 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Sparse Inversion and Token Relabel Enhanced One-shot Federated Learning with ViTs
May 11, 2026One-Shot Federated Learning, where a central server learns a global model in a single communication round, has emerged as a promising paradigm. However, under extremely non-IID settings, existing data-free methods often generate low-quality data that suffers from severe semantic misalignment with ground-truth labels. To overcome these issues, we propose a novel Federated Model Inversion and Token Relabel (FedMITR) framework, which trains the global model by fully exploiting all patches of synthetic images. Specifically, FedMITR employs sparse model inversion during data generation, selectively inverting semantic foregrounds while halting the inversion of uninformative backgrounds. To address semantically meaningless tokens that hinder ViT predictions, we implement a differentiated strategy: patches with high information density utilize generated pseudo-labels, while patches with low information density are relabeled via ensemble models for robust distillation. Theoretically, our analysis based on algorithmic stability reveals that Sparse Model Inversion eliminates gradient instability arising from background noise, while Token Relabel effectively reduces gradient variance, collectively guaranteeing a tighter generalization bound. Empirically, extensive experimental results demonstrate that FedMITR substantially outperforms existing baselines under various settings.
SAM-NER: Semantic Archetype Mediation for Zero-Shot Named Entity Recognition
May 05, 2026Zero-shot Named Entity Recognition (ZS-NER) remains brittle under domain and schema shifts, where unseen label definitions often misalign with a large language model's (LLM's) intrinsic semantic organization. As a result, directly mapping entity mentions to fine-grained target labels can induce systematic semantic drift, especially when target schemas are novel or semantically overlapping. We propose \textbf{SAM-NER}, a three-stage framework based on \emph{Semantic Archetype Mediation} that stabilizes cross-domain transfer through an intermediate, domain-invariant archetype space. SAM-NER: (i) performs \emph{Entity Discovery} via cooperative extraction and consensus-based denoising to obtain high-coverage, high-fidelity entity spans; (ii) conducts \emph{Abstract Mediation} by projecting entities into a compact set of universal semantic archetypes distilled from high-level ontological abstractions; and (iii) applies \emph{Semantic Calibration} to resolve archetype-level predictions into target-domain types through constrained, definition-aligned inference with a frozen LLM. Experiments on the CrossNER benchmark show that SAM-NER consistently outperforms strong prior ZS-NER baselines in cross-domain settings. Our implementation will be open-sourced at https://github.com/DMIRLAB-Group/SAM-NER.
SERE: Structural Example Retrieval for Enhancing LLMs in Event Causality Identification
May 05, 2026Event Causality Identification (ECI) requires models to determine whether a given pair of events in a context exhibits a causal relationship. While Large Language Models (LLMs) have demonstrated strong performance across various NLP tasks, their effectiveness in ECI remains limited due to biases in causal reasoning, often leading to overprediction of causal relationships (causal hallucination). To mitigate these issues and enhance LLM performance in ECI, we propose SERE, a structural example retrieval framework that leverages LLMs' few-shot learning capabilities. SERE introduces an innovative retrieval mechanism based on three structural concepts: (i) Conceptual Path Metric, which measures the conceptual relationship between events using edit distance in ConceptNet; (ii) Syntactic Metric, which quantifies structural similarity through tree edit distance on syntactic trees; and (iii) Causal Pattern Filtering, which filters examples based on predefined causal structures using LLMs. By integrating these structural retrieval strategies, SERE selects more relevant examples to guide LLMs in causal reasoning, mitigating bias and improving accuracy in ECI tasks. Extensive experiments on multiple ECI datasets validate the effectiveness of SERE. The source code is publicly available at https://github.com/DMIRLAB-Group/SERE.
$\mathcal{S}^2$IT: Stepwise Syntax Integration Tuning for Large Language Models in Aspect Sentiment Quad Prediction
Apr 25, 2026Aspect Sentiment Quad Prediction (ASQP) has seen significant advancements, largely driven by the powerful semantic understanding and generative capabilities of large language models (LLMs). However, while syntactic structure information has been proven effective in previous extractive paradigms, it remains underutilized in the generative paradigm of LLMs due to their limited reasoning capabilities. In this paper, we propose S^2IT, a novel Stepwise Syntax Integration Tuning framework that progressively integrates syntactic structure knowledge into LLMs through a multi-step tuning process. The training process is divided into three steps. S^2IT decomposes the quadruple generation task into two stages: 1) Global Syntax-guided Extraction and 2) Local Syntax-guided Classification, integrating both global and local syntactic structure information. Finally, Fine-grained Structural Tuning enhances the model's understanding of syntactic structures through the prediction of element links and node classification. Experiments demonstrate that S^2IT significantly improves state-of-the-art performance across multiple datasets. Our implementation will be open-sourced at https://github.com/DMIRLAB-Group/S2IT.
