 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Contextual Bandits without Rewards: Learning from a Non-Stationary Learner via Suffix Imitation
Mar 04, 2026We study the Inverse Contextual Bandit (ICB) problem, in which a learner seeks to optimize a policy while an observer, who cannot access the learner's rewards and only observes actions, aims to recover the underlying problem parameters. During the learning process, the learner's behavior naturally transitions from exploration to exploitation, resulting in non-stationary action data that poses significant challenges for the observer. To address this issue, we propose a simple and effective framework called Two-Phase Suffix Imitation. The framework discards data from an initial burn-in phase and performs empirical risk minimization using only data from a subsequent imitation phase. We derive a predictive decision loss bound that explicitly characterizes the bias-variance trade-off induced by the choice of burn-in length. Despite the severe information deficit, we show that a reward-free observer can achieve a convergence rate of $\tilde O(1/\sqrt{N})$, matching the asymptotic efficiency of a fully reward-aware learner. This result demonstrates that a passive observer can effectively uncover the optimal policy from actions alone, attaining performance comparable to that of the learner itself.
SRAP-Agent: Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent
Oct 18, 2024



Public scarce resource allocation plays a crucial role in economics as it directly influences the efficiency and equity in society. Traditional studies including theoretical model-based, empirical study-based and simulation-based methods encounter limitations due to the idealized assumption of complete information and individual rationality, as well as constraints posed by limited available data. In this work, we propose an innovative framework, SRAP-Agent (Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent), which integrates Large Language Models (LLMs) into economic simulations, aiming to bridge the gap between theoretical models and real-world dynamics. Using public housing allocation scenarios as a case study, we conduct extensive policy simulation experiments to verify the feasibility and effectiveness of the SRAP-Agent and employ the Policy Optimization Algorithm with certain optimization objectives. The source code can be found in https://github.com/jijiarui-cather/SRAPAgent_Framework
AAVDiff: Experimental Validation of Enhanced Viability and Diversity in Recombinant Adeno-Associated Virus (AAV) Capsids through Diffusion Generation
Apr 17, 2024Recombinant adeno-associated virus (rAAV) vectors have revolutionized gene therapy, but their broad tropism and suboptimal transduction efficiency limit their clinical applications. To overcome these limitations, researchers have focused on designing and screening capsid libraries to identify improved vectors. However, the large sequence space and limited resources present challenges in identifying viable capsid variants. In this study, we propose an end-to-end diffusion model to generate capsid sequences with enhanced viability. Using publicly available AAV2 data, we generated 38,000 diverse AAV2 viral protein (VP) sequences, and evaluated 8,000 for viral selection. The results attested the superiority of our model compared to traditional methods. Additionally, in the absence of AAV9 capsid data, apart from one wild-type sequence, we used the same model to directly generate a number of viable sequences with up to 9 mutations. we transferred the remaining 30,000 samples to the AAV9 domain. Furthermore, we conducted mutagenesis on AAV9 VP hypervariable regions VI and V, contributing to the continuous improvement of the AAV9 VP sequence. This research represents a significant advancement in the design and functional validation of rAAV vectors, offering innovative solutions to enhance specificity and transduction efficiency in gene therapy applications.
