 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusTrack: One-Stage Focus-and-Suppress Framework for 3D Point Cloud Object Tracking
Feb 27, 2026In 3D point cloud object tracking, the motion-centric methods have emerged as a promising avenue due to its superior performance in modeling inter-frame motion. However, existing two-stage motion-based approaches suffer from fundamental limitations: (1) error accumulation due to decoupled optimization caused by explicit foreground segmentation prior to motion estimation, and (2) computational bottlenecks from sequential processing. To address these challenges, we propose FocusTrack, a novel one-stage paradigms tracking framework that unifies motion-semantics co-modeling through two core innovations: Inter-frame Motion Modeling (IMM) and Focus-and-Suppress Attention. The IMM module employs a temp-oral-difference siamese encoder to capture global motion patterns between adjacent frames. The Focus-and-Suppress attention that enhance the foreground semantics via motion-salient feature gating and suppress the background noise based on the temporal-aware motion context from IMM without explicit segmentation. Based on above two designs, FocusTrack enables end-to-end training with compact one-stage pipeline. Extensive experiments on prominent 3D tracking benchmarks, such as KITTI, nuScenes, and Waymo, demonstrate that the FocusTrack achieves new SOTA performance while running at a high speed with 105 FPS.
Beyond Message Passing: A Symbolic Alternative for Expressive and Interpretable Graph Learning
Feb 18, 2026Graph Neural Networks (GNNs) have become essential in high-stakes domains such as drug discovery, yet their black-box nature remains a significant barrier to trustworthiness. While self-explainable GNNs attempt to bridge this gap, they often rely on standard message-passing backbones that inherit fundamental limitations, including the 1-Weisfeiler-Lehman (1-WL) expressivity barrier and a lack of fine-grained interpretability. To address these challenges, we propose SymGraph, a symbolic framework designed to transcend these constraints. By replacing continuous message passing with discrete structural hashing and topological role-based aggregation, our architecture theoretically surpasses the 1-WL barrier, achieving superior expressiveness without the overhead of differentiable optimization. Extensive empirical evaluations demonstrate that SymGraph achieves state-of-the-art performance, outperforming existing self-explainable GNNs. Notably, SymGraph delivers 10x to 100x speedups in training time using only CPU execution. Furthermore, SymGraph generates rules with superior semantic granularity compared to existing rule-based methods, offering great potential for scientific discovery and explainable AI.
Neural Proposals, Symbolic Guarantees: Neuro-Symbolic Graph Generation with Hard Constraints
Feb 18, 2026We challenge black-box purely deep neural approaches for molecules and graph generation, which are limited in controllability and lack formal guarantees. We introduce Neuro-Symbolic Graph Generative Modeling (NSGGM), a neurosymbolic framework that reapproaches molecule generation as a scaffold and interaction learning task with symbolic assembly. An autoregressive neural model proposes scaffolds and refines interaction signals, and a CPU-efficient SMT solver constructs full graphs while enforcing chemical validity, structural rules, and user-specific constraints, yielding molecules that are correct by construction and interpretable control that pure neural methods cannot provide. NSGGM delivers strong performance on both unconstrained generation and constrained generation tasks, demonstrating that neuro-symbolic modeling can match state-of-the-art generative performance while offering explicit controllability and guarantees. To evaluate more nuanced controllability, we also introduce a Logical-Constraint Molecular Benchmark, designed to test strict hard-rule satisfaction in workflows that require explicit, interpretable specifications together with verifiable compliance.
ExpertWeaver: Unlocking the Inherent MoE in Dense LLMs with GLU Activation Patterns
Feb 17, 2026Mixture-of-Experts (MoE) effectively scales model capacity while preserving computational efficiency through sparse expert activation. However, training high-quality MoEs from scratch is prohibitively expensive. A promising alternative is to convert pretrained dense models into sparse MoEs. Existing dense-to-MoE methods fall into two categories: \textbf{dynamic structural pruning} that converts dense models into MoE architectures with moderate sparsity to balance performance and inference efficiency, and \textbf{downcycling} approaches that use pretrained dense models to initialize highly sparse MoE architectures. However, existing methods break the intrinsic activation patterns within dense models, leading to suboptimal expert construction. In this work, we argue that the Gated Linear Unit (GLU) mechanism provides a natural blueprint for dense-to-MoE conversion. We show that the fine-grained neural-wise activation patterns of GLU reveal a coarse-grained structure, uncovering an inherent MoE architecture composed of consistently activated universal neurons and dynamically activated specialized neurons. Leveraging this discovery, we introduce ExpertWeaver, a training-free framework that partitions neurons according to their activation patterns and constructs shared experts and specialized routed experts with layer-adaptive configurations. Our experiments demonstrate that ExpertWeaver significantly outperforms existing methods, both as a training-free dynamic structural pruning technique and as a downcycling strategy for superior MoE initialization.
