 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-aware Large Language Models: Enhancing Decision-Making Through Learning, Adapting and Acting
May 30, 2025Large language models (LLMs) have shown great potential in decision-making due to the vast amount of knowledge stored within the models. However, these pre-trained models are prone to lack reasoning abilities and are difficult to adapt to new environments, further hindering their application to complex real-world tasks. To address these challenges, inspired by the human cognitive process, we propose Causal-aware LLMs, which integrate the structural causal model (SCM) into the decision-making process to model, update, and utilize structured knowledge of the environment in a ``learning-adapting-acting" paradigm. Specifically, in the learning stage, we first utilize an LLM to extract the environment-specific causal entities and their causal relations to initialize a structured causal model of the environment. Subsequently,in the adapting stage, we update the structured causal model through external feedback about the environment, via an idea of causal intervention. Finally, in the acting stage, Causal-aware LLMs exploit structured causal knowledge for more efficient policy-making through the reinforcement learning agent. The above processes are performed iteratively to learn causal knowledge, ultimately enabling the causal-aware LLMs to achieve a more accurate understanding of the environment and make more efficient decisions. Experimental results across 22 diverse tasks within the open-world game ``Crafter" validate the effectiveness of our proposed method.
Causal Agent based on Large Language Model
Aug 13, 2024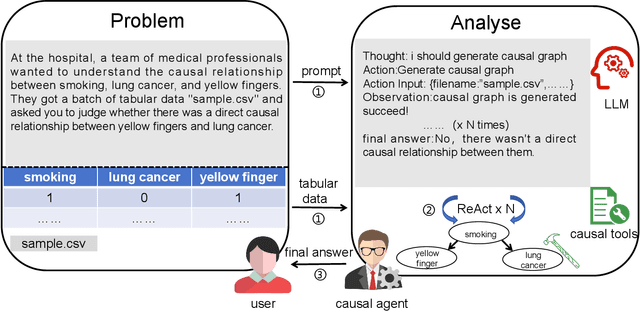
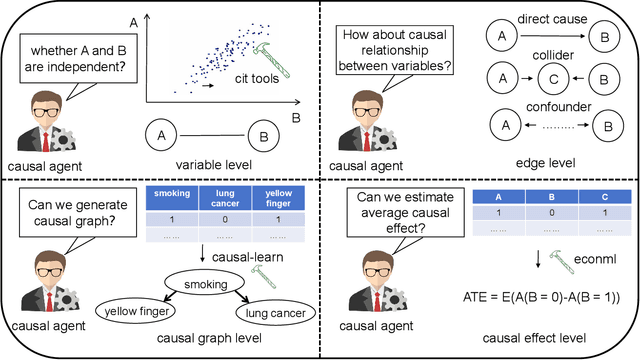
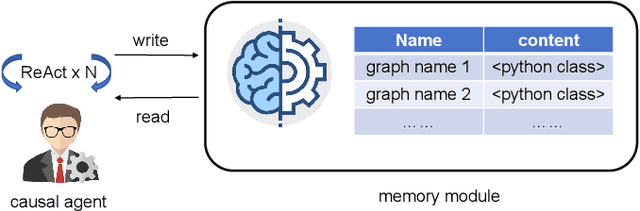
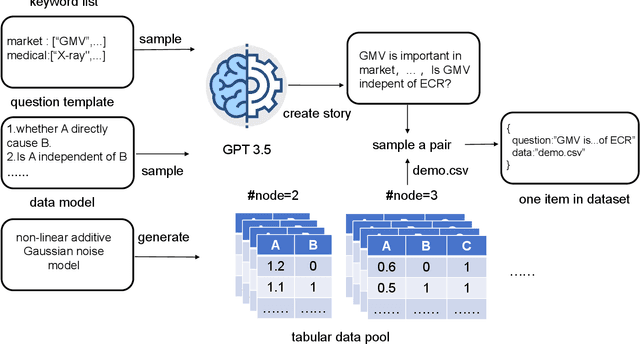
Large language models (LLMs) have achieved significant success across various domains. However, the inherent complexity of causal problems and causal theory poses challenges in accurately describing them in natural language, making it difficult for LLMs to comprehend and use them effectively. Causal methods are not easily conveyed through natural language, which hinders LLMs' ability to apply them accurately. Additionally, causal datasets are typically tabular, while LLMs excel in handling natural language data, creating a structural mismatch that impedes effective reasoning with tabular data. This lack of causal reasoning capability limits the development of LLMs. To address these challenges, we have equipped the LLM with causal tools within an agent framework, named the Causal Agent, enabling it to tackle causal problems. The causal agent comprises tools, memory, and reasoning