IBCB: Efficient Inverse Batched Contextual Bandit for Behavioral Evolution History
Mar 24, 2024


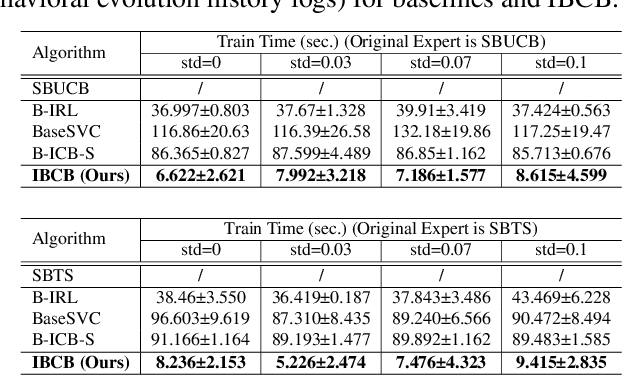
Traditional imitation learning focuses on modeling the behavioral mechanisms of experts, which requires a large amount of interaction history generated by some fixed expert. However, in many streaming applications, such as streaming recommender systems, online decision-makers typically engage in online learning during the decision-making process, meaning that the interaction history generated by online decision-makers includes their behavioral evolution from novice expert to experienced expert. This poses a new challenge for existing imitation learning approaches that can only utilize data from experienced experts. To address this issue, this paper proposes an inverse batched contextual bandit (IBCB) framework that can efficiently perform estimations of environment reward parameters and learned policy based on the expert's behavioral evolution history. Specifically, IBCB formulates the inverse problem into a simple quadratic programming problem by utilizing the behavioral evolution history of the batched contextual bandit with inaccessible rewards. We demonstrate that IBCB is a unified framework for both deterministic and randomized bandit policies. The experimental results indicate that IBCB outperforms several existing imitation learning algorithms on synthetic and real-world data and significantly reduces running time. Additionally, empirical analyses reveal that IBCB exhibits better out-of-distribution generalization and is highly effective in learning the bandit policy from the interaction history of novice experts.
LTP-MMF: Towards Long-term Provider Max-min Fairness Under Recommendation Feedback Loops
Aug 11, 2023



Multi-stakeholder recommender systems involve various roles, such as users, providers. Previous work pointed out that max-min fairness (MMF) is a better metric to support weak providers. However, when considering MMF, the features or parameters of these roles vary over time, how to ensure long-term provider MMF has become a significant challenge. We observed that recommendation feedback loops (named RFL) will influence the provider MMF greatly in the long term. RFL means that recommender system can only receive feedback on exposed items from users and update recommender models incrementally based on this feedback. When utilizing the feedback, the recommender model will regard unexposed item as negative. In this way, tail provider will not get the opportunity to be exposed, and its items will always be considered as negative samples. Such phenomenons will become more and more serious in RFL. To alleviate the problem, this paper proposes an online ranking model named Long-Term Provider Max-min Fairness (named LTP-MMF). Theoretical analysis shows that the long-term regret of LTP-MMF enjoys a sub-linear bound. Experimental results on three public recommendation benchmarks demonstrated that LTP-MMF can outperform the baselines in the long term.
P-MMF: Provider Max-min Fairness Re-ranking in Recommender System
Mar 12, 2023

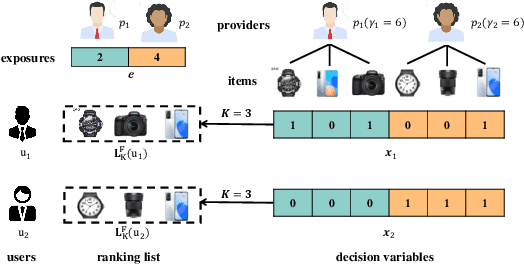

In this paper, we address the issue of recommending fairly from the aspect of providers, which has become increasingly essential in multistakeholder recommender systems. Existing studies on provider fairness usually focused on designing proportion fairness (PF) metrics that first consider systematic fairness. However, sociological researches show that to make the market more stable, max-min fairness (MMF) is a better metric. The main reason is that MMF aims to improve the utility of the worst ones preferentially, guiding the system to support the providers in weak market positions. When applying MMF to recommender systems, how to balance user preferences and provider fairness in an online recommendation scenario is still a challenging problem. In this paper, we proposed an online re-ranking model named Provider Max-min Fairness Re-ranking (P-MMF) to tackle the problem. Specifically, P-MMF formulates provider fair recommendation as a resource allocation problem, where the exposure slots are considered the resources to be allocated to providers and the max-min fairness is used as the regularizer during the process. We show that the problem can be further represented as a regularized online optimizing problem and solved efficiently in its dual space. During the online re-ranking phase, a momentum gradient descent method is designed to conduct the dynamic re-ranking. Theoretical analysis showed that the regret of P-MMF can be bounded. Experimental results on four public recommender datasets demonstrated that P-MMF can outperformed the state-of-the-art baselines. Experimental results also show that P-MMF can retain small computationally costs on a corpus with the large number of items.