OJBKQ: Objective-Joint Babai-Klein Quantization
Feb 09, 2026Post-training quantization (PTQ) is widely used to compress large language models without retraining. However, many existing weight-only methods rely on heuristic objectives and greedy rounding, thus leading to noticeable degradation under low-bit quantization. In this work, we introduce OJBKQ (Objective-Joint Babai-Klein Quantization with K-Best Sampling), a layer-wise PTQ method that formulates weight quantization as a joint optimization problem over activations and weights. This formulation results in a multiple-right-hand-side box-constrained integer least squares (BILS) problem in each layer, which is NP-hard. For each column of the weight matrix, we apply an extended Babai nearest-plane algorithm and an extended version of Klein's randomized Babai algorithm to find the minimum-residual Babai-Klein point, a sub-optimal solution to the BILS problem. Experimental results on large language models show that OJBKQ achieves lower perplexity at 3-4 bits compared to existing PTQ approaches, while maintaining comparable computational cost.
Dynamic Quantization Error Propagation in Encoder-Decoder ASR Quantization
Jan 05, 2026Running Automatic Speech Recognition (ASR) models on memory-constrained edge devices requires efficient compression. While layer-wise post-training quantization is effective, it suffers from error accumulation, especially in encoder-decoder architectures. Existing solutions like Quantization Error Propagation (QEP) are suboptimal for ASR due to the model's heterogeneity, processing acoustic features in the encoder while generating text in the decoder. To address this, we propose Fine-grained Alpha for Dynamic Quantization Error Propagation (FADE), which adaptively controls the trade-off between cross-layer error correction and local quantization. Experiments show that FADE significantly improves stability by reducing performance variance across runs, while simultaneously surpassing baselines in mean WER.
CompTrack: Information Bottleneck-Guided Low-Rank Dynamic Token Compression for Point Cloud Tracking
Nov 19, 20253D single object tracking (SOT) in LiDAR point clouds is a critical task in computer vision and autonomous driving. Despite great success having been achieved, the inherent sparsity of point clouds introduces a dual-redundancy challenge that limits existing trackers: (1) vast spatial redundancy from background noise impairs accuracy, and (2) informational redundancy within the foreground hinders efficiency. To tackle these issues, we propose CompTrack, a novel end-to-end framework that systematically eliminates both forms of redundancy in point clouds. First, CompTrack incorporates a Spatial Foreground Predictor (SFP) module to filter out irrelevant background noise based on information entropy, addressing spatial redundancy. Subsequently, its core is an Information Bottleneck-guided Dynamic Token Compression (IB-DTC) module that eliminates the informational redundancy within the foreground. Theoretically grounded in low-rank approximation, this module leverages an online SVD analysis to adaptively compress the redundant foreground into a compact and highly informative set of proxy tokens. Extensive experiments on KITTI, nuScenes and Waymo datasets demonstrate that CompTrack achieves top-performing tracking performance with superior efficiency, running at a real-time 90 FPS on a single RTX 3090 GPU.
Noise Projection: Closing the Prompt-Agnostic Gap Behind Text-to-Image Misalignment in Diffusion Models
Oct 16, 2025In text-to-image generation, different initial noises induce distinct denoising paths with a pretrained Stable Diffusion (SD) model. While this pattern could output diverse images, some of them may fail to align well with the prompt. Existing methods alleviate this issue either by altering the denoising dynamics or by drawing multiple noises and conducting post-selection. In this paper, we attribute the misalignment to a training-inference mismatch: during training, prompt-conditioned noises lie in a prompt-specific subset of the latent space, whereas at inference the noise is drawn from a prompt-agnostic Gaussian prior. To close this gap, we propose a noise projector that applies text-conditioned refinement to the initial noise before denoising. Conditioned on the prompt embedding, it maps the noise to a prompt-aware counterpart that better matches the distribution observed during SD training, without modifying the SD model. Our framework consists of these steps: we first sample some noises and obtain token-level feedback for their corresponding images from a vision-language model (VLM), then distill these signals into a reward model, and finally optimize the noise projector via a quasi-direct preference optimization. Our design has two benefits: (i) it requires no reference images or handcrafted priors, and (ii) it incurs small inference cost, replacing multi-sample selection with a single forward pass. Extensive experiments further show that our prompt-aware noise projection improves text-image alignment across diverse prompts.
