 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstanceBEV: Unifying Instance and BEV Representation for Global Modeling
May 20, 2025



Occupancy Grid Maps are widely used in navigation for their ability to represent 3D space occupancy. However, existing methods that utilize multi-view cameras to construct Occupancy Networks for perception modeling suffer from cubic growth in data complexity. Adopting a Bird's-Eye View (BEV) perspective offers a more practical solution for autonomous driving, as it provides higher semantic density and mitigates complex object occlusions. Nonetheless, BEV-based approaches still require extensive engineering optimizations to enable efficient large-scale global modeling. To address this challenge, we propose InstanceBEV, the first method to introduce instance-level dimensionality reduction for BEV, enabling global modeling with transformers without relying on sparsification or acceleration operators. Different from other BEV methods, our approach directly employs transformers to aggregate global features. Compared to 3D object detection models, our method samples global feature maps into 3D space. Experiments on OpenOcc-NuScenes dataset show that InstanceBEV achieves state-of-the-art performance while maintaining a simple, efficient framework without requiring additional optimizations.
Extracting Interpretable Logic Rules from Graph Neural Networks
Mar 25, 2025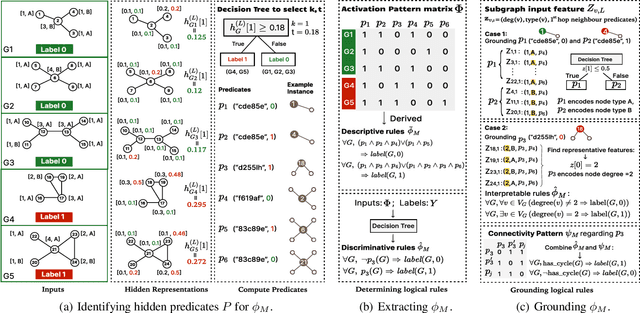

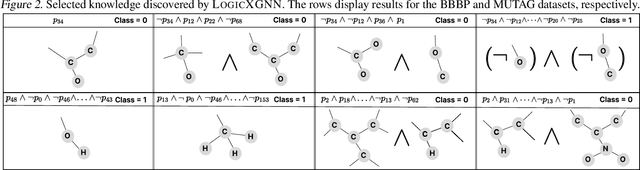
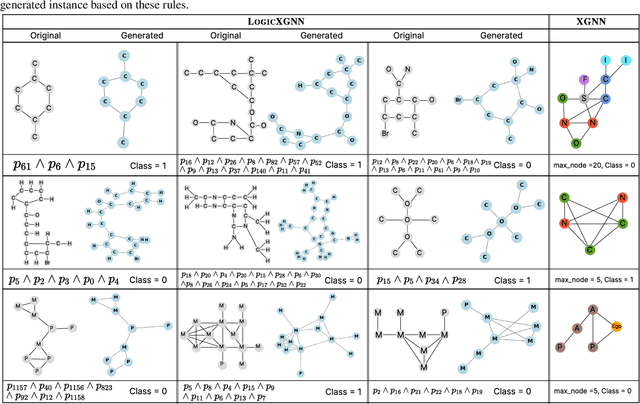
Graph neural networks (GNNs) operate over both input feature spaces and combinatorial graph structures, making it challenging to understand the rationale behind their predictions. As GNNs gain widespread popularity and demonstrate success across various domains, such as drug discovery, studying their interpretability has become a critical task. To address this, many explainability methods have been proposed, with recent efforts shifting from instance-specific explanations to global concept-based explainability. However, these approaches face several limitations, such as relying on predefined concepts and explaining only a limited set of patterns. To address this, we propose a novel framework, LOGICXGNN, for extracting interpretable logic rules from GNNs. LOGICXGNN is model-agnostic, efficient, and data-driven, eliminating the need for predefined concepts. More importantly, it can serve as a rule-based classifier and even outperform the original neural models. Its interpretability facilitates knowledge discovery, as demonstrated by its ability to extract detailed and accurate chemistry knowledge that is often overlooked by existing methods. Another key advantage of LOGICXGNN is its ability to generate new graph instances in a controlled and transparent manner, offering significant potential for applications such as drug design. We empirically demonstrate these merits through experiments on real-world datasets such as MUTAG and BBBP.
Learning Interpretable Logic Rules from Deep Vision Models
Mar 13, 2025