Temporal Latent Variable Structural Causal Model for Causal Discovery under External Interferences
Nov 13, 2025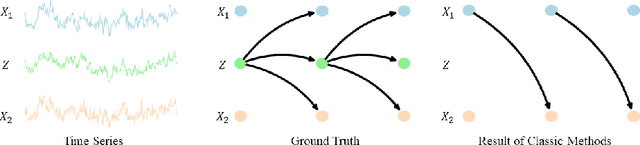

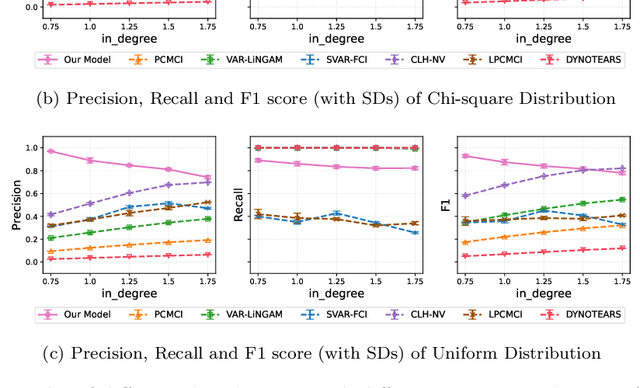
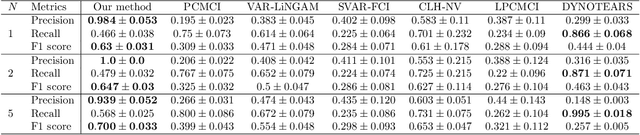
Inferring causal relationships from observed data is an important task, yet it becomes challenging when the data is subject to various external interferences. Most of these interferences are the additional effects of external factors on observed variables. Since these external factors are often unknown, we introduce latent variables to represent these unobserved factors that affect the observed data. Specifically, to capture the causal strength and adjacency information, we propose a new temporal latent variable structural causal model, incorporating causal strength and adjacency coefficients that represent the causal relationships between variables. Considering that expert knowledge can provide information about unknown interferences in certain scenarios, we develop a method that facilitates the incorporation of prior knowledge into parameter learning based on Variational Inference, to guide the model estimation. Experimental results demonstrate the stability and accuracy of our proposed method.
Identification of Causal Direction under an Arbitrary Number of Latent Confounders
Oct 26, 2025Recovering causal structure in the presence of latent variables is an important but challenging task. While many methods have been proposed to handle it, most of them require strict and/or untestable assumptions on the causal structure. In real-world scenarios, observed variables may be affected by multiple latent variables simultaneously, which, generally speaking, cannot be handled by these methods. In this paper, we consider the linear, non-Gaussian case, and make use of the joint higher-order cumulant matrix of the observed variables constructed in a specific way. We show that, surprisingly, causal asymmetry between two observed variables can be directly seen from the rank deficiency properties of such higher-order cumulant matrices, even in the presence of an arbitrary number of latent confounders. Identifiability results are established, and the corresponding identification methods do not even involve iterative procedures. Experimental results demonstrate the effectiveness and asymptotic correctness of our proposed method.
Emotion Transfer with Enhanced Prototype for Unseen Emotion Recognition in Conversation
Aug 27, 2025

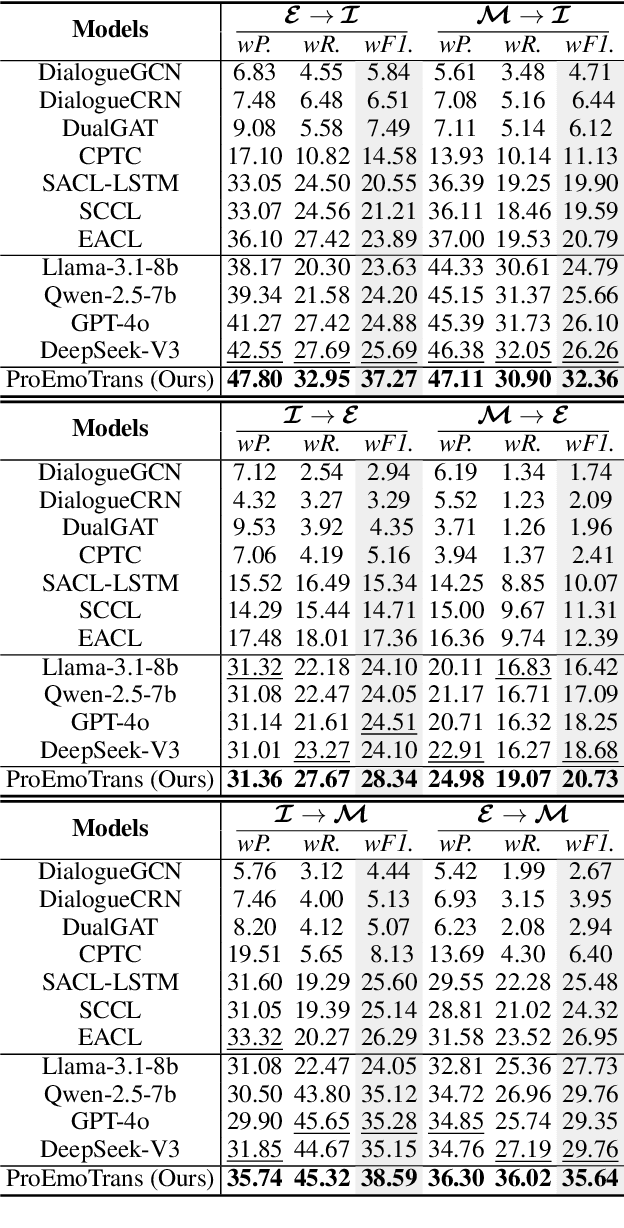
Current Emotion Recognition in Conversation (ERC) research follows a closed-domain assumption. However, there is no clear consensus on emotion classification in psychology, which presents a challenge for models when it comes to recognizing previously unseen emotions in real-world applications. To bridge this gap, we introduce the Unseen Emotion Recognition in Conversation (UERC) task for the first time and propose ProEmoTrans, a solid prototype-based emotion transfer framework. This prototype-based approach shows promise but still faces key challenges: First, implicit expressions complicate emotion definition, which we address by proposing an LLM-enhanced description approach. Second, utterance encoding in long conversations is difficult, which we tackle with a proposed parameter-free mechanism for efficient encoding and overfitting prevention. Finally, the Markovian flow nature of emotions is hard to transfer, which we address with an improved Attention Viterbi Decoding (AVD) method to transfer seen emotion transitions to unseen emotions. Extensive experiments on three datasets show that our method serves as a strong baseline for preliminary exploration in this new area.