Deep Generative Modeling on Limited Data with Regularization by Nontransferable Pre-trained Models
Aug 30, 2022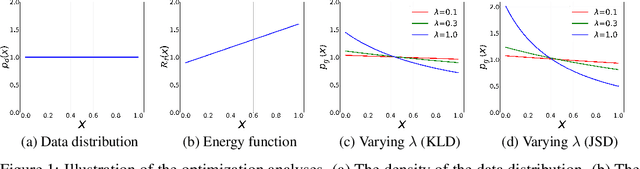
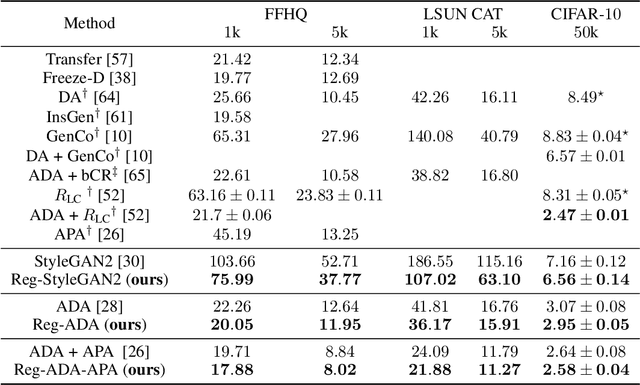
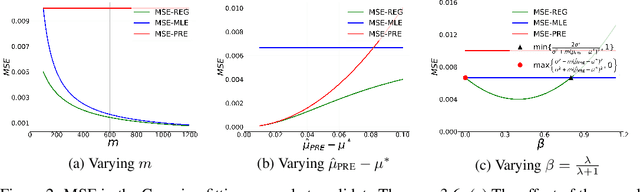

Deep generative models (DGMs) are data-eager. Essentially, it is because learning a complex model on limited data suffers from a large variance and easily overfits. Inspired by the \emph{bias-variance dilemma}, we propose \emph{regularized deep generative model} (Reg-DGM), which leverages a nontransferable pre-trained model to reduce the variance of generative modeling with limited data. Formally, Reg-DGM optimizes a weighted sum of a certain divergence between the data distribution and the DGM and the expectation of an energy function defined by the pre-trained model w.r.t. the DGM. Theoretically, we characterize the existence and uniqueness of the global minimum of Reg-DGM in the nonparametric setting and rigorously prove the statistical benefits of Reg-DGM w.r.t. the mean squared error and the expected risk in a simple yet representative Gaussian-fitting example. Empirically, it is quite flexible to specify the DGM and the pre-trained model in Reg-DGM. In particular, with a ResNet-18 classifier pre-trained on ImageNet and a data-dependent energy function, Reg-DGM consistently improves the generation performance of strong DGMs including StyleGAN2 and ADA on several benchmarks with limited data and achieves competitive results to the state-of-the-art methods.