modules. In the tools module, the causal agent applies causal methods to align tabular data with natural language. In the reasoning module, the causal agent employs the ReAct framework to perform reasoning through multiple iterations with the tools. In the memory module, the causal agent maintains a dictionary instance where the keys are unique names and the values are causal graphs. To verify the causal ability of the causal agent, we established a benchmark consisting of four levels of causal problems: variable level, edge level, causal graph level, and causal effect level. We generated a test dataset of 1.3K using ChatGPT-3.5 for these four levels of issues and tested the causal agent on the datasets. Our methodology demonstrates remarkable efficacy on the four-level causal problems, with accuracy rates all above 80%. For further insights and implementation details, our code is accessible via the GitHub repository https://github.com/Kairong-Han/Causal_Agent.
Time-Series Domain Adaptation via Sparse Associative Structure Alignment: Learning Invariance and Variance
May 07, 2022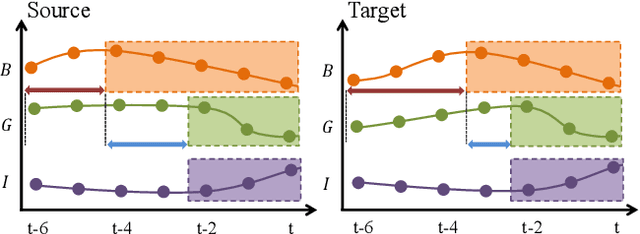

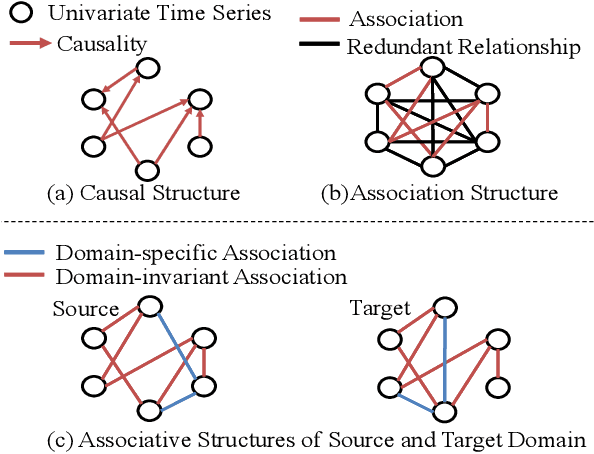

Domain adaptation on time-series data is often encountered in the industry but received limited attention in academia. Most of the existing domain adaptation methods for time-series data borrow the ideas from the existing methods for non-time series data to extract the domain-invariant representation. However, two peculiar difficulties to time-series data have not been solved. 1) It is not a trivial task to model the domain-invariant and complex dependence among different timestamps. 2) The domain-variant information is important but how to leverage them is almost underexploited. Fortunately, the stableness of causal structures among different domains inspires us to explore the structures behind the time-series data. Based on this inspiration, we investigate the domain-invariant unweighted sparse associative structures and the domain-variant strengths of the structures. To achieve this, we propose Sparse Associative structure alignment by learning Invariance and Variance (SASA-IV in short), a model that simultaneously aligns the invariant unweighted spare associative structures and considers the variant information for time-series unsupervised domain adaptation. Technologically, we extract the domain-invariant unweighted sparse associative structures with a unidirectional alignment restriction and embed the domain-variant strengths via a well-designed autoregressive module. Experimental results not only testify that our model yields state-of-the-art performance on three real-world datasets but also provide some insightful discoveries on knowledge transfer.