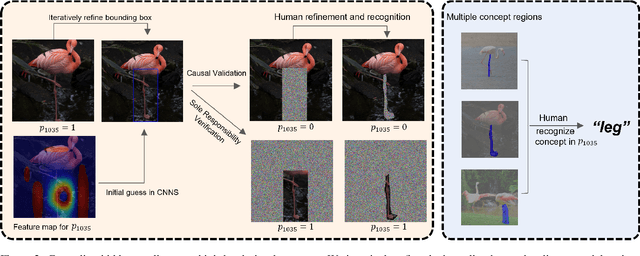

We propose a general framework called VisionLogic to extract interpretable logic rules from deep vision models, with a focus on image classification tasks. Given any deep vision model that uses a fully connected layer as the output head, VisionLogic transforms neurons in the last layer into predicates and grounds them into vision concepts using causal validation. In this way, VisionLogic can provide local explanations for single images and global explanations for specific classes in the form of logic rules. Compared to existing interpretable visualization tools such as saliency maps, VisionLogic addresses several key challenges, including the lack of causal explanations, overconfidence in visualizations, and ambiguity in interpretation. VisionLogic also facilitates the study of visual concepts encoded by predicates, particularly how they behave under perturbation -- an area that remains underexplored in the field of hidden semantics. Apart from providing better visual explanations and insights into the visual concepts learned by the model, we show that VisionLogic retains most of the neural network's discriminative power in an interpretable and transparent manner. We envision it as a bridge between complex model behavior and human-understandable explanations, providing trustworthy and actionable insights for real-world applications.
Decoding Interpretable Logic Rules from Neural Networks
Jan 14, 2025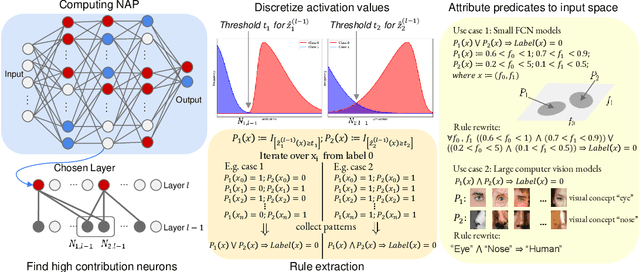
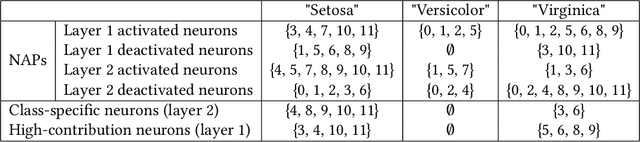
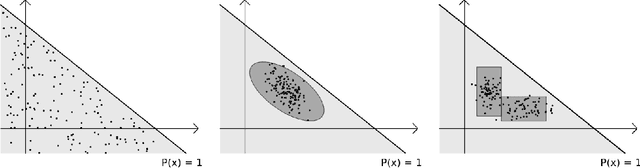
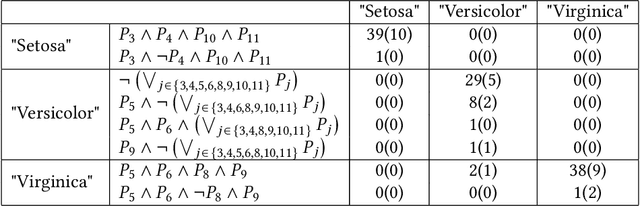
As deep neural networks continue to excel across various domains, their black-box nature has raised concerns about transparency and trust. In particular, interpretability has become increasingly essential for applications that demand high safety and knowledge rigor, such as drug discovery, autonomous driving, and genomics. However, progress in understanding even the simplest deep neural networks - such as fully connected networks - has been limited, despite their role as foundational elements in state-of-the-art models like ResNet and Transformer. In this paper, we address this challenge by introducing NeuroLogic, a novel approach for decoding interpretable logic rules from neural networks. NeuroLogic leverages neural activation patterns to capture the model's critical decision-making processes, translating them into logical rules represented by hidden predicates. Thanks to its flexible design in the grounding phase, NeuroLogic can be adapted to a wide range of neural networks. For simple fully connected neural networks, hidden predicates can be grounded in certain split patterns of original input features to derive decision-tree-like rules. For large, complex vision neural networks, NeuroLogic grounds hidden predicates into high-level visual concepts that are understandable to humans. Our empirical study demonstrates that NeuroLogic can extract global and interpretable rules from state-of-the-art models such as ResNet, a task at which existing work struggles. We believe NeuroLogic can help pave the way for understanding the black-box nature of neural networks.
Style Transfer: From Stitching to Neural Networks
Sep 01, 2024