Learning to Clear the Market
Jun 04, 2019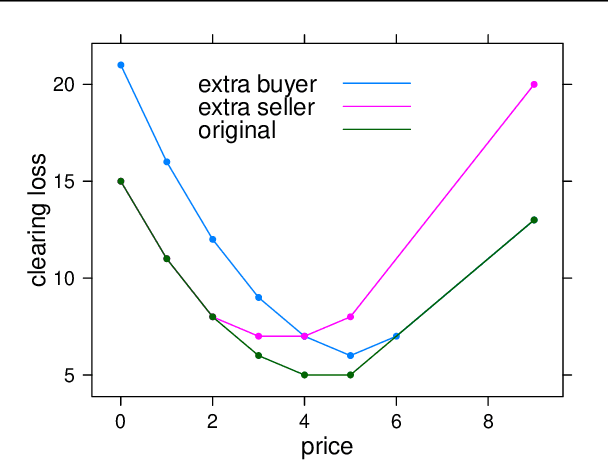
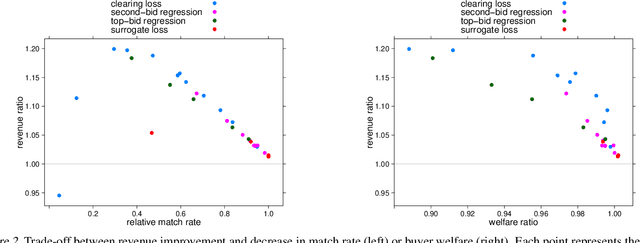

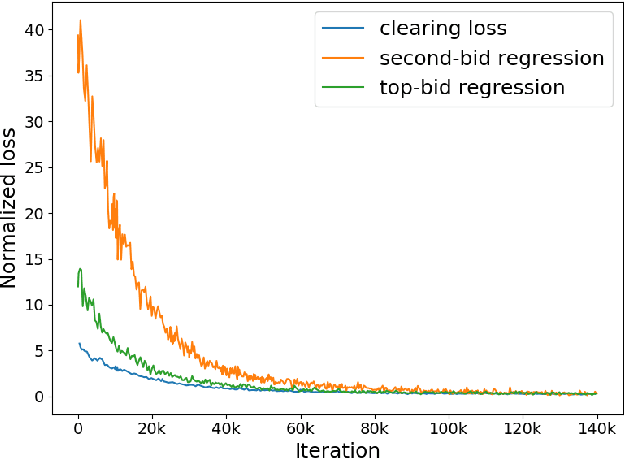
The problem of market clearing is to set a price for an item such that quantity demanded equals quantity supplied. In this work, we cast the problem of predicting clearing prices into a learning framework and use the resulting models to perform revenue optimization in auctions and markets with contextual information. The economic intuition behind market clearing allows us to obtain fine-grained control over the aggressiveness of the resulting pricing policy, grounded in theory. To evaluate our approach, we fit a model of clearing prices over a massive dataset of bids in display ad auctions from a major ad exchange. The learned prices outperform other modeling techniques in the literature in terms of revenue and efficiency trade-offs. Because of the convex nature of the clearing loss function, the convergence rate of our method is as fast as linear regression.
Computer-aided mechanism design: designing revenue-optimal mechanisms via neural networks
May 09, 2018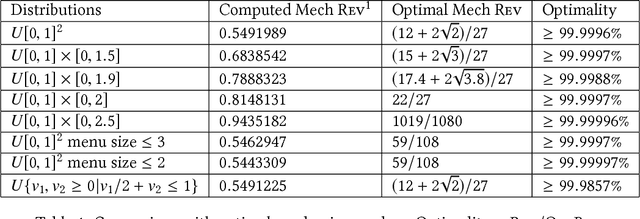
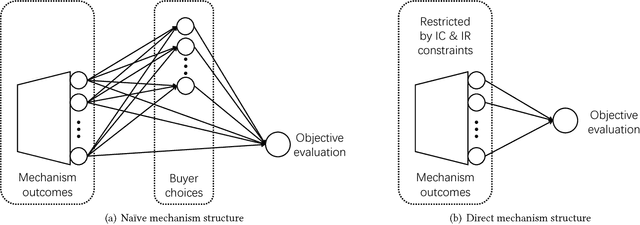
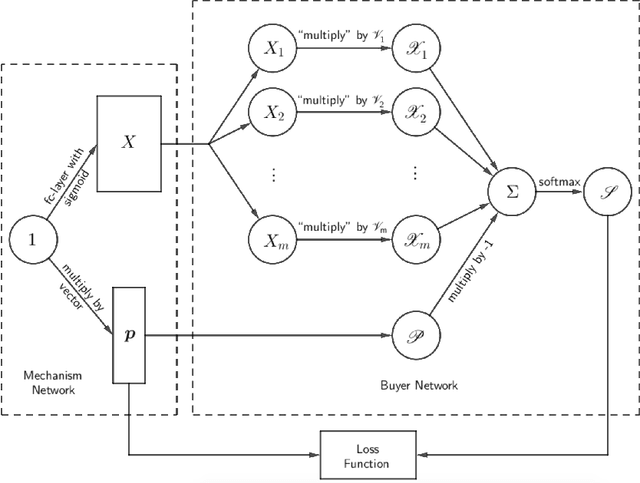
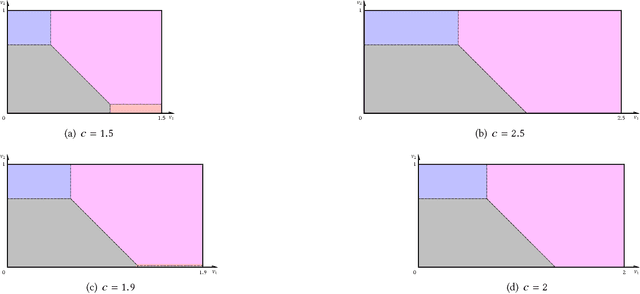
Using AI approaches to automatically design mechanisms has been a central research mission at the interface of AI and economics [Conitzer and Sandholm, 2002]. Previous approaches that a empt to design revenue optimal auctions for the multi-dimensional settings fall short in at least one of the three aspects: 1) representation --- search in a space that probably does not even contain the optimal mechanism; 2) exactness --- finding a mechanism that is either not truthful or far from optimal; 3) domain dependence --- need a different design for different environment settings. To resolve the three difficulties, in this paper, we put forward a uni ed neural network based framework that automatically learns to design revenue optimal mechanisms. Our framework consists of a