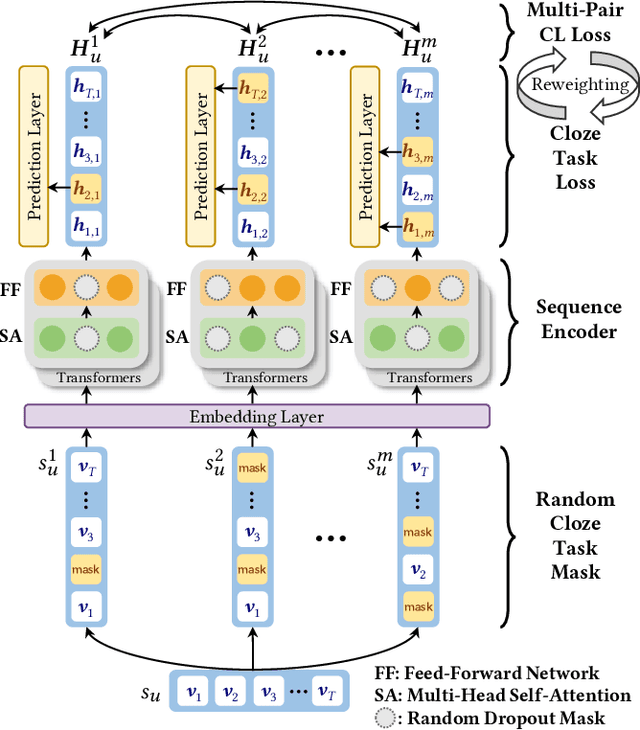
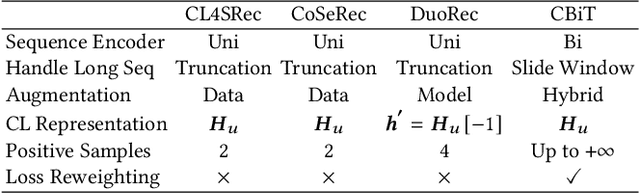

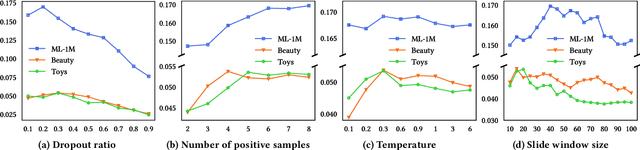
Contrastive learning with Transformer-based sequence encoder has gained predominance for sequential recommendation. It maximizes the agreements between paired sequence augmentations that share similar semantics. However, existing contrastive learning approaches in sequential recommendation mainly center upon left-to-right unidirectional Transformers as base encoders, which are suboptimal for sequential recommendation because user behaviors may not be a rigid left-to-right sequence. To tackle that, we propose a novel framework named \textbf{C}ontrastive learning with \textbf{Bi}directional \textbf{T}ransformers for sequential recommendation (\textbf{CBiT}). Specifically, we first apply the slide window technique for long user sequences in bidirectional Transformers, which allows for a more fine-grained division of user sequences. Then we combine the cloze task mask and the dropout mask to generate high-quality positive samples and perform multi-pair contrastive learning, which demonstrates better performance and adaptability compared with the normal one-pair contrastive learning. Moreover, we introduce a novel dynamic loss reweighting strategy to balance between the cloze task loss and the contrastive loss. Experiment results on three public benchmark datasets show that our model outperforms state-of-the-art models for sequential recommendation.