This article compares two style transfer methods in image processing: the traditional method, which synthesizes new images by stitching together small patches from existing images, and a modern machine learning-based approach that uses a segmentation network to isolate foreground objects and apply style transfer solely to the background. The traditional method excels in creating artistic abstractions but can struggle with seamlessness, whereas the machine learning method preserves the integrity of foreground elements while enhancing the background, offering improved aesthetic quality and computational efficiency. Our study indicates that machine learning-based methods are more suited for real-world applications where detail preservation in foreground elements is essential.
Learning Minimal NAP Specifications for Neural Network Verification
Apr 06, 2024



Specifications play a crucial role in neural network verification. They define the precise input regions we aim to verify, typically represented as L-infinity norm balls. While recent research suggests using neural activation patterns (NAPs) as specifications for verifying unseen test set data, it focuses on computing the most refined NAPs, often limited to very small regions in the input space. In this paper, we study the following problem: Given a neural network, find a minimal (coarsest) NAP that is sufficient for formal verification of the network's robustness. Finding the minimal NAP specification not only expands verifiable bounds but also provides insights into which neurons contribute to the model's robustness. To address this problem, we propose several exact and approximate approaches. Our exact approaches leverage the verification tool to find minimal NAP specifications in either a deterministic or statistical manner. Whereas the approximate methods efficiently estimate minimal NAPs using adversarial examples and local gradients, without making calls to the verification tool. This allows us to inspect potential causal links between neurons and the robustness of state-of-the-art neural networks, a task for which existing verification frameworks fail to scale. Our experimental results suggest that minimal NAP specifications require much smaller fractions of neurons compared to the most refined NAP specifications, yet they can significantly expand the verifiable boundaries to several orders of magnitude larger.
Towards Socially and Morally Aware RL agent: Reward Design With LLM
Jan 23, 2024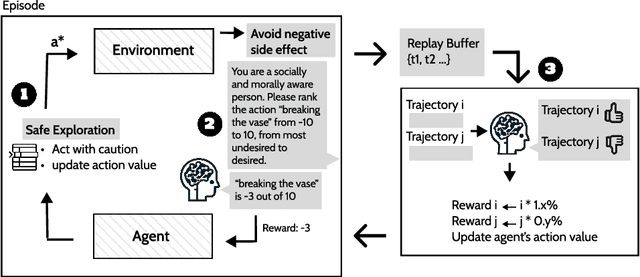

