 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Model-based Interactive Recommendation
Feb 24, 2024Existing model-based interactive recommendation systems are trained by querying a world model to capture the user preference, but learning the world model from historical logged data will easily suffer from bias issues such as popularity bias and sampling bias. This is why some debiased methods have been proposed recently. However, two essential drawbacks still remain: 1) ignoring the dynamics of the time-varying popularity results in a false reweighting of items. 2) taking the unknown samples as negative samples in negative sampling results in the sampling bias. To overcome these two drawbacks, we develop a model called \textbf{i}dentifiable \textbf{D}ebiased \textbf{M}odel-based \textbf{I}nteractive \textbf{R}ecommendation (\textbf{iDMIR} in short). In iDMIR, for the first drawback, we devise a debiased causal world model based on the causal mechanism of the time-varying recommendation generation process with identification guarantees; for the second drawback, we devise a debiased contrastive policy, which coincides with the debiased contrastive learning and avoids sampling bias. Moreover, we demonstrate that the proposed method not only outperforms several latest interactive recommendation algorithms but also enjoys diverse recommendation performance.
Dually Enhanced Propensity Score Estimation in Sequential Recommendation
Mar 15, 2023


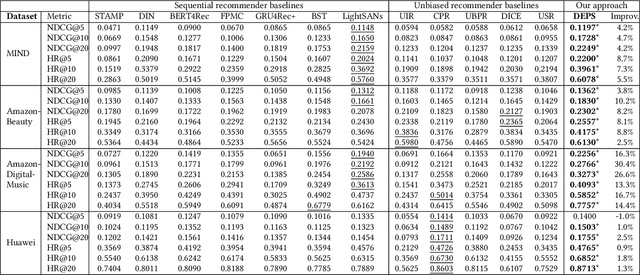
Sequential recommender systems train their models based on a large amount of implicit user feedback data and may be subject to biases when users are systematically under/over-exposed to certain items. Unbiased learning based on inverse propensity scores (IPS), which estimate the probability of observing a user-item pair given the historical information, has been proposed to address the issue. In these methods, propensity score estimation is usually limited to the view of item, that is, treating the feedback data as sequences of items that interacted with the users. However, the feedback data can also be treated from the view of user, as the sequences of users that interact with the items. Moreover, the two views can jointly enhance the propensity score estimation. Inspired by the observation, we propose to estimate the propensity scores from the views of user and item, called Dually Enhanced Propensity Score Estimation (DEPS). Specifically, given a target user-item pair and the corresponding item and user interaction sequences, DEPS firstly constructs a time-aware causal graph to represent the user-item observational probability. According to the graph, two complementary propensity scores are estimated from the views of item and user, respectively, based on the same set of user feedback data. Finally, two transformers are designed to make the final preference prediction. Theoretical analysis showed the unbiasedness and variance of DEPS. Experimental results on three publicly available and an industrial datasets demonstrated that DEPS can significantly outperform the state-of-the-art baselines.
P-MMF: Provider Max-min Fairness Re-ranking in Recommender System
Mar 12, 2023

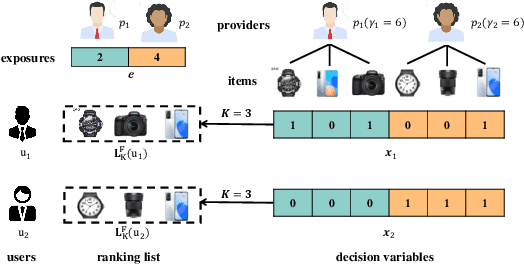

In this paper, we address the issue of recommending fairly from the aspect of providers, which has become increasingly essential in multistakeholder recommender systems. Existing studies on provider fairness usually focused on designing proportion fairness (PF) metrics that first consider systematic fairness. However, sociological researches show that to make the market more stable, max-min fairness (MMF) is a better metric. The main reason is that MMF aims to improve the utility of the worst ones preferentially, guiding the system to support the providers in weak market positions. When applying MMF to recommender systems, how to balance user preferences and provider fairness in an online recommendation scenario is still a challenging problem. In this paper, we proposed an online re-ranking model named Provider Max-min Fairness Re-ranking (P-MMF) to tackle the problem. Specifically, P-MMF formulates provider fair recommendation as a resource allocation problem, where the exposure slots are considered the resources to be allocated to providers and the max-min fairness is used as the regularizer during the process. We show that the problem can be further represented as a regularized online optimizing problem and solved efficiently in its dual space. During the online re-ranking phase, a momentum gradient descent method is designed to conduct the dynamic re-ranking. Theoretical analysis showed that the regret of P-MMF can be bounded. Experimental results on four public recommender datasets demonstrated that P-MMF can outperformed the state-of-the-art baselines. Experimental results also show that P-MMF can retain small computationally costs on a corpus with the large number of items.