mechanism network that takes an input distribution for training and outputs a mechanism, as well as a buyer network that takes a mechanism as input and output an action. Such a separation in design mitigates the difficulty to impose incentive compatibility constraints on the mechanism, by making it a rational choice of the buyer. As a result, our framework easily overcomes the previously mentioned difficulty in incorporating IC constraints and always returns exactly incentive compatible mechanisms. We then applied our framework to a number of multi-item revenue optimal design settings, for a few of which the theoretically optimal mechanisms are unknown. We then go on to theoretically prove that the mechanisms found by our framework are indeed optimal.
Optimal Vehicle Dispatching Schemes via Dynamic Pricing
Mar 01, 2018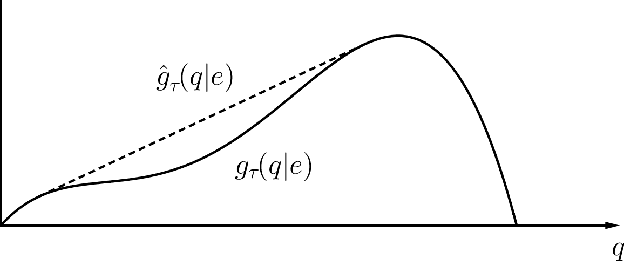


Over the past few years, ride-sharing has emerged as an effective way to relieve traffic congestion. A key problem for these platforms is to come up with a revenue-optimal (or GMV-optimal) pricing scheme and an induced vehicle dispatching policy that incorporate geographic and temporal information. In this paper, we aim to tackle this problem via an economic approach. Modeled naively, the underlying optimization problem may be non-convex and thus hard to compute. To this end, we use a so-called "ironing" technique to convert the problem into an equivalent convex optimization one via a clean Markov decision process (MDP) formulation, where the states are the driver distributions and the decision variables are the prices for each pair of locations. Our main finding is an efficient algorithm that computes the exact revenue-optimal (or GMV-optimal) randomized pricing schemes. We characterize the optimal solution of the MDP by a primal-dual analysis of a corresponding convex program. We also conduct empirical evaluations of our solution through real data of a major ride-sharing platform and show its advantages over fixed pricing schemes as well as several prevalent surge-based pricing schemes.