Every Preference Changes Differently: Neural Multi-Interest Preference Model with Temporal Dynamics for Recommendation
Jul 21, 2022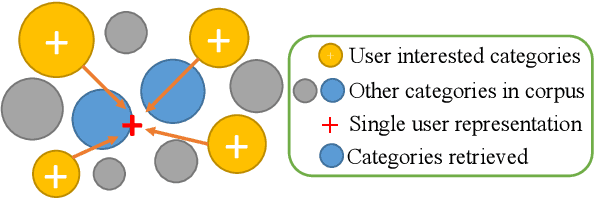

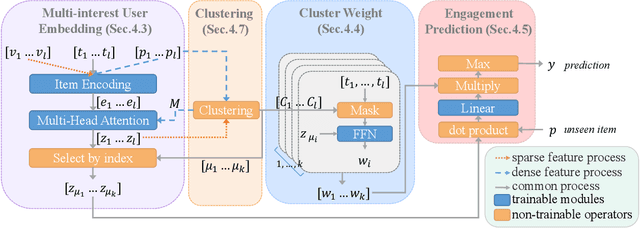
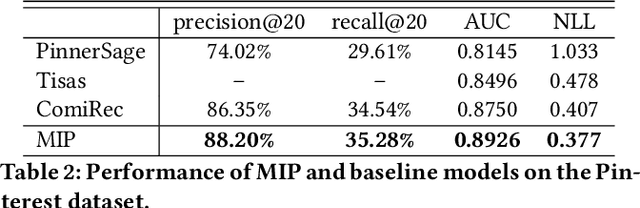
User embeddings (vectorized representations of a user) are essential in recommendation systems. Numerous approaches have been proposed to construct a representation for the user in order to find similar items for retrieval tasks, and they have been proven effective in industrial recommendation systems as well. Recently people have discovered the power of using multiple embeddings to represent a user, with the hope that each embedding represents the user's interest in a certain topic. With multi-interest representation, it's important to model the user's preference over the different topics and how the preference change with time. However, existing approaches either fail to estimate the user's affinity to each interest or unreasonably assume every interest of every user fades with an equal rate with time, thus hurting the recall of candidate retrieval. In this paper, we propose the Multi-Interest Preference (MIP) model, an approach that not only produces multi-interest for users by using the user's sequential engagement more effectively but also automatically learns a set of weights to represent the preference over each embedding so that the candidates can be retrieved from each interest proportionally. Extensive experiments have been done on various industrial-scale datasets to demonstrate the effectiveness of our approach.
Learning Bounded Context-Free-Grammar via LSTM and the Transformer:Difference and Explanations
Dec 16, 2021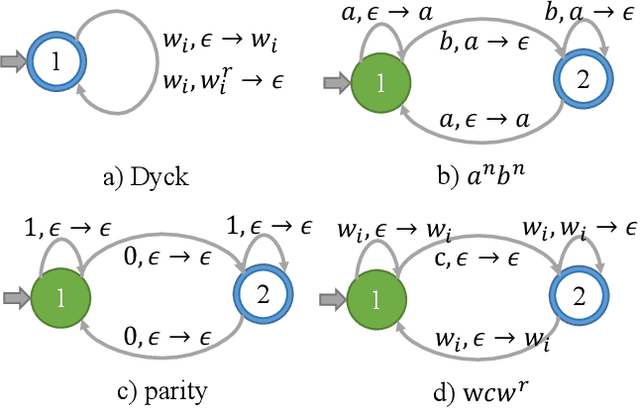
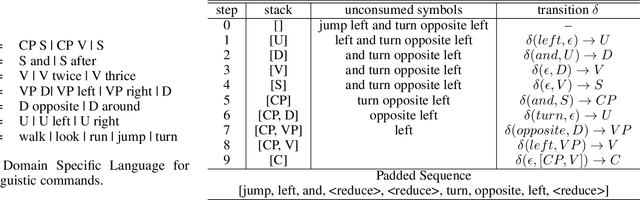
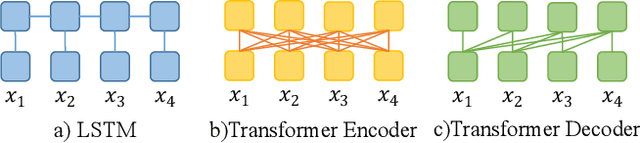
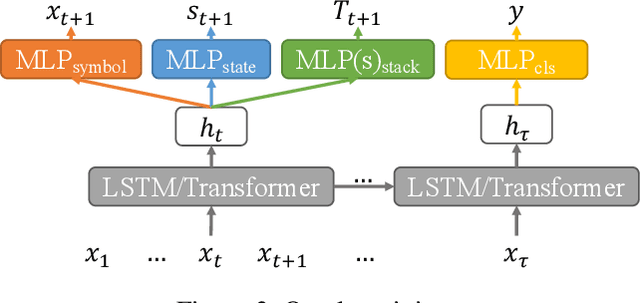
Long Short-Term Memory (LSTM) and Transformers are two popular neural architectures used for natural language processing tasks. Theoretical results show that both are Turing-complete and can represent any context-free language (CFL).In practice, it is often observed that Transformer models have better representation power than LSTM. But the reason is barely understood. We study such practical differences between LSTM and Transformer and propose an explanation based on their latent space decomposition patterns. To achieve this goal, we introduce an oracle training