When we design and deploy an Reinforcement Learning (RL) agent, reward functions motivates agents to achieve an objective. An incorrect or incomplete specification of the objective can result in behavior that does not align with human values - failing to adhere with social and moral norms that are ambiguous and context dependent, and cause undesired outcomes such as negative side effects and exploration that is unsafe. Previous work have manually defined reward functions to avoid negative side effects, use human oversight for safe exploration, or use foundation models as planning tools. This work studies the ability of leveraging Large Language Models (LLM)' understanding of morality and social norms on safe exploration augmented RL methods. This work evaluates language model's result against human feedbacks and demonstrates language model's capability as direct reward signals.
Spatial Attention-based Distribution Integration Network for Human Pose Estimation
Nov 09, 2023In recent years, human pose estimation has made significant progress through the implementation of deep learning techniques. However, these techniques still face limitations when confronted with challenging scenarios, including occlusion, diverse appearances, variations in illumination, and overlap. To cope with such drawbacks, we present the Spatial Attention-based Distribution Integration Network (SADI-NET) to improve the accuracy of localization in such situations. Our network consists of three efficient models: the receptive fortified module (RFM), spatial fusion module (SFM), and distribution learning module (DLM). Building upon the classic HourglassNet architecture, we replace the basic block with our proposed RFM. The RFM incorporates a dilated residual block and attention mechanism to expand receptive fields while enhancing sensitivity to spatial information. In addition, the SFM incorporates multi-scale characteristics by employing both global and local attention mechanisms. Furthermore, the DLM, inspired by residual log-likelihood estimation (RLE), reconfigures a predicted heatmap using a trainable distribution weight. For the purpose of determining the efficacy of our model, we conducted extensive experiments on the MPII and LSP benchmarks. Particularly, our model obtained a remarkable $92.10\%$ percent accuracy on the MPII test dataset, demonstrating significant improvements over existing models and establishing state-of-the-art performance.
Toward Reliable Neural Specifications
Nov 14, 2022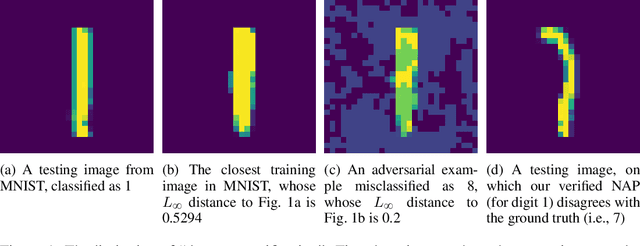

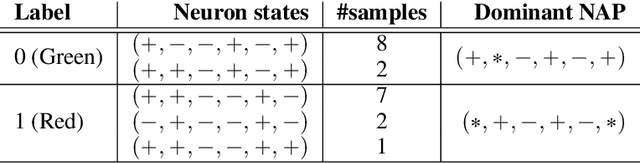
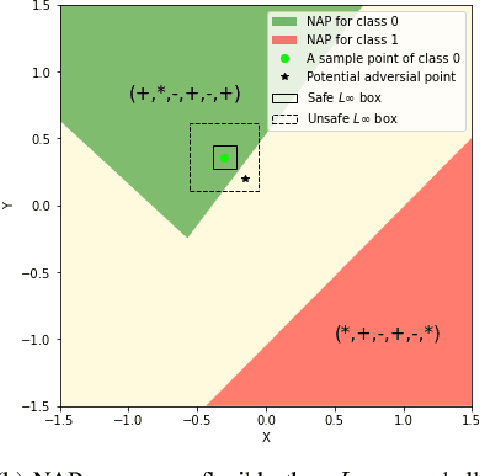
Having reliable specifications is an unavoidable challenge in achieving verifiable correctness, robustness, and interpretability of AI systems. Existing specifications for neural networks are in the paradigm of data as specification. That is, the local neighborhood centering around a reference input is considered to be correct (or robust). However, our empirical study shows that such a specification is extremely overfitted since usually no data points from the testing set lie in the certified region of the reference input, making them impractical for real-world applications. We propose a new family of specifications called neural representation as specification, which uses the intrinsic information of neural networks - neural activation patterns (NAP), rather than input data to specify the correctness and/or robustness of neural network predictions. We present a simple statistical approach to mining dominant neural activation patterns. We analyze NAPs from a statistical point of view and find that a single NAP can cover a large number of training and testing data points whereas ad hoc data-as-specification only covers the given reference data point. To show the effectiveness of discovered NAPs, we formally verify several important properties, such as various types of misclassifications will never happen for a given NAP, and there is no-ambiguity between different NAPs. We show that by using NAP, we can verify the prediction of the entire input space, while still recalling 84% of the data. Thus, we argue that using NAPs is a more reliable and extensible specification for neural network verification.