Dialogues Aspect-based Sentiment Quadruple Extraction via Structural Entropy Minimization Partitioning
Aug 07, 2025Dialogues Aspect-based Sentiment Quadruple Extraction (DiaASQ) aims to extract all target-aspect-opinion-sentiment quadruples from a given multi-round, multi-participant dialogue. Existing methods typically learn word relations across entire dialogues, assuming a uniform distribution of sentiment elements. However, we find that dialogues often contain multiple semantically independent sub-dialogues without clear dependencies between them. Therefore, learning word relationships across the entire dialogue inevitably introduces additional noise into the extraction process. To address this, our method focuses on partitioning dialogues into semantically independent sub-dialogues. Achieving completeness while minimizing these sub-dialogues presents a significant challenge. Simply partitioning based on reply relationships is ineffective. Instead, we propose utilizing a structural entropy minimization algorithm to partition the dialogues. This approach aims to preserve relevant utterances while distinguishing irrelevant ones as much as possible. Furthermore, we introduce a two-step framework for quadruple extraction: first extracting individual sentiment elements at the utterance level, then matching quadruples at the sub-dialogue level. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in DiaASQ with much lower computational costs.
Horizontal and Vertical Federated Causal Structure Learning via Higher-order Cumulants
Jul 09, 2025Federated causal discovery aims to uncover the causal relationships between entities while protecting data privacy, which has significant importance and numerous applications in real-world scenarios. Existing federated causal structure learning methods primarily focus on horizontal federated settings. However, in practical situations, different clients may not necessarily contain data on the same variables. In a single client, the incomplete set of variables can easily lead to spurious causal relationships, thereby affecting the information transmitted to other clients. To address this issue, we comprehensively consider causal structure learning methods under both horizontal and vertical federated settings. We provide the identification theories and methods for learning causal structure in the horizontal and vertical federal setting via higher-order cumulants. Specifically, we first aggregate higher-order cumulant information from all participating clients to construct global cumulant estimates. These global estimates are then used for recursive source identification, ultimately yielding a global causal strength matrix. Our approach not only enables the reconstruction of causal graphs but also facilitates the estimation of causal strength coefficients. Our algorithm demonstrates superior performance in experiments conducted on both synthetic data and real-world data.
Running-time Analysis of ($μ+λ$) Evolutionary Combinatorial Optimization Based on Multiple-gain Estimation
Jul 03, 2025The running-time analysis of evolutionary combinatorial optimization is a fundamental topic in evolutionary computation. However, theoretical results regarding the $(\mu+\lambda)$ evolutionary algorithm (EA) for combinatorial optimization problems remain relatively scarce compared to those for simple pseudo-Boolean problems. This paper proposes a multiple-gain model to analyze the running time of EAs for combinatorial optimization problems. The proposed model is an improved version of the average gain model, which is a fitness-difference drift approach under the sigma-algebra condition to estimate the running time of evolutionary numerical optimization. The improvement yields a framework for estimating the expected first hitting time of a stochastic process in both average-case and worst-case scenarios. It also introduces novel running-time results of evolutionary combinatorial optimization, including two tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the knapsack problem with favorably correlated weights, a closed-form expression of time complexity upper bound in the case of ($\mu+\lambda$) EA for general $k$-MAX-SAT problems and a tighter time complexity upper bounds than the known results in the case of ($\mu+\lambda$) EA for the traveling salesperson problem. Experimental results indicate that the practical running time aligns with the theoretical results, verifying that the multiple-gain model is an effective tool for running-time analysis of ($\mu+\lambda$) EA for combinatorial optimization problems.