paradigm, which forces the decomposition of the latent representation of LSTM and the Transformer and supervises with the transitions of the Pushdown Automaton (PDA) of the corresponding CFL. With the forced decomposition, we show that the performance upper bounds of LSTM and Transformer in learning CFL are close: both of them can simulate a stack and perform stack operation along with state transitions. However, the absence of forced decomposition leads to the failure of LSTM models to capture the stack and stack operations, while having a marginal impact on the Transformer model. Lastly, we connect the experiment on the prototypical PDA to a real-world parsing task to re-verify the conclusions
Towards Safety-Aware Computing System Design in Autonomous Vehicles
May 22, 2019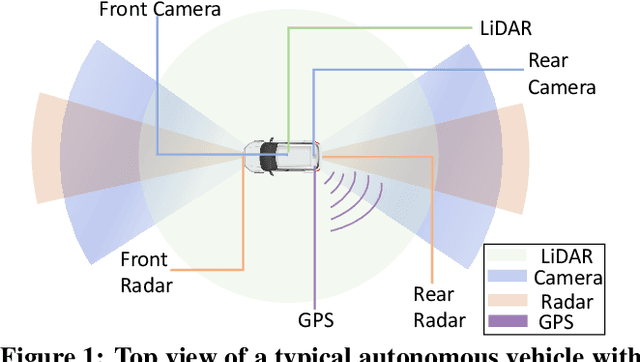

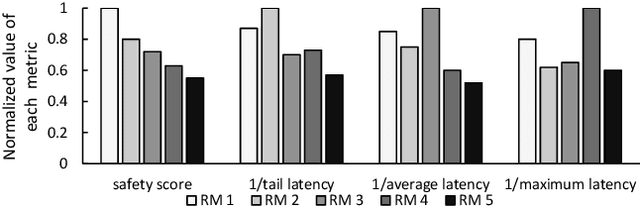
Recently, autonomous driving development ignited competition among car makers and technical corporations. Low-level automation cars are already commercially available. But high automated vehicles where the vehicle drives by itself without human monitoring is still at infancy. Such autonomous vehicles (AVs) rely on the computing system in the car to to interpret the environment and make driving decisions. Therefore, computing system design is essential particularly in enhancing the attainment of driving safety. However, to our knowledge, no clear guideline exists so far regarding safety-aware AV computing system and architecture design. To understand the safety requirement of AV computing system, we performed a field study by running industrial Level-4 autonomous driving fleets in various locations, road conditions, and traffic patterns. The field study indicates that traditional computing system performance metrics, such as tail latency, average latency, maximum latency, and timeout, cannot fully satisfy the safety requirement for AV computing system design. To address this issue, we propose a `safety score' as a primary metric for measuring the level of safety in AV computing system design. Furthermore, we propose a perception latency model, which helps architects estimate the safety score of given architecture and system design without physically testing them in an AV. We demonstrate the use of our safety score and latency model, by developing and evaluating a safety-aware AV computing system computation hardware resource management scheme.