gCastle: A Python Toolbox for Causal Discovery
Nov 30, 2021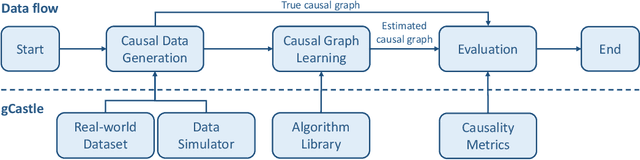
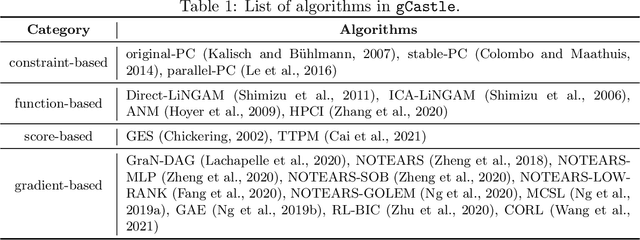
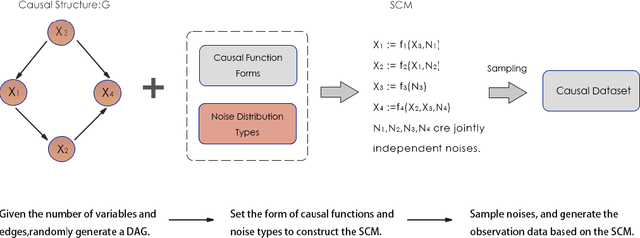
$\texttt{gCastle}$ is an end-to-end Python toolbox for causal structure learning. It provides functionalities of generating data from either simulator or real-world dataset, learning causal structure from the data, and evaluating the learned graph, together with useful practices such as prior knowledge insertion, preliminary neighborhood selection, and post-processing to remove false discoveries. Compared with related packages, $\texttt{gCastle}$ includes many recently developed gradient-based causal discovery methods with optional GPU acceleration. $\texttt{gCastle}$ brings convenience to researchers who may directly experiment with the code as well as practitioners with graphical user interference. Three real-world datasets in telecommunications are also provided in the current version. $\texttt{gCastle}$ is available under Apache License 2.0 at \url{https://github.com/huawei-noah/trustworthyAI/tree/master/gcastle}.
An Influence-based Approach for Root Cause Alarm Discovery in Telecom Networks
May 07, 2021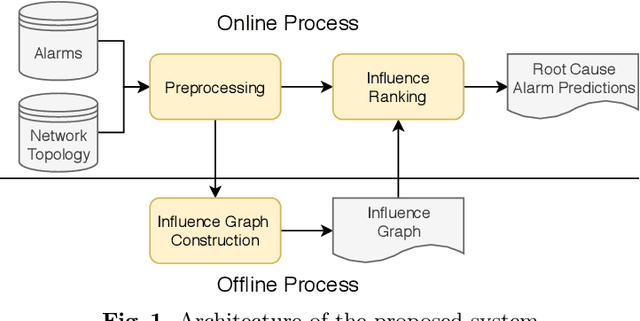
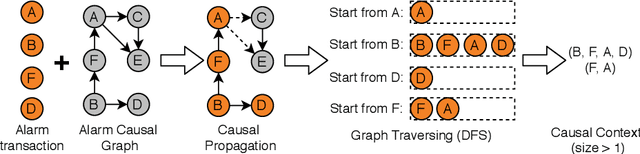
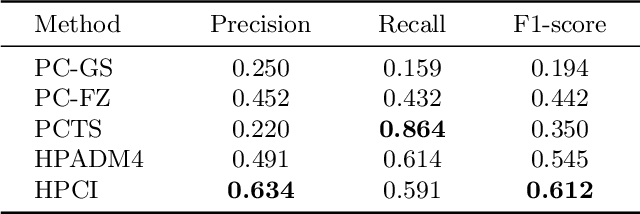
Alarm root cause analysis is a significant component in the day-to-day telecommunication network maintenance, and it is critical for efficient and accurate fault localization and failure recovery. In practice, accurate and self-adjustable alarm root cause analysis is a great challenge due to network complexity and vast amounts of alarms. A popular approach for failure root cause identification is to construct a graph with approximate edges, commonly based on either event co-occurrences or conditional independence tests. However, considerable expert knowledge is typically required for edge pruning. We propose a novel data-driven framework for root cause alarm localization, combining both causal inference and network embedding techniques. In