FedEve: On Bridging the Client Drift and Period Drift for Cross-device Federated Learning
Aug 20, 2025Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model without exposing their private data. Data heterogeneity is a fundamental challenge in FL, which can result in poor convergence and performance degradation. Client drift has been recognized as one of the factors contributing to this issue resulting from the multiple local updates in FedAvg. However, in cross-device FL, a different form of drift arises due to the partial client participation, but it has not been studied well. This drift, we referred as period drift, occurs as participating clients at each communication round may exhibit distinct data distribution that deviates from that of all clients. It could be more harmful than client drift since the optimization objective shifts with every round. In this paper, we investigate the interaction between period drift and client drift, finding that period drift can have a particularly detrimental effect on cross-device FL as the degree of data heterogeneity increases. To tackle these issues, we propose a predict-observe framework and present an instantiated method, FedEve, where these two types of drift can compensate each other to mitigate their overall impact. We provide theoretical evidence that our approach can reduce the variance of model updates. Extensive experiments demonstrate that our method outperforms alternatives on non-iid data in cross-device settings.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025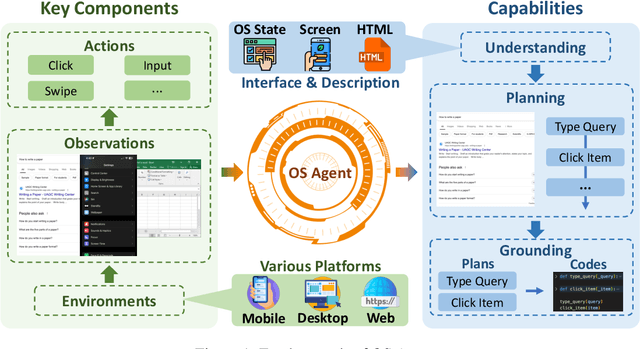
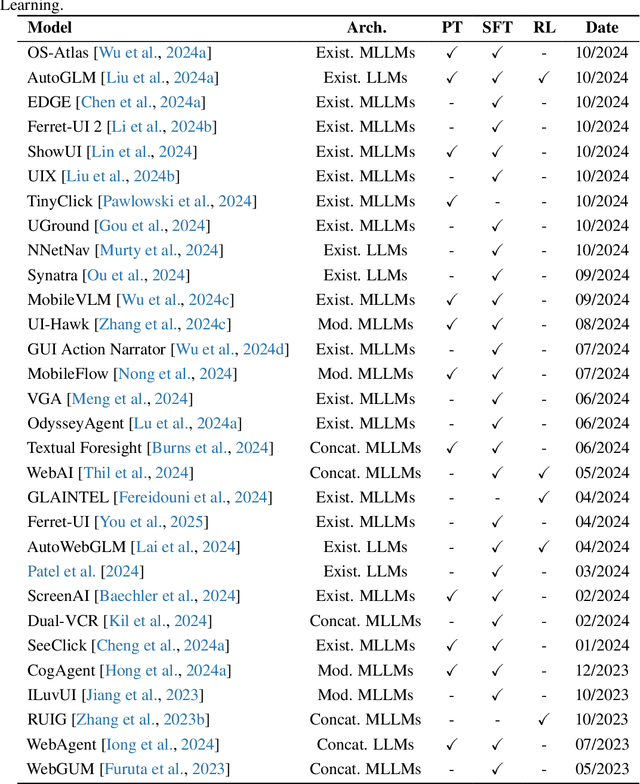
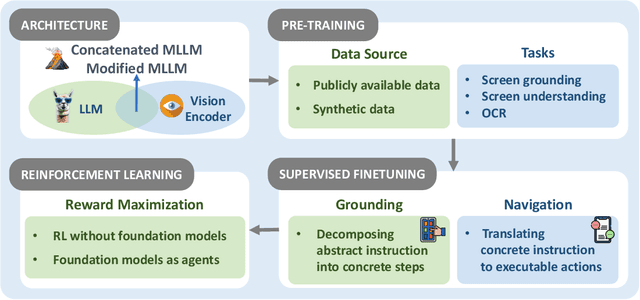
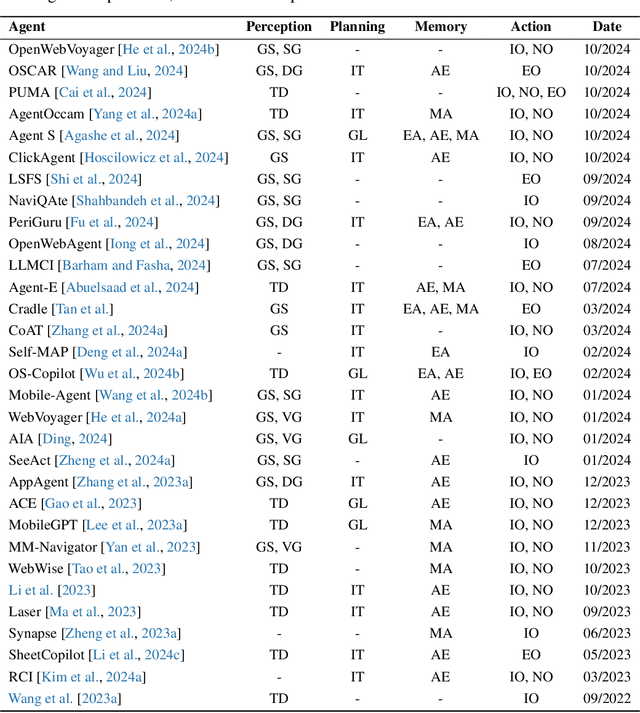
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.