this framework, we design a hybrid causal graph learning method (HPCI), which combines Hawkes Process with Conditional Independence tests, as well as propose a novel Causal Propagation-Based Embedding algorithm (CPBE) to infer edge weights. We subsequently discover root cause alarms in a real-time data stream by applying an influence maximization algorithm on the weighted graph. We evaluate our method on artificial data and real-world telecom data, showing a significant improvement over the best baselines.
Time Series Domain Adaptation via Sparse Associative Structure Alignment
Dec 22, 2020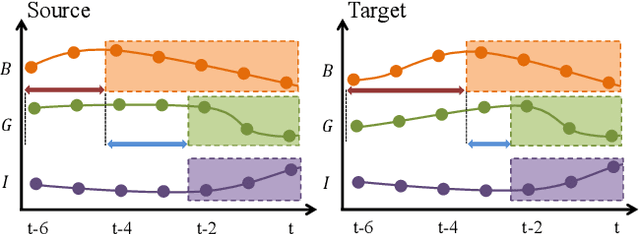

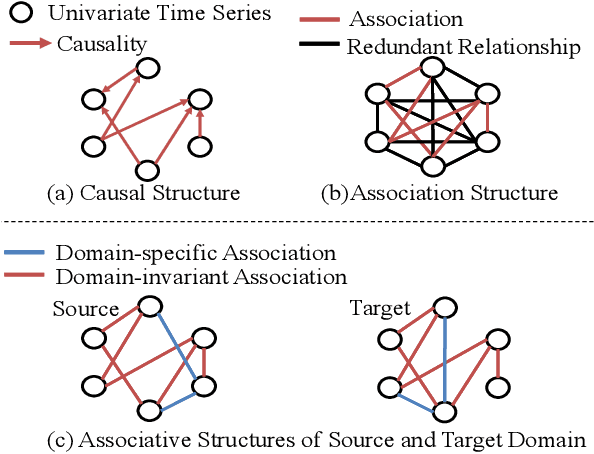

Domain adaptation on time series data is an important but challenging task. Most of the existing works in this area are based on the learning of the domain-invariant representation of the data with the help of restrictions like MMD. However, such extraction of the domain-invariant representation is a non-trivial task for time series data, due to the complex dependence among the timestamps. In detail, in the fully dependent time series, a small change of the time lags or the offsets may lead to difficulty in the domain invariant extraction. Fortunately, the stability of the causality inspired us to explore the domain invariant structure of the data. To reduce the difficulty in the discovery of causal structure, we relax it to the sparse associative structure and propose a novel sparse associative structure alignment model for domain adaptation. First, we generate the segment set to exclude the obstacle of offsets. Second, the intra-variables and inter-variables sparse attention mechanisms are devised to extract associative structure time-series data with considering time lags. Finally, the associative structure alignment is used to guide the transfer of knowledge from the source domain to the target one. Experimental studies not only verify the good performance of our methods on three real-world datasets but also provide some insightful discoveries on the transferred knowledge.